

A transzformátor modell a neurális hálózatok világában egy valódi paradigmaváltást hozott. Előtte az ismétlődő neurális hálózatok (RNN-ek) és a konvolúciós neurális hálózatok (CNN-ek) domináltak a szekvenciális adatok feldolgozásában, de ezek a modellek komoly korlátokkal küzdöttek, különösen a hosszú távú függőségek megragadásában.
A transzformátorok legfőbb újítása az önfigyelem (self-attention) mechanizmus. Ez lehetővé teszi a modell számára, hogy egy szekvencia minden elemének a többi elemhez viszonyított fontosságát dinamikusan meghatározza. Ezzel a megközelítéssel a modell képes a globális összefüggések feltérképezésére, anélkül, hogy az adatok szekvenciális feldolgozására kellene hagyatkoznia.
A hagyományos RNN-ekkel szemben, amelyek lépésről lépésre dolgozzák fel az adatokat, a transzformátorok párhuzamosan tudják kezelni a teljes szekvenciát. Ez jelentősen felgyorsítja a képzést és a következtetést, különösen nagy adathalmazok esetén.
A transzformátorok architektúrája két fő részből áll: egy kódolóból (encoder) és egy dekódolóból (decoder). Mindkét rész több rétegből áll, amelyek önfigyelmi blokkokat és előrecsatolt neurális hálózatokat tartalmaznak.
A kódoló feladata a bemeneti szekvencia reprezentációjának létrehozása, míg a dekódoló ezt a reprezentációt használja fel a kimeneti szekvencia generálásához. Ez az architektúra rendkívül rugalmas, és számos feladatra adaptálható, beleértve a gépi fordítást, a szöveggenerálást és a kérdés-válasz rendszereket.
A transzformátorok elterjedéséhez nagyban hozzájárult a BERT (Bidirectional Encoder Representations from Transformers) modell, amely a kódoló részt használja fel előre betanított nyelvi reprezentációk létrehozására. A BERT képes megragadni a szavak kontextusfüggő jelentését, ami jelentős javulást eredményezett számos természetes nyelvi feldolgozási feladatban.
A BERT sikerét követően számos más transzformátor alapú modell jelent meg, mint például a GPT (Generative Pre-trained Transformer), amely a dekódoló részt használja fel szöveggenerálásra. Ezek a modellek lenyűgöző eredményeket értek el a szövegek létrehozásában, a fordításban és a párbeszéd rendszerekben.
A szekvencia-szekvencia modellezés kihívásai és a transzformátor modell előtti megoldások (RNN, LSTM, GRU)
A szekvencia-szekvencia (sequence-to-sequence) modellezés komoly kihívások elé állította a neurális hálózatok kutatóit. E problémák közé tartozik a változó hosszúságú bemeneti és kimeneti szekvenciák kezelése, valamint a hosszú távú függőségek megragadása a szekvenciában. A feladat lényege, hogy egy bemeneti szekvenciát (például egy mondatot egy nyelven) egy másik kimeneti szekvenciára (például a mondat fordítására egy másik nyelven) képezzünk le.
A transzformátor modell megjelenése előtt az RNN (Recurrent Neural Network – Rekurrens Neurális Hálózat), az LSTM (Long Short-Term Memory – Hosszú Rövid Távú Memória) és a GRU (Gated Recurrent Unit – Kapuzott Rekurrens Egység) architektúrák voltak a legelterjedtebb megoldások. Ezek a modellek sorban dolgozzák fel a szekvencia elemeit, és egy rejtett állapotot tartanak fenn, amely tartalmazza a szekvencia eddigi feldolgozásának információit.
Az RNN-ek egyszerű felépítésűek, de képtelenek hatékonyan kezelni a hosszú távú függőségeket. Ennek oka a vanishing gradient (eltűnő gradiens) probléma, ami azt jelenti, hogy a gradiens a hálózaton keresztül visszafelé terjedve exponenciálisan csökken, így a korábbi elemek hatása elvész a későbbi elemekre.
Az LSTM és GRU modellek ezt a problémát orvosolják kapuzási mechanizmusok segítségével. Ezek a kapuk szabályozzák az információ áramlását a rejtett állapotba, így a hálózat képes szelektíven megőrizni vagy elfelejteni a korábbi információkat. Az LSTM cellák például tartalmaznak egy cell state (cella állapot) nevű komponenst, amely hosszú távon képes tárolni információkat, és a kapuk szabályozzák, hogy ez az állapot hogyan változzon.
Bár az LSTM és GRU jelentős előrelépést jelentettek az RNN-ekhez képest, még mindig számos korláttal küzdöttek. A szekvenciális feldolgozás miatt nehéz párhuzamosítani a számításokat, ami lassítja a betanítási folyamatot. Továbbá, a hosszú szekvenciák esetén a hálózat nehezen tudja megragadni a távoli elemek közötti kapcsolatokat.
A transzformátor modell azért jelentett áttörést, mert teljesen elhagyta a rekurrenciát, és helyette az önfigyelmi (self-attention) mechanizmusra épít.
Ez a mechanizmus lehetővé teszi, hogy a hálózat egyszerre vegye figyelembe a teljes bemeneti szekvenciát, és meghatározza az egyes elemek fontosságát a többi elemhez képest. Ezzel elkerülhető a szekvenciális feldolgozás okozta szűk keresztmetszet, és lehetővé válik a párhuzamosítás, ami jelentősen felgyorsítja a betanítást. Az önfigyelmi mechanizmus révén a transzformátor modell hatékonyabban képes megragadni a hosszú távú függőségeket is, mivel minden elem közvetlenül hozzáfér a szekvencia összes többi eleméhez.
Az figyelem mechanizmus (Attention Mechanism) elmélete és működése
A figyelem mechanizmus (Attention Mechanism) a transzformátor modellek kulcsfontosságú eleme, ami lehetővé teszi a modell számára, hogy a bemeneti sorozat különböző részeire fókuszáljon, amikor egy adott kimeneti elemet generálja. Ez a megközelítés jelentősen javítja a modell képességét a hosszú távú függőségek kezelésére, ami a korábbi szekvenciális modellek, mint például az RNN-ek esetében komoly kihívást jelentett.
A figyelem lényege, hogy minden egyes bemeneti szóhoz (vagy tokenhez) egy súlyt rendel, ami azt mutatja, hogy az adott szó mennyire releváns a jelenlegi kimeneti szó generálásához. Ezek a súlyok egy figyelem súlyok vektort alkotnak. Minél nagyobb egy szóhoz rendelt súly, annál nagyobb figyelmet fordít a modell arra a szóra a kimenet generálásakor.
