


A tömb egy alapvető adatszerkezet a programozásban, amely azonos típusú elemek rendezett gyűjteménye. Ezek az elemek egymás után helyezkednek el a memóriában, ami lehetővé teszi a gyors hozzáférést bármelyik elemhez az indexe alapján. Az index általában egy egész szám, ami a tömbben elfoglalt pozíciót jelöli. A tömbök mérete általában előre meghatározott és nem változtatható meg a létrehozás után, bár léteznek dinamikus tömbök is.
A tömbökben tárolhatunk különböző adattípusokat, mint például egész számokat, lebegőpontos számokat, karaktereket vagy akár más összetett adattípusokat is. A lényeg, hogy egy tömbön belül minden elemnek azonos típusúnak kell lennie.
A tömb lényege, hogy lehetővé teszi az elemek hatékony tárolását és elérését, különösen akkor, ha az elemek sorrendje számít.
A tömbök használata elterjedt a programozásban, mivel egyszerű és hatékony megoldást kínálnak adatok tárolására és kezelésére. Számos algoritmus és adatszerkezet épül tömbökre, mint például a rendezési algoritmusok (pl. buborékrendezés, összefésüléses rendezés) vagy a keresési algoritmusok (pl. lineáris keresés, bináris keresés).
A tömbök előnye a közvetlen hozzáférés az elemekhez az indexük alapján, ami O(1) időkomplexitású művelet. Ez azt jelenti, hogy az elem eléréséhez szükséges idő nem függ a tömb méretétől. Ugyanakkor a tömbök létrehozása és inicializálása is viszonylag egyszerű és gyors.
A tömb definíciója és alapelvei
A tömb (array) egy alapvető adatszerkezet a számítástechnikában, amely azonos típusú elemek rendezett halmazát tárolja. Ezek az elemek szekvenciálisan helyezkednek el a memóriában, ami lehetővé teszi a gyors hozzáférést bármelyik elemhez annak indexe alapján. A tömb egy statikus adatszerkezet, ami azt jelenti, hogy a mérete (az elemek száma) a létrehozásakor rögzített, és később nem változtatható meg (néhány programozási nyelvben vannak dinamikus tömbök, de ezek működése eltér a klasszikus tömbtől).
A tömb elemeinek eléréséhez az indexet használjuk. Az index általában egy egész szám, amely az elem tömbön belüli pozícióját jelöli. A legtöbb programozási nyelvben (mint például C, C++, Java) az indexelés 0-tól kezdődik, tehát az első elem indexe 0, a másodiké 1 és így tovább. Más nyelvekben (pl. Pascal) az indexelés 1-től indulhat.
A tömbök használatának előnye a hatékony elemzés és a gyors hozzáférés az elemekhez. Mivel az elemek szekvenciálisan helyezkednek el a memóriában, a számítógép könnyen kiszámíthatja bármelyik elem memóriacímét az indexe alapján. Ezt a tulajdonságot gyakran kihasználják algoritmusokban, mint például a bináris keresés.
A tömbök lényege, hogy azonos típusú adatokat tárolunk egymás mellett a memóriában, lehetővé téve a gyors és közvetlen hozzáférést az elemekhez indexük alapján.
A tömbök használatának van néhány korlátja is. Mivel a méretük rögzített, nehézkes lehet új elemek hozzáadása vagy elemek törlése a tömbből. Ilyen esetekben gyakran más adatszerkezeteket, például listákat vagy dinamikus tömböket (pl. ArrayList a Java-ban) alkalmaznak.
A tömbök fontos szerepet játszanak számos algoritmusban és adatszerkezetben. Például, a rendezési algoritmusok (mint a buborékrendezés vagy a beszúrásos rendezés) gyakran használnak tömböket az adatok tárolására. A mátrixok (kétdimenziós tömbök) pedig elengedhetetlenek a lineáris algebrában és a képgrafikában.
A tömbök típusai: statikus és dinamikus tömbök
A tömbök alapvetően két fő típusba sorolhatók: statikus tömbök és dinamikus tömbök. A kettő közötti alapvető különbség a méretük kezelésében rejlik.