A figyelem mechanizmus működése általában a következő lépésekből áll:
- Kulcsok (Keys), Értékek (Values) és Lekérdezések (Queries) létrehozása: A bemeneti sorozat minden egyes eleméhez a modell létrehoz egy kulcsot (K), egy értéket (V) és egy lekérdezést (Q). Ezek a vektorok a bemeneti elemek reprezentációi, amik a figyelem számításához szükségesek.
- Figyelem súlyok számítása: A lekérdezés (Q) és a kulcsok (K) segítségével a modell kiszámítja a figyelem súlyokat. Ezt általában egy score függvény segítségével teszi, ami a lekérdezés és egy-egy kulcs közötti hasonlóságot méri. A legelterjedtebb score függvény a scaled dot-product attention, ahol a lekérdezés és a kulcsok vektorait összeszorozzuk, majd egy skálázó tényezővel osztjuk.
- Súlyok normalizálása: A score függvény által generált értékeket általában egy softmax függvény segítségével normalizáljuk. Ez biztosítja, hogy a súlyok összege 1 legyen, és hogy valószínűségi eloszlást alkossanak.
- Súlyozott összegzés: A normalizált súlyokat felhasználva a modell kiszámítja az értékek (V) súlyozott összegét. Ez a súlyozott összeg képviseli a figyelmi kontextust, ami az adott kimeneti elem generálásához szükséges információkat tartalmazza.
A transzformátor modellek gyakran használnak multi-head figyelmet (Multi-Head Attention), ami azt jelenti, hogy a figyelmet párhuzamosan több alkalommal is kiszámítják, különböző tanult lineáris transzformációkkal. Ez lehetővé teszi a modell számára, hogy a bemeneti adatok különböző aspektusaira fókuszáljon, és javítja a modell általános teljesítményét.
A multi-head figyelem lényege, hogy a modellt több „szemüveggel” látja a bemeneti adatokat, ami lehetővé teszi a különböző relációk és mintázatok felismerését.
A figyelem mechanizmus nemcsak a hosszú távú függőségek kezelésében hatékony, hanem interpretálhatóbbá is teszi a modellt. A figyelem súlyok megmutatják, hogy a modell mely bemeneti szavakra fókuszált a kimenet generálásakor, ami segíthet a modell működésének megértésében és a hibák feltárásában.
Például, a gépi fordítás során a figyelem súlyok megmutathatják, hogy a forrásnyelvi mondat mely szavai felelnek meg a célnyelvi mondat adott szavának. Ez az információ rendkívül hasznos lehet a fordítás minőségének javításában és a fordítási hibák elemzésében.
A transzformátor modell architektúrája: Encoder és Decoder blokkok részletes elemzése
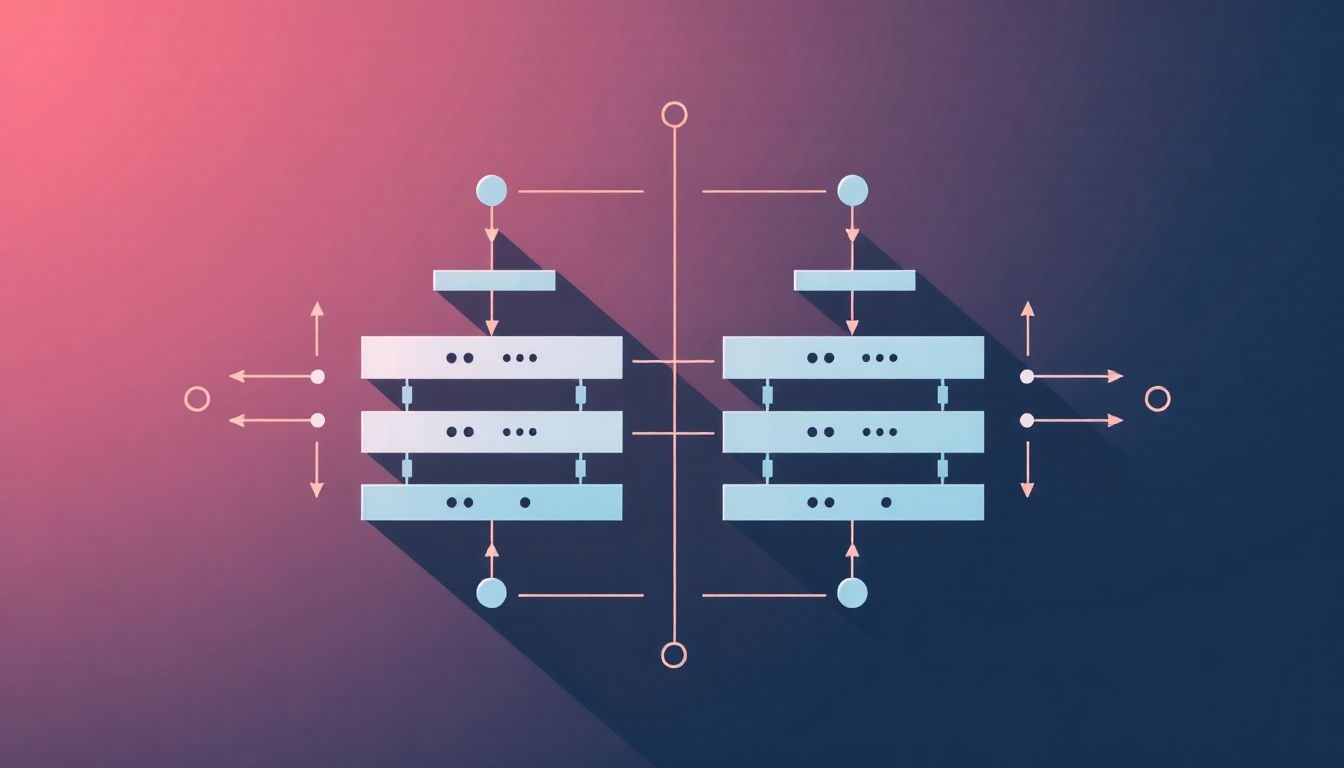
A transzformátor modell forradalmasította a természetes nyelvfeldolgozást. Lényege az encoder-decoder architektúra, amely lehetővé teszi a sorozatok közötti transzformáció hatékony kezelését. Nézzük meg részletesebben az encoder és decoder blokkok felépítését és működését.
Az encoder feladata a bemeneti sorozat (például egy mondat) reprezentációjának létrehozása. Ez a reprezentáció tartalmazza a bemenet minden elemének kontextuális információját. Az encoder több azonos blokkból áll, melyek egymásra vannak építve. Minden blokk két fő alréteget tartalmaz:
- Multi-Head Attention (Többfejes Figyelem): Ez a réteg teszi lehetővé, hogy a modell egyszerre több szempontból is figyelembe vegye a bemeneti sorozat elemeit. A figyelem mechanizmus a bemeneti elemek közötti kapcsolatokat értékeli, és súlyozza azokat a relevancia alapján. A „Multi-Head” jelző arra utal, hogy a figyelem számítás több, egymástól független „fejjel” történik, ami lehetővé teszi a modell számára, hogy a bemenet különböző aspektusaira fókuszáljon.
- Feed Forward Neural Network (Előrecsatolt Neurális Hálózat): Ez egy teljesen összekötött neurális hálózat, melyet minden pozícióra külön-külön alkalmaznak. Feladata a figyelmi réteg által generált reprezentáció tovább feldolgozása.
A blokkok között reziduális kapcsolatok (residual connections) találhatóak, melyek segítenek a mély hálózatok tanításában azáltal, hogy lehetővé teszik a gradiens akadálytalan áramlását. Minden alréteg után réteg normalizációt (layer normalization) alkalmaznak, ami stabilizálja a tanítási folyamatot.
Az encoder célja, hogy a bemeneti sorozatból egy magas szintű, kontextuális reprezentációt hozzon létre, melyet a decoder felhasznál a kimeneti sorozat generálásához.
A decoder feladata a kimeneti sorozat generálása az encoder által létrehozott reprezentáció alapján. A decoder szintén több azonos blokkból áll, melyek az encoder blokkokhoz hasonlóan egymásra vannak építve. A decoder blokkok három fő alréteget tartalmaznak:
- Masked Multi-Head Attention (Maszkolt Többfejes Figyelem): Ez a réteg a dekódolt sorozat eddigi elemeit figyeli. A maszkolás megakadályozza, hogy a modell a jövőbeli elemeket „lássa”, ami elengedhetetlen a helyes szekvenciális generáláshoz.
- Multi-Head Attention (Többfejes Figyelem): Ebben a rétegben a decoder az encoder kimenetére figyel. Ez lehetővé teszi a decoder számára, hogy a bemeneti sorozat releváns részeire fókuszáljon a kimeneti sorozat generálásakor.
- Feed Forward Neural Network (Előrecsatolt Neurális Hálózat): Hasonlóan az encoderhez, ez a réteg tovább feldolgozza a figyelmi rétegek által generált reprezentációt.
A decoder blokkok is tartalmaznak reziduális kapcsolatokat és réteg normalizációt.
A kimeneti sorozat generálása iteratívan történik. Minden lépésben a decoder a korábbi kimeneti elemek és az encoder kimenete alapján megjósolja a következő elemet. Ezt a folyamatot addig ismétlik, amíg egy speciális „end-of-sequence” (sorozat vége) token nem kerül generálásra, vagy amíg el nem érnek egy előre meghatározott maximális hosszt.
A transzformátor modell figyelmi mechanizmusa kulcsfontosságú a hatékony működéshez. Lehetővé teszi a modell számára, hogy a bemeneti és kimeneti sorozatok elemei közötti távoli függőségeket is megragadja, ami különösen fontos a hosszú sorozatok kezelésekor. A pozicionális kódolás (positional encoding) pedig információt ad a modellnek az elemek sorrendjéről, mivel a figyelem mechanizmus önmagában nem érzékeli a pozíciókat.
A transzformátor architektúra párhuzamosítható jellege jelentős előnyt jelent a szekvenciális modellekkel (pl. RNN-ekkel) szemben, mivel lehetővé teszi a bemeneti sorozat elemeinek egyidejű feldolgozását, ami jelentősen felgyorsítja a tanítási és következtetési folyamatokat.
Az Encoder blokk felépítése: Multi-Head Attention és Feed Forward hálózatok
A Transzformátor modell Encoder blokkjai egymásra épülő egységek, melyek a bemeneti szavak reprezentációit alakítják át magasabb szintű, kontextusfüggő ábrázolásokká. Egyetlen Encoder blokk két fő részből áll: a Multi-Head Attention mechanizmusból és egy Feed Forward hálózatból. Ezen két komponens egymást követően kerül alkalmazásra, és mindkettő körül egy-egy residual connection található, amit layer normalization követ.
A Multi-Head Attention a Transzformátor modell egyik legfontosabb eleme. Ez a mechanizmus lehetővé teszi a modell számára, hogy a bemeneti szavak közötti kapcsolatokat párhuzamosan, több „fejen” keresztül vizsgálja. Minden fej egy különálló attention mechanizmus, amely a bemeneti szavakat három különböző mátrixszá alakítja: Query (Q), Key (K), és Value (V). Az attention súlyok kiszámítása a Query és Key mátrixok közötti hasonlóság alapján történik (általában dot product-tal), majd ezeket a súlyokat a Value mátrixszal kombinálva kapjuk meg az adott fej kimenetét. A Multi-Head Attention lényege, hogy több különböző szempontból is megvizsgáljuk a szavak közötti kapcsolatokat, így gazdagabb és árnyaltabb reprezentációkat hozhatunk létre.
A Multi-Head Attention képessége, hogy párhuzamosan több figyelmi mechanizmust futtasson, kulcsfontosságú a Transzformátor modell hatékonysága szempontjából.
A Feed Forward hálózat egy egyszerű, pozíció-függő neurális hálózat, amely minden egyes szóra külön-külön alkalmazásra kerül. Ez a hálózat általában két lineáris rétegből áll, melyek között egy ReLU aktivációs függvény található. A Feed Forward hálózat célja, hogy tovább alakítsa a Multi-Head Attention által létrehozott reprezentációkat, és nem-linearitást vigyen a modellbe. Mivel ez a hálózat pozíció-függő, azaz minden pozícióban ugyanazt a hálózatot használjuk, de a bemenetek eltérőek, így a hálózat képes a helyi mintázatok felismerésére is.
A residual connections (vagy skip connections) kulcsfontosságúak a mély neurális hálózatok tanításában. Ezek a kapcsolatok lehetővé teszik, hogy a gradiens könnyebben terjedjen vissza a hálózaton keresztül, így elkerülhető a vanishing gradient probléma. A Transzformátor modellben minden alréteg (Multi-Head Attention és Feed Forward) körül egy-egy residual connection található. Ez azt jelenti, hogy az alréteg bemenete hozzáadódik az alréteg kimenetéhez. Ezt követően a layer normalization normalizálja az így kapott eredményt, ami stabilizálja a tanítási folyamatot és javítja a modell teljesítményét.
A layer normalization a batch normalization-höz hasonló, de a normalizálást egy adott bemenet összes elemére végzi, nem pedig egy batch összes bemenetére. Ez különösen fontos a szekvencia modellezésben, mivel a bemenetek hossza változó lehet. A layer normalization segít abban, hogy a modell kevésbé legyen érzékeny a bemenetek skálázására, és gyorsabban konvergáljon.