A statikus tömbök mérete a létrehozásuk pillanatában rögzített, és később nem változtatható meg. Ez azt jelenti, hogy amikor deklarálunk egy statikus tömböt, meg kell adnunk, hogy hány elemet fog tartalmazni. Ez a méret a program futása során állandó marad. Statikus tömbök használata hatékony lehet, ha előre tudjuk, hogy hány elemre lesz szükségünk, és ez a szám nem változik. Azonban ha a szükséges elemek száma a program futása során növekszik, akkor a statikus tömbök nem megfelelőek, mivel nem bővíthetők.
A statikus tömbök előnyei:
- Gyorsabb hozzáférés az elemekhez: A tömb mérete ismert, így a fordító optimalizálhatja a memóriához való hozzáférést.
- Memória hatékony: Pontosan annyi memóriát foglalnak, amennyire szükség van.
A statikus tömbök hátrányai:
- Rögzített méret: Nem lehet megváltoztatni a méretüket a létrehozás után.
- Memória pazarlás: Ha a tömbben kevesebb elemet tárolunk, mint a maximális mérete, a többi hely kihasználatlan marad.
Ezzel szemben a dinamikus tömbök mérete a program futása során változtatható. Amikor létrehozunk egy dinamikus tömböt, kezdetben megadhatunk egy kezdeti méretet, de a tömb képes automatikusan növelni vagy csökkenteni a méretét, ahogy több vagy kevesebb elemre van szükségünk. Ez a rugalmasság teszi a dinamikus tömböket ideális választássá olyan helyzetekben, amikor nem tudjuk előre, hogy hány elemre lesz szükségünk, vagy ha a szükséges elemek száma jelentősen változik a program futása során.
A dinamikus tömbök a statikus tömbök rugalmatlanságára kínálnak megoldást, lehetővé téve a méret dinamikus változtatását futásidőben.
A dinamikus tömbök előnyei:
- Rugalmas méret: A tömb mérete a program futása során változtatható.
- Memória hatékony: Csak annyi memóriát foglalnak, amennyire ténylegesen szükség van.
A dinamikus tömbök hátrányai:
- Lassabb hozzáférés az elemekhez: A tömb mérete dinamikusan változhat, ami befolyásolhatja a memóriához való hozzáférést.
- Teljesítmény overhead: A tömb méretének növelése vagy csökkentése időigényes lehet, különösen nagy tömbök esetén.
A dinamikus tömbök implementációja gyakran magában foglalja a memória újrafoglalását és az elemek átmásolását egy nagyobb memóriaterületre, ami időigényes művelet lehet. Ezért fontos figyelembe venni a teljesítménybeli hatásokat, amikor dinamikus tömböket használunk.
A tömbök indexelése és a memóriában való elhelyezkedés

A tömbök hatékony használatának kulcsa az indexelés. Az indexelés teszi lehetővé, hogy közvetlenül, a tömbön belüli pozíciójuk alapján érjünk el az egyes elemeket. A legtöbb programozási nyelvben, így például a C, C++, Java és JavaScript nyelvekben, a tömbök indexelése 0-tól kezdődik. Ez azt jelenti, hogy a tömb első elemének indexe 0, a második elemének indexe 1, és így tovább.
Például, ha van egy `nevek` nevű tömbünk, amelyben a `”Anna”`, `”Béla”`, és `”Cecília”` nevek szerepelnek, akkor a `nevek[0]` hivatkozás az `”Anna”` elemre, a `nevek[1]` a `”Béla”` elemre, és a `nevek[2]` a `”Cecília”` elemre fog mutatni.
A tömbök hatékonysága nagymértékben a memóriában való elhelyezkedésükből adódik. A tömb elemei folyamatos memóriaterületen helyezkednek el. Ez azt jelenti, hogy az egymást követő elemek a memória egymást követő címein találhatók. Ez a folytonos elhelyezkedés lehetővé teszi a gyors elérést bármelyik elemhez, mivel a számítógép egyszerűen kiszámíthatja az adott elem memória címét az indexe alapján.
A tömbök folytonos memóriafoglalása teszi lehetővé a konstans idejű (O(1)) hozzáférést az elemekhez az indexük alapján.
Tegyük fel, hogy a tömb első elemének címe a memóriában 1000, és minden elem 4 bájtot foglal el. Ekkor a második elem címe 1004, a harmadik elem címe 1008 lesz, és így tovább. A számítógép az indexet felhasználva egyszerűen kiszámíthatja bármelyik elem címét a következő képlet alapján: alapcím + (index * elem_mérete). Ebben az esetben az alapcím 1000, az elem_mérete 4.