Összességében az Encoder blokk egy erős és rugalmas egység, amely képes a bemeneti szavak reprezentációinak hatékony átalakítására és kontextusfüggő ábrázolások létrehozására. A Multi-Head Attention mechanizmus a szavak közötti kapcsolatokat vizsgálja, míg a Feed Forward hálózat tovább alakítja ezeket a reprezentációkat. A residual connections és a layer normalization pedig stabilizálják a tanítási folyamatot és javítják a modell teljesítményét. Ezek az elemek együttesen teszik lehetővé a Transzformátor modell számára, hogy kiemelkedő eredményeket érjen el a különböző természetes nyelvi feldolgozási feladatokban.
A Decoder blokk felépítése: Masked Multi-Head Attention és Encoder-Decoder Attention
A transzformátor modell decoder blokkja kulcsfontosságú a szekvencia generálási feladatokban, mint például a gépi fordításban. Felépítése két fő figyelem mechanizmusra épül: a Masked Multi-Head Attention-re és az Encoder-Decoder Attention-re. Ezek a mechanizmusok lehetővé teszik a decoder számára, hogy figyelembe vegye a bemeneti szekvencia releváns részeit és a korábbi decoder kimeneteket a következő token generálásakor.
A Masked Multi-Head Attention a decoder blokkon belül az első figyelem réteg. Feladata, hogy a decoder által eddig generált szekvencia alapján meghatározza, mely szavak a legfontosabbak a következő szó előrejelzéséhez. A „masked” jelző arra utal, hogy a figyelem mechanizmus maszkolást használ. Ez azért szükséges, mert a decoder nem láthatja a jövőbeli szavakat a generálás során. A maszkolás megakadályozza, hogy a decoder a jövőbeli pozíciókból származó információkat felhasználja a jelenlegi pozíció előrejelzéséhez. Más szóval, minden egyes pozíció csak a korábbi és a saját pozíciójának információit használhatja fel. Ez a maszkolás biztosítja, hogy a decoder autoregresszív módon generálja a szekvenciát, azaz a következő szót az előző szavak alapján jósolja meg.
A Masked Multi-Head Attention alapvetően egy önfigyelmi mechanizmus, amely megakadályozza a jövőbeli információk felhasználását a szekvencia generálásakor.
Ezután következik a Encoder-Decoder Attention réteg. Ez a réteg összeköti a decodert az encoder kimenetével. A decoder a korábbi rétegből (Masked Multi-Head Attention) származó információkat használja fel query-ként, míg az encoder kimenete kulcs-érték párként szolgál. Ez lehetővé teszi a decoder számára, hogy figyelmet fordítson az encoder által kódolt bemeneti szekvencia releváns részeire. Például, ha a decoder egy angol mondatot fordít németre, az Encoder-Decoder Attention segítségével megtalálhatja a megfelelő német szót az angol szóhoz.
A Multi-Head Attention lényege mindkét figyelem rétegben az, hogy a figyelem folyamatot több „fejre” osztja. Minden fej egy különálló figyelem mechanizmust képvisel, amely a bemeneti információt más szemszögből vizsgálja. Ez lehetővé teszi a modell számára, hogy a különböző szavak közötti többféle kapcsolatot is megragadja. A fejek kimenetei ezután összefűzésre kerülnek, és egy lineáris transzformáción mennek keresztül, hogy egyetlen kimenetet hozzanak létre.
Mindkét figyelem réteg után add and norm rétegek következnek, amelyek a residual kapcsolatokat (residual connections) és a layer normalizációt valósítják meg. A residual kapcsolatok segítenek a gradiens eltűnésének problémájának leküzdésében, lehetővé téve a mélyebb hálózatok képzését. A layer normalizáció pedig stabilizálja a képzési folyamatot.
Végül, a decoder blokk tartalmaz egy feed-forward hálózatot, amely egy kétrétegű perceptron ReLU aktivációs függvénnyel. Ez a hálózat tovább feldolgozza a figyelem rétegek kimenetét, és segít a modellnek a komplexebb minták megtanulásában. A feed-forward hálózat után ismét egy add and norm réteg következik.
Tehát a decoder blokk egy összetett felépítésű egység, amely a Masked Multi-Head Attention, az Encoder-Decoder Attention, a residual kapcsolatok, a layer normalizáció és a feed-forward hálózat kombinációjával éri el a szekvencia generálás hatékony és pontos megvalósítását.
Pozíciókódolás (Positional Encoding): A szavak sorrendjének figyelembevétele
A transzformátor modellek egyik kulcsfontosságú eleme a pozíciókódolás, ami lehetővé teszi a modell számára, hogy figyelembe vegye a szavak sorrendjét a bemeneti mondatban. Mivel a transzformátor architektúra nem tartalmaz rekurrenciát (mint például az RNN-eknél), valamilyen módon be kell építeni az információt a szavak pozíciójáról.
A pozíciókódolás célja, hogy egyedi vektort rendeljen minden egyes pozícióhoz a mondatban. Ezeket a vektorokat hozzáadják a bemeneti szavak beágyazásaihoz (word embeddings), így a modell a bemeneti szavak jelentése mellett a pozíciójukat is figyelembe veszi.
A transzformátor modell eredeti implementációjában szinusz és koszinusz függvények kombinációját használták a pozíciókódolás létrehozására. A függvények különböző frekvenciájú hullámokat generálnak, amelyek együttesen egyedi mintázatot hoznak létre minden pozíció számára.
A pozíciókódolás lényege, hogy a modell képes legyen megkülönböztetni a mondat elején és végén lévő szavakat, valamint a köztük lévő relatív távolságokat.
A pozíciókódolás matematikai leírása a következő:
- PE(pos, 2i) = sin(pos / 100002i/dmodel)
- PE(pos, 2i+1) = cos(pos / 100002i/dmodel)
Ahol:
- pos a szó pozíciója a mondatban.
- i a dimenzió indexe.
- dmodel a beágyazások dimenziója.
Ez a módszer lehetővé teszi, hogy a modell relatív pozíciókról is tanuljon, mivel a szinusz és koszinusz függvények periodikusak. Tehát, ha két szó közötti távolság állandó, akkor a pozíciókódolásuk közötti különbség is hasonló lesz.
Multi-Head Attention: A figyelem mechanizmus párhuzamosítása
A Transzformátor modellek egyik kulcsfontosságú eleme a Multi-Head Attention mechanizmus. Ez a technika lényegében a figyelem mechanizmus párhuzamosítását jelenti, lehetővé téve a modell számára, hogy egyidejűleg különböző szempontokból, vagy „fejekből” vizsgálja meg a bemeneti adatokat.