A tömbök statikus méretűek is lehetnek, ami azt jelenti, hogy a tömb méretét a létrehozásakor meg kell adni, és ez a méret futásidőben nem változtatható meg (ez a helyzet a legtöbb statikusan típusos nyelvben). Vannak azonban dinamikus tömbök is (például a Python listái, vagy a Java ArrayList-je), amelyek mérete futásidőben változtatható. A dinamikus tömbök valójában a háttérben tömböket használnak, de amikor megtelnek, automatikusan létrehoznak egy nagyobb tömböt, átmásolják a régi elemeket az új tömbbe, és felszabadítják a régi tömb által elfoglalt memóriát. Ez a művelet azonban időigényes lehet.
A tömbök indexelése és memóriában való elhelyezkedése alapvetően befolyásolja a tömbök teljesítményét és felhasználhatóságát a programozásban. A hatékony indexelés és a folytonos memóriafoglalás teszi a tömböket az egyik legfontosabb és legszélesebb körben használt adatszerkezetté.
Tömbök létrehozása és inicializálása különböző programozási nyelveken (C, C++, Java, Python)
A tömbök az egyik legalapvetőbb adatszerkezetek a programozásban. Létrehozásuk és inicializálásuk nyelvenként eltérő lehet, de a cél mindenhol ugyanaz: egy adott típusú elemek tárolása egymás után, egyetlen változónév alatt.
C nyelv: A C nyelvben a tömbök deklarációja statikus, ami azt jelenti, hogy a méretüket fordítási időben meg kell adni. Például:
int szamok[5];– Ez egy 5 egész számból álló tömböt deklarál. Az elemek inicializálatlanok maradnak, tehát véletlenszerű értékek lehetnek bennük.int szamok[5] = {1, 2, 3, 4, 5};– Ez deklarál és inicializál is egy tömböt.int szamok[] = {1, 2, 3, 4, 5};– Itt a fordító automatikusan meghatározza a tömb méretét az inicializáló lista alapján.
A C nyelvben a tömb neve valójában egy pointer a tömb első elemére. Nincs beépített tömb határ ellenőrzés, ezért a programozónak kell gondoskodnia arról, hogy ne lépje túl a tömb méretét.
C++ nyelv: A C++ örökölte a C nyelv tömbkezelését, de bevezetett egy újabb módszert is, a std::array használatát, ami a Standard Template Library (STL) része. Ez a megoldás típusbiztosabb és határ ellenőrzést is kínál:
std::array<int, 5> szamok;– Egy 5 egész számból álló tömb deklarálása.std::array<int, 5> szamok = {1, 2, 3, 4, 5};– Deklarálás és inicializálás.
A std::array használata a C++-ban ajánlott a hagyományos C-stílusú tömbök helyett, mivel biztonságosabb és könnyebben használható.
Java nyelv: A Java-ban a tömbök objektumok, és dinamikusan jönnek létre a new operátorral:
int[] szamok = new int[5];– Létrehoz egy 5 elemű egész szám tömböt. Az elemek alapértelmezett értéke 0 lesz.int[] szamok = {1, 2, 3, 4, 5};– Deklarál és inicializál egy tömböt.int[] szamok = new int[]{1, 2, 3, 4, 5};– Egy másik módja a deklarálásnak és inicializálásnak.
A Java-ban beépített tömb határ ellenőrzés van, ami kivételt dob, ha a program megpróbál a tömb határain kívülre írni vagy olvasni.
Python nyelv: A Pythonban a tömböket általában listákkal (list) helyettesítik, melyek dinamikus méretűek és különböző típusú elemeket is tartalmazhatnak. A valódi tömböket a array modul biztosítja:
szamok = [1, 2, 3, 4, 5]– Ez egy lista, nem egy hagyományos értelemben vett tömb.import arrayszamok = array.array('i', [1, 2, 3, 4, 5])– Itt hozunk létre egy tömböt, ahol az ‘i’ típuskód egész számot jelöl.
A Python listák rugalmasak és könnyen használhatóak, de a array modul használata hatékonyabb lehet, ha nagyméretű, azonos típusú adatokkal kell dolgozni.
A különböző nyelvek eltérő megközelítései ellenére a tömbök alapvető szerepet töltenek be az adatok hatékony tárolásában és kezelésében.
Alapműveletek tömbökön: hozzáférés, beszúrás, törlés, frissítés
A tömbökön végezhető alapműveletek kulcsfontosságúak a hatékony programozáshoz. Négy alapvető műveletet különböztetünk meg: hozzáférés, beszúrás, törlés és frissítés.