A hagyományos figyelem mechanizmus egyetlen figyelmi súlyozást alkalmaz a bemeneti szekvenciára. Ezzel szemben a Multi-Head Attention több, független figyelem mechanizmust (fejet) használ, mindegyik saját tanult súlyozással. Minden egyes „fej” más-más reprezentációt tanul meg a bemeneti adatokról, ezáltal gazdagítva a modell által felfogott információt.
A folyamat a következőképpen zajlik:
- A bemeneti vektorokat (pl. szavak beágyazásait) lineáris transzformációkkal vetítjük különböző „fejekbe”. Ezek a transzformációk Q (Query), K (Key) és V (Value) mátrixokat hoznak létre minden fej számára.
- Minden fejben a Query, Key és Value mátrixok segítségével kiszámítjuk a figyelmi súlyokat, általában a skálázott dot-product figyelmi képlet segítségével.
- A figyelemi súlyokat alkalmazzuk a Value mátrixra, így kapjuk meg az adott fej által képviselt, figyelmi súlyokkal ellátott reprezentációt.
- Végül, az összes fej által generált reprezentációt összefűzzük (concatenate) és egy újabb lineáris transzformációval vetítjük egy egységes kimeneti térbe.
A Multi-Head Attention lehetővé teszi a modell számára, hogy különböző relációkat és függőségeket ragadjon meg a bemeneti adatokban, ami növeli a modell kifejezőerejét és teljesítményét.
Például, egy mondat gépi fordításakor az egyik fej figyelhet a szavak szinonimáira, míg egy másik a mondat nyelvtani szerkezetére. Ez a párhuzamosítás jelentősen javítja a modell hatékonyságát, mivel nem kell sorosan végrehajtani a különböző figyelmi számításokat.
A Multi-Head Attention implementálása során a fejek számát egy hiperparaméter határozza meg. Általában 8 vagy 16 fejet használnak, de ez a konkrét feladattól és adathalmaztól függően változhat.
Self-Attention: A szavak közötti kapcsolatok feltárása egy mondaton belül
A Transzformátor modellek egyik legfontosabb összetevője a self-attention mechanizmus, mely lehetővé teszi, hogy a modell egy mondaton belül a szavak közötti kapcsolatokat feltárja. Hagyományos szekvenciális modellekkel ellentétben, ahol az információ szekvenciálisan halad át a hálózaton, a self-attention párhuzamosan képes feldolgozni az összes szót, így hatékonyabban megragadva a mondat kontextusát.
A self-attention lényege, hogy minden egyes szóhoz kiszámolja a mondat többi szavának fontosságát. Ezt úgy éri el, hogy minden szót három különböző vektorrá alakít: query (kérdés), key (kulcs) és value (érték). A query vektor képviseli a szót, amire figyelünk, a key vektorok pedig a mondat többi szavát. A query és key vektorok közötti dot product (skaláris szorzat) megmutatja, hogy mennyire releváns az adott szó a többi szóhoz képest. Ezt a relevanciát egy softmax függvényen vezetjük át, ami normalizálja az értékeket, és egy figyelmi súlyt kapunk minden szóra.
Ezután ezeket a figyelmi súlyokat megszorozzuk a megfelelő value vektorokkal, és összeadjuk az eredményeket. Ez az összeadott vektor lesz a kontextusfüggő reprezentációja az adott szónak. Ez a reprezentáció magában foglalja a mondat többi szavának hatását, súlyozva a szavak közötti relevanciával.
A self-attention lehetővé teszi, hogy a modell a mondat különböző részeire összpontosítson, attól függően, hogy mely részek a legfontosabbak az adott szó szempontjából.
Például, a „Bankba mentem, hogy pénzt vegyek fel.” mondatban a „bank” szó jelentése a „pénz” szóval való kapcsolatán keresztül tisztázódik. A self-attention képes felismerni ezt a kapcsolatot, és a „bank” szó reprezentációját a „pénz” szó információjával gazdagítani.
A Transzformátor modellek gyakran több self-attention réteget (multi-head attention) használnak. Ez lehetővé teszi, hogy a modell a szavak közötti kapcsolatokat különböző szempontokból vizsgálja, ami még pontosabb és gazdagabb reprezentációkat eredményez.
A Feed Forward hálózatok szerepe a transzformátor modellben
A transzformátor modellben a Feed Forward hálózatok (FFN) kulcsszerepet játszanak az egyes encoder és decoder rétegeken belül. Ezek a hálózatok rétegenként külön-külön működnek, és az önfigyelmi mechanizmusok által előállított reprezentációkat dolgozzák fel tovább.
Minden egyes FFN tipikusan két lineáris transzformációból és egy nemlineáris aktivációs függvényből áll, például ReLU-ból. Az első lineáris réteg a bemeneti dimenziót egy nagyobb, rejtett dimenzióba vetíti, míg a második réteg visszavetíti az eredeti dimenzióba. Ez a bővítés és szűkítés lehetővé teszi a hálózat számára, hogy komplexebb összefüggéseket tanuljon meg a bemeneti adatokban.
Az FFN-ek célja, hogy a tanult reprezentációkat tovább finomítsák, és a modell számára relevánsabbá tegyék az adott feladathoz.
A Feed Forward hálózatok helyi módon alkalmazzák a transzformációkat, azaz minden pozíciót külön-külön dolgoznak fel. Ez lehetővé teszi a modell számára, hogy a szavak közötti helyi kapcsolatokat is megragadja, kiegészítve az önfigyelmi mechanizmusok által megragadott globális összefüggéseket. Az FFN-ek paraméterei rétegenként eltérőek, ami növeli a modell expresszivitását és képességét a különböző reprezentációk tanulására.
A transzformátor modell sikerének egyik kulcsa az önfigyelem és a Feed Forward hálózatok együttes használata. Az önfigyelem globális kontextust biztosít, míg az FFN-ek a helyi információk finomításával járulnak hozzá a jobb teljesítményhez.
Réteg normalizáció (Layer Normalization) és a maradvány kapcsolatok (Residual Connections)
A Transzformátor modellek kiemelkedő teljesítményének kulcsfontosságú elemei a réteg normalizáció (Layer Normalization) és a maradvány kapcsolatok (Residual Connections). Ezek a technikák segítik a hálózatot a mélyebb architektúrák hatékonyabb betanulásában és a gradient eltűnésének problémájának kezelésében.
A réteg normalizáció egy olyan normalizációs technika, amely minden egyes réteg aktivációit normalizálja a batch helyett. Ez azt jelenti, hogy minden egyes bemeneti vektorra külön-külön számítja ki az átlagot és a szórást, majd ezekkel normalizálja az aktivációkat. Ez a módszer különösen hatékony a Transzformátorokban, mivel stabilizálja a tanulási folyamatot és lehetővé teszi nagyobb tanulási sebesség használatát.