Hozzáférés: A tömb elemeihez való hozzáférés a tömb nevének és az elem indexének megadásával történik. A legtöbb programozási nyelvben a tömbök indexelése 0-tól kezdődik. Például, ha egy tömb neve tomb, és a harmadik elemére (index 2) szeretnénk hivatkozni, akkor a tomb[2] kifejezést használjuk. A hozzáférés időkomplexitása O(1), ami azt jelenti, hogy az elem elérése konstans időben történik, függetlenül a tömb méretétől.
Beszúrás: Az elemek beszúrása tömbökbe bonyolultabb lehet, mint a hozzáférés, különösen, ha a tömb mérete rögzített. Ha a tömb nem dinamikus, azaz a mérete nem változtatható futásidőben, akkor a beszúrás általában nem lehetséges közvetlenül, hacsak nincs üres hely a tömbben. Dinamikus tömbök (mint például a listák egyes programozási nyelvekben) esetén a beszúrás lehetséges, de az időkomplexitása függ a beszúrás helyétől. Ha az elem a tömb végére kerül, akkor a beszúrás időkomplexitása O(1). Ha viszont az elem a tömb elejére vagy közepére kerül, akkor a többi elemet el kell tolni, hogy helyet csináljunk az új elemnek, ami O(n) időt vesz igénybe, ahol n a tömb mérete.
Törlés: Az elemek törlése hasonló problémákat vet fel, mint a beszúrás. Rögzített méretű tömbökben a törlés általában azt jelenti, hogy az adott elemet egy speciális értékkel (pl. null vagy -1) helyettesítjük, jelezve, hogy az a hely üres. Dinamikus tömbök esetén az elem törlése azt jelenti, hogy a többi elemet el kell tolni, hogy eltüntessük a „lyukat”. A törlés időkomplexitása a törlés helyétől függ. A tömb végéről való törlés O(1) időt vesz igénybe, míg a tömb elejéről vagy közepéről való törlés O(n) időt, mivel a többi elemet el kell tolni.
Frissítés: A tömb elemeinek frissítése (vagyis az értékük megváltoztatása) a legegyszerűbb művelet. Az elem indexének megadásával közvetlenül hozzáférhetünk az elemhez, és új értéket adhatunk neki. A frissítés időkomplexitása O(1), mivel az elem elérése és az értékének megváltoztatása konstans időben történik.
Például, tekintsük a következő tömböt: tomb = [10, 20, 30, 40, 50].
- Hozzáférés:
tomb[2]értéke 30. - Frissítés:
tomb[2] = 35után a tömb:tomb = [10, 20, 35, 40, 50]. - Beszúrás (középre, dinamikus tömb esetén): Ha a 2. indexű helyre (a 20 és 35 közé) beszúrunk egy 25-ös értéket, akkor a tömb:
tomb = [10, 20, 25, 35, 40, 50]. - Törlés (középről, dinamikus tömb esetén): Ha a 2. indexű elemet (25) töröljük, akkor a tömb:
tomb = [10, 20, 35, 40, 50].
A tömbökön végzett műveletek hatékonysága nagymértékben függ a használt adatszerkezet típusától (rögzített vs. dinamikus) és a művelet helyétől a tömbben.
A különböző programozási nyelvek eltérő implementációkat kínálnak a tömbökre, amelyek befolyásolják a fent említett műveletek teljesítményét. Például, a Python listák dinamikus tömbök, míg a C++-ban a hagyományos tömbök rögzített méretűek.
A tömbök hatékony használatához fontos megérteni ezeknek az alapműveleteknek az időkomplexitását és a különböző implementációk közötti különbségeket.
A beszúrás és törlés műveletek komplexitása tömbökben
A tömbök, mint adatszerkezetek, egymás után elhelyezkedő memóriaterületeken tárolják az elemeket. Ez az elrendezés lehetővé teszi a közvetlen elérést (random access), ami azt jelenti, hogy bármelyik elemhez konstans idő alatt (O(1)) hozzáférhetünk az indexe alapján. Azonban ez a tulajdonság bonyolulttá teszi a beszúrás és törlés műveleteket, különösen a tömb közepén.