A réteg normalizáció csökkenti a belső kovariancia eltolódást, ami azt jelenti, hogy a rétegek bemeneteinek eloszlása kevésbé változik a betanulás során, ezáltal gyorsabbá és stabilabbá téve a betanulási folyamatot.
A maradvány kapcsolatok (más néven skip connections) lehetővé teszik, hogy a rétegek közvetlenül „átugorják” egy vagy több réteget. Ez azt jelenti, hogy egy adott réteg kimenete hozzáadódik egy későbbi réteg bemenetéhez. Ez a technika hatékonyan kezeli a gradient eltűnésének problémáját, mivel a gradientek közvetlenül is áramolhatnak a mélyebb rétegekbe, anélkül, hogy minden egyes rétegen át kellene haladniuk.
A maradvány kapcsolatok a következőképpen működnek: Ha egy réteg bemenete x, és a réteg függvénye F(x), akkor a réteg kimenete nem csak F(x) lesz, hanem F(x) + x. Ez az egyszerű hozzáadás lehetővé teszi, hogy a hálózat könnyebben tanuljon identitásfüggvényeket, ami kulcsfontosságú a mélyebb hálózatok hatékony betanulásához. Ezen túlmenően, a maradvány kapcsolatok elősegítik a jobb generalizációt, mivel a hálózat kevésbé valószínű, hogy túltanul a betanulási adatokon.
A transzformátor modell betanítása: Költségfüggvények és optimalizálási módszerek

A transzformátor modell betanítása során a cél, hogy a modell paraméterei optimálisak legyenek egy adott feladatra. Ehhez költségfüggvényeket használunk, amelyek számszerűsítik a modell által elkövetett hibákat. A leggyakoribb költségfüggvény a keresztentrópia (cross-entropy loss), amely különösen jól alkalmazható osztályozási feladatokra, például a gépi fordítás következő szó előrejelzésére. A keresztentrópia minimalizálása azt jelenti, hogy a modell által jósolt valószínűségi eloszlás minél közelebb kerüljön a valós eloszláshoz.
A költségfüggvény minimalizálására optimalizálási módszereket alkalmazunk. A gradient descent (gradiens ereszkedés) egy alapvető módszer, amely a költségfüggvény gradiensének irányába lépkedve keresi a minimumot. A gyakorlatban azonban gyakran használnak fejlettebb változatokat, mint például az Adam vagy a RMSProp. Ezek az algoritmusok adaptív tanulási rátákat használnak, ami azt jelenti, hogy a tanulási ráta dinamikusan változik a paraméterek és az iterációk függvényében. Ezáltal gyorsabban és hatékonyabban találják meg a költségfüggvény minimumát.
A tanulási ráta (learning rate) kulcsfontosságú hiperparaméter, amely befolyásolja a betanítás sebességét és stabilitását. Túl nagy tanulási ráta esetén a betanítás divergálhat, míg túl kicsi tanulási ráta esetén a betanítás nagyon lassú lehet.
A transzformátor modellek betanítása során gyakran alkalmaznak regularizációs technikákat is, például a dropout-ot vagy a súlycsökkentést (weight decay). Ezek a technikák segítenek megelőzni a túltanulást (overfitting), amikor a modell túl jól illeszkedik a betanító adatokhoz, de rosszul teljesít az új, ismeretlen adatokon. A dropout lényege, hogy a neurális hálózat neuronjainak egy részét véletlenszerűen kikapcsolja a betanítás során, míg a súlycsökkentés a modell súlyainak nagyságát bünteti a költségfüggvényben.
A transzformátor modell alkalmazásai a természetes nyelvfeldolgozásban (NLP)
A transzformátor modell megjelenése forradalmasította a természetes nyelvfeldolgozást (NLP). A korábbi, szekvenciális modellekkel (pl. RNN-ek, LSTM-ek) szemben, a transzformátor párhuzamosítható számításokat tesz lehetővé, ami jelentősen felgyorsítja a betanítási folyamatot és lehetővé teszi a sokkal nagyobb adathalmazokon való tanulást. Ez az architektúra az attention mechanizmusra épül, ami lehetővé teszi a modell számára, hogy a bemeneti szavak közötti kapcsolatokat globálisan értelmezze, anélkül, hogy a sorrendiségre támaszkodna.
Az NLP területén a transzformátor modellek számos alkalmazásban bizonyítottak. Ezek közül a legfontosabbak:
- Szöveg generálás: A GPT család (Generative Pre-trained Transformer) modellek képesek koherens és stilisztikailag változatos szövegek generálására, legyen szó cikkírásról, versírásról vagy akár kódgenerálásról.
- Gépi fordítás: A transzformátor alapú modellek, mint például a Google Translate, sokkal pontosabb és természetesebb fordításokat eredményeznek, mint a korábbi rendszerek.
- Szöveg osztályozás: A transzformátorok hatékonyan alkalmazhatók szövegek kategorizálására, például spam szűrésre, hangulatelemzésre vagy témakör szerinti csoportosításra.
- Kérdés-válasz rendszerek: A BERT (Bidirectional Encoder Representations from Transformers) és más hasonló modellek képesek pontosan megválaszolni kérdéseket szöveges adatok alapján, ami rendkívül hasznos információkeresési és tudásbázis alkalmazásokban.
- Névfelismerés (Named Entity Recognition): A transzformátorok jól teljesítenek a szövegben található entitások (pl. személyek, szervezetek, helyszínek) azonosításában és kategorizálásában.
A transzformátor modellek kulcsa a sokoldalúságuk. Előtanított modellek (pl. BERT, RoBERTa, GPT) finomhangolásával szinte bármilyen NLP feladatra adaptálhatók, ami jelentősen csökkenti a fejlesztési időt és erőforrásokat. A finomhangolás során a modell a konkrét feladathoz igazodik, miközben megtartja az előtanulás során szerzett általános nyelvi tudást.
A transzformátor architektúra lehetővé tette az NLP számára, hogy áttörést érjen el a szövegértés és szöveggenerálás terén, új távlatokat nyitva az automatikus szövegfeldolgozás számára.
A transzformátor modellek fejlődése folyamatos. Az újabb modellek, mint például a Transformer XL és a Reformer, a memóriahasználat optimalizálására és a hosszabb szövegek kezelésére fókuszálnak. A kutatások továbbra is arra irányulnak, hogy a transzformátorok még hatékonyabbak, erőforrás-takarékosabbak és jobban alkalmazkodjanak a különböző NLP feladatokhoz.
A figyelem mechanizmus (attention mechanism) a transzformátor modell egyik legfontosabb eleme. Lehetővé teszi a modell számára, hogy a bemeneti szavak közötti kapcsolatokat dinamikusan súlyozza, így a relevánsabb szavakra nagyobb figyelmet fordítva. Ezáltal a modell képes a szöveg kontextusának mélyebb megértésére és pontosabb előrejelzésekre.