Amikor egy új elemet szeretnénk beszúrni egy tömbbe, például a tömb elejére, akkor minden utána következő elemet eggyel jobbra kell tolnunk, hogy helyet csináljunk az új elemnek. Ez a művelet lineáris időt vesz igénybe (O(n)), ahol n a tömb mérete, mivel a legrosszabb esetben az összes elemet mozgatni kell. Ha a beszúrás a tömb végén történik, és van elegendő hely, akkor a komplexitás O(1), de ha nincs elég hely, akkor a tömb átméretezése szükséges, ami szintén O(n) időt vehet igénybe.
Hasonló a helyzet a törlésnél is. Ha egy elemet törlünk a tömbből, akkor a törölt elem utáni összes elemet eggyel balra kell tolnunk, hogy ne maradjon üres hely. Ez ismét O(n) komplexitást eredményez a legrosszabb esetben. Ha az utolsó elemet töröljük, akkor a művelet O(1), de a tömb méretének csökkentése (opcionális) ismét O(n) lehet.
A tömbökben a beszúrás és törlés műveletek komplexitása nagymértékben függ a beszúrási/törlési pozíciótól.
A gyakorlatban a tömbök használata során gyakran alkalmaznak dinamikus tömböket (pl. ArrayList a Java-ban, vagy vector a C++-ban). Ezek a tömbök automatikusan átméreteződnek, amikor megtelnek. Bár az átméretezés O(n) időt igényel, a beszúrások átlagos komplexitása amortizáltan O(1), mivel az átméretezés nem minden beszúrásnál történik meg. Azonban a törlésnél a lineáris idő komplexitás továbbra is fennáll, ha a törölt elem nem a tömb végén van.
A tömbökkel kapcsolatos műveletek komplexitásának megértése kulcsfontosságú a megfelelő adatszerkezet kiválasztásához egy adott feladathoz. Ha gyakran van szükség beszúrásra vagy törlésre a tömb közepén, akkor más adatszerkezetek, például a láncolt listák vagy a fák hatékonyabb megoldást jelenthetnek, mivel ezekben a műveletekhez nem szükséges az elemek mozgatása.
Tömbök hatékonysága és korlátai más adatszerkezetekhez képest

A tömbök kiválóan alkalmasak gyors adathozzáférésre, különösen, ha az index ismert. Ez az O(1) időkomplexitású hozzáférés az egyik legnagyobb előnyük. Azonban ez a hatékonyság ára van.
Más adatszerkezetekkel összehasonlítva, mint például a láncolt listák, a tömbök fix méretűek. Ez azt jelenti, hogy a tömb létrehozásakor előre meg kell határozni a méretét, és ha több helyre van szükség, egy új, nagyobb tömböt kell létrehozni, és átmásolni a régi adatokat. Ez a művelet időigényes lehet, különösen nagy tömbök esetén. Ezzel szemben a láncolt listák dinamikusan növelhetők és csökkenthetők.
A tömbök szekvenciális memóriaterületet foglalnak el. Ez a tulajdonság előnyös a gyors hozzáférés szempontjából, de hátrányos is lehet, mert a memória nem mindig áll rendelkezésre egybefüggően a kívánt méretben. A láncolt listák nem igényelnek egybefüggő memóriaterületet, ami rugalmasabbá teszi őket.
A tömbök beszúrási és törlési műveletei a tömb közepén vagy elején lassabbak, mint más adatszerkezeteknél, például a láncolt listáknál vagy a fáknál.
Ennek oka, hogy a beszúráshoz vagy törléshez a tömb elemeit el kell tolni, hogy helyet csináljunk az új elemnek, vagy eltüntessük a törölt elem helyét. Ez a művelet O(n) időkomplexitású, ahol n a tömb mérete. A láncolt listáknál a beszúrás és törlés egyszerűbb, mert csak a mutatókat kell átállítani.
A keresési algoritmusok szempontjából a tömbök hatékonyak lehetnek, ha rendezettek. A bináris keresés például O(log n) időkomplexitással fut rendezett tömbökön. A rendezetlen tömbökön a lineáris keresés O(n) időt vesz igénybe. Más adatszerkezetek, mint például a bináris keresőfák, szintén hatékony keresési algoritmusokat kínálnak, de a tömbök egyszerűsége sok esetben előnyös lehet.
Tömbök alkalmazási területei: algoritmusok, adatbázisok, képfeldolgozás
A tömbök, mint alapvető adatszerkezetek, rendkívül sokoldalúak és széles körben alkalmazzák őket a számítástechnikában. Nézzük meg, hogyan jelennek meg a használatuk olyan területeken, mint az algoritmusok, adatbázisok és képfeldolgozás.
Algoritmusok: A tömbök kritikus szerepet játszanak számos algoritmus implementációjában. Például, a rendezési algoritmusok, mint a buborékrendezés, beszúró rendezés, vagy a gyorsrendezés, mind tömbökön dolgoznak. Ezek az algoritmusok tömbök elemeinek átrendezésével érik el a kívánt sorrendet. A keresési algoritmusok, mint a lineáris keresés és a bináris keresés, szintén tömböket használnak az adatok megtalálásához. A bináris keresés például rendezett tömböt igényel a hatékony működéshez.
A dinamikus programozás során a részproblémák eredményeit gyakran tömbökben tárolják, hogy elkerüljék a redundáns számításokat. Ez különösen hasznos olyan problémáknál, mint a Fibonacci-számok kiszámítása vagy a leghosszabb közös részsorozat megtalálása.
A tömbök lehetővé teszik az adatok hatékony elérését és manipulálását, ami elengedhetetlen a legtöbb algoritmus hatékony működéséhez.
Adatbázisok: Bár az adatbázisok komplexebb adatszerkezeteket használnak, a tömbök alapvető építőköveként szolgálnak. Például, az indexek implementációja során a kulcsokat és a hozzájuk tartozó sorazonosítókat gyakran tömbökben tárolják. A tömbök használata lehetővé teszi a gyors keresést és hozzáférést az adatokhoz.
Az adatbázis-kezelő rendszerek (DBMS) belsőleg használhatnak tömböket a lekérdezések feldolgozásához és az adatok tárolásához. Például, a lekérdezés eredményhalmazát ideiglenesen tömbben tárolhatják, mielőtt azt visszaadnák a felhasználónak. A tömbök használata ebben az esetben lehetővé teszi az adatok hatékony rendezését, szűrését és csoportosítását.
Képfeldolgozás: A képeket digitálisan tömbökként ábrázolják, ahol minden elem (pixel) egy színt vagy szürkeárnyalatot reprezentál. A képfeldolgozási algoritmusok, mint például a szűrők (élesítés, elmosás) és az élkeresés, közvetlenül a pixelértékeket tartalmazó tömbökön dolgoznak.
Az élkereső algoritmusok, mint a Sobel-operátor vagy a Canny-élkereső, a szomszédos pixelek intenzitásának változásait vizsgálják, és a változásokat tömbök segítségével detektálják. A képtömörítési eljárások, mint a JPEG, szintén tömböket használnak a kép adatainak hatékony tárolásához. A képeket kisebb blokkokra osztják, és az egyes blokkokat transzformálják, majd kvantálják, mielőtt tömb formájában tárolják őket.
A neurális hálók, amelyeket a képfelismerésben használnak, szintén a képeket bemeneti tömbökként fogadják el. A hálózat megtanulja a kép jellemzőit a tömb elemeinek elemzésével.
Többdimenziós tömbök: mátrixok és alkalmazásaik
A többdimenziós tömbök a tömbök egy speciális fajtája, ahol az adatok nem egyetlen sorban vagy oszlopban, hanem egy rács-szerű struktúrában vannak elrendezve. A leggyakoribb példa erre a mátrix, amely egy kétdimenziós tömb. Képzeljük el egy Excel táblázatot: a sorok és oszlopok metszéspontjában találhatók az elemek.
A mátrixokat általában m x n méretűként definiáljuk, ahol m a sorok, n pedig az oszlopok számát jelöli. Minden elem a mátrixban egyedi indexekkel azonosítható, például A[i][j], ahol i a sor indexe, j pedig az oszlop indexe.
A többdimenziós tömbök (különösen a mátrixok) rengeteg alkalmazási területen jelennek meg. Néhány példa:
- Képfeldolgozás: A képeket pixelek mátrixaként ábrázolhatjuk, ahol minden pixel egy színértéket reprezentál. A képfeldolgozási algoritmusok (pl. szűrők, élkiemelés) mátrixműveleteket használnak.
- Grafika: A 3D-s objektumok pontjait és a köztük lévő kapcsolatokat mátrixokkal tároljuk. A transzformációk (forgatás, skálázás, eltolás) mátrixszorzásokkal valósíthatók meg.