Gépi fordítás transzformátor modellekkel: Előnyök és kihívások
A transzformátor modellek forradalmasították a gépi fordítást. Előnyük a korábbi architektúrákkal szemben, hogy képesek párhuzamosan feldolgozni a bemeneti szöveget, ami jelentősen felgyorsítja a fordítási folyamatot. Ez a hatékonyság a figyelmi mechanizmusnak (attention mechanism) köszönhető, amely lehetővé teszi a modell számára, hogy a bemeneti szöveg különböző részeire fókuszáljon a fordítás során.
A transzformátorok másik jelentős előnye a hosszú távú függőségek kezelése. Korábban a rekurrens neurális hálózatok (RNN) nehezen birkóztak meg a hosszú mondatokkal, mivel a korábbi szavak információja elhalványulhatott a feldolgozás során. A figyelmi mechanizmus lehetővé teszi, hogy a modell közvetlenül hozzáférjen a bemeneti szöveg bármely részéhez, így a hosszú távú kontextus is figyelembe vehető.
A transzformátor modellek képesek a nyelvi nüanszok pontosabb megragadására, ami jobb minőségű fordításokat eredményez.
Azonban a transzformátor modellek sem tökéletesek. Egyik kihívásuk a nagy mennyiségű adatigény. A jó minőségű fordításokhoz hatalmas, többnyelvű adathalmazokra van szükség a modell tanításához. Emellett a számítási igényük is jelentős, ami drága hardvereket és hosszú betanítási időket követel meg.
További kihívást jelent a ritka szavak kezelése. Ha egy szó nem szerepel a betanító adatokban, a modell nehezen tudja lefordítani. Erre a problémára különböző technikákat fejlesztettek ki, például a szófelbontást (subword tokenization), de a ritka szavak kezelése továbbra is aktív kutatási terület.
Szöveg generálás transzformátor modellekkel: Kreatív írás és chatbotok
A transzformátor modellek forradalmasították a szöveggenerálást, lehetővé téve kreatív írási alkalmazások és kifinomult chatbotok létrehozását. Ezek a modellek képesek koherens és stilisztikailag változatos szövegek előállítására, köszönhetően az önfigyelmi (self-attention) mechanizmusuknak, ami lehetővé teszi a szöveg különböző részeinek egyidejű figyelembevételét.
A kreatív írás területén a transzformátorok verseket, novellákat és forgatókönyveket generálhatnak. A felhasználók megadhatnak egy témát, stílust vagy néhány kulcsszót, a modell pedig ezek alapján alkotja meg a szöveget. Az eredmények gyakran meglepően eredetiek és ötletesek.
A chatbotok esetében a transzformátorok a korábbiaknál természetesebb és kontextusfüggőbb válaszokat tesznek lehetővé.
A modellek megtanulják a beszélgetés korábbi szakaszait, és ennek megfelelően alakítják a válaszaikat. Ezáltal a felhasználói élmény sokkal életszerűbb és interaktívabb lesz. A transzformátor alapú chatbotok képesek komplex kérdések megválaszolására, információk nyújtására és akár szórakoztatásra is.
A finomhangolás kulcsfontosságú a transzformátorok szöveggenerálási képességeinek maximalizálásához. Egy adott feladatra vagy stílusra betanított modell sokkal jobb eredményeket produkál, mint egy általános célú modell. Ez a finomhangolás lehetővé teszi a modellek számára, hogy specializáltabbá váljanak, és pontosabban megfeleljenek a felhasználói igényeknek.
Kérdés-válasz rendszerek transzformátor modellekkel

A transzformátor modellek forradalmasították a kérdés-válasz rendszereket (Question Answering – QA). Ezek a modellek, a hagyományos rekurrens hálózatokkal szemben, figyelmi mechanizmusokat használnak a szöveg különböző részeinek fontosságának meghatározására.
A QA rendszerekben a transzformátorok két fő bemenettel dolgoznak: a kontextussal (a szöveggel, amiből a választ kell kinyerni) és a kérdéssel. A modell célja, hogy megtalálja a kontextusban a választ adó szakaszt.
A figyelem lehetővé teszi, hogy a modell a kérdés minden szavát összehasonlítsa a kontextus minden szavával, így azonosítva a legrelevánsabb információkat. Ez különösen fontos a hosszú szövegek esetében, ahol a releváns információ távol lehet a kérdéshez képest.
A transzformátor modellek kiemelkedő teljesítménye a QA rendszerekben elsősorban a párhuzamosítási képességüknek és a hosszútávú függőségek hatékony kezelésének köszönhető.
A gyakorlatban ez azt jelenti, hogy a modell képes egyszerre feldolgozni a teljes kontextust és kérdést, így gyorsabb és pontosabb válaszokat generálva. Például, egy orvosi szövegből a betegség tüneteire vonatkozó kérdésekre adhat pontos válaszokat, vagy jogi dokumentumokból jogi hivatkozásokat kereshet.
A BERT (Bidirectional Encoder Representations from Transformers) és a RoBERTa a legnépszerűbb transzformátor alapú modellek a kérdés-válasz feladatokhoz. Ezek a modellek előre lettek tanítva hatalmas mennyiségű szövegen, ami lehetővé teszi számukra, hogy hatékonyan értsék a nyelvet és pontosan válaszoljanak a kérdésekre.
A BERT modell: Bidirectional Encoder Representations from Transformers
A BERT (Bidirectional Encoder Representations from Transformers) modell egy forradalmi előrelépést jelentett a természetes nyelvi feldolgozás (NLP) területén. A Transformer architektúrára épül, de annak egy speciális, kétirányú (bidirectional) változatát használja.
A BERT lényege, hogy a szöveget mindkét irányból, balról jobbra és jobbról balra is elemzi, ellentétben a korábbi modellekkel, amelyek csak egyirányú elemzést végeztek. Ez a kétirányú kontextus sokkal gazdagabb reprezentációt tesz lehetővé a szavak jelentésének megértéséhez.
A modell két fő feladaton lett előképzett hatalmas mennyiségű szövegen:
- Masked Language Modeling (MLM): A szavak 15%-át véletlenszerűen maszkolják (helyettesítik egy speciális [MASK] tokennel), és a modell feladata, hogy megjósolja ezeket a maszkolt szavakat a környezetük alapján.
- Next Sentence Prediction (NSP): A modell kap két mondatot, és meg kell jósolnia, hogy a második mondat a valóságban követi-e az elsőt a szövegben.
A BERT előképzése után a modell finomhangolható különböző NLP feladatokra, mint például szövegklasszifikáció, kérdés-válasz és elnevezett entitás felismerés.