- Lineáris algebra: A lineáris egyenletrendszerek megoldása, a vektorok és mátrixok transzformációja, a sajátértékek és sajátvektorok számítása mind mátrixokkal végezhető el.
- Adattárolás és -elemzés: Táblázatos adatok (pl. adatbázisokból származó adatok) mátrixként ábrázolhatók, és különböző statisztikai elemzések végezhetők rajtuk.
- Játékfejlesztés: A játéktér, a karakterek pozíciója, a kameraállás mind mátrixokkal kezelhetők.
A mátrixokkal számos művelet végezhető el:
- Összeadás és kivonás: Két mátrix összeadása vagy kivonása csak akkor lehetséges, ha azonos méretűek. Az eredmény mátrix minden eleme a megfelelő elemek összege vagy különbsége.
- Szorzás: Két mátrix összeszorzása akkor lehetséges, ha az első mátrix oszlopainak száma megegyezik a második mátrix sorainak számával. Az eredmény mátrix mérete az első mátrix sorainak és a második mátrix oszlopainak számával egyezik meg. A mátrixszorzás nem kommutatív (A * B ≠ B * A).
- Transzponálás: A mátrix transzponáltja az a mátrix, amelyben a sorok és oszlopok fel vannak cserélve.
A többdimenziós tömbök, különösen a mátrixok, nélkülözhetetlen eszközök a tudományos számításokban, a mérnöki alkalmazásokban és a szoftverfejlesztésben.
A mátrixok hatékony kezelése kritikus fontosságú a teljesítmény szempontjából. Számos optimalizációs technika létezik a mátrixműveletek felgyorsítására, például a blokkmátrix-szorzás és a párhuzamosítás.
Ritka mátrixok és azok ábrázolása tömbökkel
A ritka mátrixok olyan mátrixok, amelyekben a legtöbb elem értéke nulla. Ezek tárolása hagyományos tömbökkel rendkívül pazarló lehet, hiszen rengeteg felesleges helyet foglalunk el a memóriában a nullákkal.
A ritka mátrixok hatékony tárolására többféle módszer létezik, melyek mindegyike tömbök használatán alapul, de optimalizálja a helykihasználást. Az egyik legelterjedtebb módszer a sor-tömörített (Compressed Row Storage – CRS) formátum.
CRS esetén három tömbre van szükség:
- Értékek tömbje (values): Ebben tároljuk a nem nulla elemek értékeit, sorfolytonosan.
- Oszlopindexek tömbje (col_ind): Ebben tároljuk az értékek tömbben lévő elemek oszlopindexeit.
- Sorpointerek tömbje (row_ptr): Ebben tároljuk az egyes sorok első nem nulla elemének indexét az értékek tömbben. Az utolsó eleme a nem nulla elemek számánál eggyel nagyobb lesz.
A CRS formátum lehetővé teszi, hogy csak a nem nulla elemeket és azok pozícióját tároljuk, ezáltal jelentősen csökkentve a szükséges memória mennyiségét.
Egy másik módszer a hármas (coordinate list – COO) formátum. Ebben három tömböt használunk: egyet a sorindexeknek, egyet az oszlopindexeknek, és egyet az értékeknek. Bár egyszerűbb, mint a CRS, kevésbé hatékony a műveletek elvégzésében.
A választott ábrázolási módszer nagyban függ a mátrix tulajdonságaitól és a rajta végzett műveletektől. A hatékony ábrázolás kulcsfontosságú a ritka mátrixokkal végzett számítások során.
Asszociatív tömbök (hash táblák) – alapelvek és működés
Az asszociatív tömbök, más néven hash táblák, speciális tömbtípusok, amelyekben az elemek nem indexek, hanem kulcsok alapján érhetők el. Ezek a kulcsok általában szöveges adatok, de lehetnek más adattípusok is, a lényeg, hogy egyértelműen azonosítsák az adott értéket.
A hash táblák működésének alapja a hash függvény. Ez a függvény a kulcsot egy hash kóddá alakítja, ami egy numerikus érték. Ez a hash kód adja meg az elem tárolási helyét a memóriában.
A jó hash függvény célja, hogy minél kevesebb ütközés (collision) forduljon elő, azaz különböző kulcsok ne ugyanazt a hash kódot generálják.
Az ütközések kezelésére különböző módszerek léteznek, például a láncolás (chaining) vagy a nyílt címzés (open addressing). Láncolás esetén, ha két kulcs ugyanazt a hash kódot generálja, az elemeket egy láncolt listában tároljuk. Nyílt címzés esetén pedig új helyet keresünk az elemnek a táblában.