A BERT architektúrája több Transformer encoder rétegből áll, amelyek egymásra vannak építve. A self-attention mechanizmus kulcsfontosságú szerepet játszik a szavak közötti kapcsolatok feltárásában. A self-attention lehetővé teszi, hogy a modell minden szó esetében figyelembe vegye a szöveg összes többi szavát, és meghatározza azok fontosságát az adott szó kontextusában.
A BERT különböző méretű változatokban érhető el, például BERT-Base és BERT-Large, amelyek a paraméterek számában különböznek. A nagyobb modellek általában jobb teljesítményt nyújtanak, de több erőforrást is igényelnek.
A GPT modell: Generative Pre-trained Transformer
A GPT (Generative Pre-trained Transformer) egy forradalmi nyelvi modell, mely a Transformer architektúrára épül. Lényegében egy hatalmas neurális hálózat, melyet arra képeztek ki, hogy szöveget generáljon.
A GPT modellek először nagyméretű szöveges adathalmazokon előképzést végeznek, így megtanulják a nyelv általános szabályait és mintáit. Ezt követően finomhangolják őket specifikusabb feladatokra, például szövegösszefoglalásra, kérdés-válasz rendszerekre vagy gépi fordításra.
A Transformer architektúra egyik kulcsfontosságú eleme az önszegesség (self-attention) mechanizmus. Ez lehetővé teszi a modell számára, hogy a szöveg különböző szavai közötti kapcsolatokat figyelembe vegye, és ezáltal a szövegkörnyezet alapján jobban értelmezze a szavakat.
A GPT modellek képesek koherens, értelmes és kreatív szövegeket generálni, szinte emberi szinten.
A GPT modellek generatív jellege azt jelenti, hogy képesek új szöveget létrehozni, nem csak a meglévőt átfogalmazni vagy elemezni. Ez számos alkalmazást tesz lehetővé, a chatbotoktól kezdve a tartalomgyártásig.
Azonban fontos megjegyezni, hogy a GPT modellek, mint minden gépi tanulási modell, nem tökéletesek. Néha hibás vagy értelmetlen szövegeket generálhatnak, vagy előítéleteket tükrözhetnek, melyeket az előképzési adatok tartalmaztak.
A GPT modellek fejlődése folyamatos, és a kutatók folyamatosan dolgoznak a pontosságuk, hatékonyságuk és etikai aspektusaik javításán.
A Transformer-XL modell: Hosszabb szekvenciák kezelése
A Transformer modellek hatékonyak, de korlátozott a szekvenciahosszuk. A Transformer-XL ezt a problémát hivatott orvosolni. A hagyományos Transformer ugyanis minden szekvenciát a nulláról dolgoz fel, ami számításigényes és nem használja fel a korábbi információkat.
A Transformer-XL bevezeti a szegmentációt és a rekurrenciát. A bemeneti szekvenciát kisebb, átfedő szegmensekre bontja. Ahelyett, hogy minden szegmenst külön-külön dolgozna fel, a Transformer-XL az előző szegmensből származó rejtett állapotokat is felhasználja a jelenlegi szegmens feldolgozásához.
Ez azt jelenti, hogy a modell „emlékszik” a korábbi szegmensekre, és a hosszabb távú függőségeket is képes megragadni.
Ez a rekurrens mechanizmus a rejtett állapotokat a szegmensek között továbbítja, lehetővé téve, hogy a modell a szegmens hosszánál sokkal hosszabb távú kontextust vegyen figyelembe. Emellett a Transformer-XL bevezeti a relatív pozíciókódolást, amely jobban kezeli a pozícióinformációkat a hosszabb szekvenciákban.
A Transformer-XL jelentősen javítja a hagyományos Transformer modellek teljesítményét a hosszabb szekvenciákon, miközben hatékonyabban használja fel a számítási erőforrásokat.
A transzformátor modell előnyei és hátrányai a korábbi architektúrákkal szemben
A transzformátor modellek jelentős előrelépést képviselnek a korábbi architektúrákkal, mint például az RNN-ekkel (Recurrent Neural Networks) és LSTM-ekkel (Long Short-Term Memory) szemben. Az egyik legfontosabb előnyük a párhuzamosítás lehetősége. Míg az RNN-ek szekvenciálisan dolgozzák fel az adatokat, a transzformátorok figyelmi mechanizmusuk révén egyszerre képesek a teljes bemeneti szekvenciát figyelembe venni. Ez jelentősen felgyorsítja a képzést és a következtetést.
Egy másik előny a hosszú távú függőségek hatékonyabb kezelése. Az RNN-eknél a távolabbi szavak közötti kapcsolatok nehezen tanulhatók meg, míg a transzformátorok figyelmi mechanizmusa lehetővé teszi, hogy a modell közvetlenül hozzáférjen a szekvencia bármely eleméhez.
Azonban a transzformátoroknak is vannak hátrányaik. Az egyik legjelentősebb a számítási igényesség. A figyelmi mechanizmus komplexitása miatt a transzformátorok több memóriát és számítási erőforrást igényelnek, különösen hosszú szekvenciák esetén.
Ezen kívül, a transzformátorok fix hosszúságú bemenetekre vannak optimalizálva. Noha léteznek módszerek a hosszabb szekvenciák kezelésére, ezek gyakran további komplexitást és számítási költségeket vonnak maguk után. A korábbi architektúrák, mint az RNN-ek, elméletileg képesek tetszőleges hosszúságú szekvenciákat feldolgozni, bár a gyakorlatban a hosszú távú függőségek problémája korlátozza ezt a képességet.
A transzformátor modell skálázhatósága és a számítási erőforrások igénye
A transzformátor modellek kiemelkedő skálázhatósága tette lehetővé a természetes nyelvi feldolgozás (NLP) területén elért jelentős áttöréseket. Minél több adattal és paraméterrel képeznek egy modellt, annál jobb teljesítményt nyújt általában.
Ugyanakkor ez a skálázhatóság jelentős számítási erőforrás igényt is von maga után. A hatalmas adathalmazokon való tanítás nagyon sok időt és erőforrást igényel, gyakran több GPU-t vagy TPU-t (Tensor Processing Unit) használva párhuzamosan.
A transzformátorok betanítása jelentős beruházást igényel a számítási infrastruktúrába.
Ráadásul, a nagyobb modellek használata magasabb követelményeket támaszt a memóriával és a számítási kapacitással szemben a következtetés során is, ami korlátozhatja a valós idejű alkalmazásokban való felhasználásukat.
Ez a számítási költség komoly akadályt jelenthet a kisebb kutatócsoportok és cégek számára, akik nem rendelkeznek a megfelelő erőforrásokkal.