A hash táblák rendkívül hatékonyak az elemek keresésében, hozzáadásában és törlésében. A legjobb esetben ezek a műveletek átlagosan O(1) időkomplexitásúak, ami azt jelenti, hogy az időigény nem függ a táblában tárolt elemek számától. Azonban ütközések esetén a műveletek időigénye romolhat, a legrosszabb esetben elérheti az O(n)-t, ahol n az elemek száma.
Az asszociatív tömbök széles körben alkalmazhatók, például:
- Adatbázisokban az indexek kezelésére.
- Fordítókban a szimbólumtáblák létrehozására.
- Cache-ek implementálására.
- Konfigurációs fájlok tárolására.
A kulcs-érték párok tárolásának képessége teszi a hash táblákat rendkívül rugalmas és hatékony adatszerkezetekké.
Tömbök és pointerek kapcsolata (C/C++ példákkal)
C és C++ nyelvekben a tömbök és a pointerek szorosan összefonódnak. A tömb neve valójában egy pointer, amely a tömb első elemére mutat. Ez azt jelenti, hogy a tömb neve önmagában egy memória címet reprezentál.
Egy tömb neve konstans pointer, azaz nem módosítható.
Például, ha van egy int tomb[5]; deklarációnk, akkor a tomb az &tomb[0] címmel egyenértékű. Ez lehetővé teszi, hogy pointer aritmetikát használjunk a tömb elemeinek eléréséhez.
A C/C++-ban a *(tomb + i) és a tomb[i] teljesen egyenértékűek. Mindkettő a tömb i-edik elemének értékét adja vissza. A tomb + i a tömb i-edik elemének címét számolja ki, majd a * operátor ezt a címet dereferálja, hogy megkapja az ott tárolt értéket.
Dinamikus tömbök (new operátorral létrehozottak) esetén is hasonló a helyzet. A new int[10]; kifejezés egy int* típusú pointert ad vissza, amely a dinamikusan lefoglalt tömb első elemére mutat. Ez a pointer aztán használható a tömb elemeinek elérésére és módosítására.
Példa (C++):
int tomb[5] = {1, 2, 3, 4, 5};
int *ptr = tomb; // ptr a tomb első elemére mutat
std::cout << *ptr << std::endl; // Kiírja: 1
std::cout << ptr[2] << std::endl; // Kiírja: 3
Fontos, hogy a pointerekkel óvatosan bánjunk, mert a hibás pointer aritmetika memóriasérülésekhez és más váratlan hibákhoz vezethet.
Tömbök méretének dinamikus változtatása
A tömbök méretének dinamikus változtatása egy olyan képesség, amely nem minden programozási nyelvben alapértelmezett. A statikus tömbök, amelyek mérete a létrehozásukkor rögzített, nem teszik lehetővé a méret későbbi módosítását. Ezzel szemben a dinamikus tömbök (vagy listák, vektorok, attól függően, hogy melyik nyelvről beszélünk) lehetővé teszik, hogy a program futása közben bővítsük vagy csökkentsük a tömb méretét.
A dinamikus tömbök implementációja általában úgy történik, hogy a tömb számára lefoglalunk egy bizonyos méretű memóriaterületet. Amikor a tömb megtelik, és új elemet szeretnénk hozzáadni, a rendszer automatikusan lefoglal egy nagyobb memóriaterületet, átmásolja a régi tömb tartalmát az új területre, és hozzáadja az új elemet. Ez a folyamat, bár kényelmes, időigényes lehet, különösen nagy tömbök esetén, mivel a teljes tömböt át kell másolni.
Egyes nyelvekben (pl. Python) ez a funkcionalitás beépített, míg más nyelvekben (pl. C++) a std::vector osztály biztosítja a dinamikus tömbök kezelését. A std::vector például automatikusan kezeli a memóriafoglalást és a tömb átméretezését, amikor új elemeket adunk hozzá. Ugyanakkor fontos figyelembe venni, hogy ez a folyamat, a háttérben történő memóriafoglalás és másolás miatt, teljesítménybeli többletköltséggel járhat.
A dinamikus tömbök használata rugalmasságot biztosít az adatok tárolásában, de a memóriafoglalás és a másolás miatt időigényes lehet.
A dinamikus tömbök méretének csökkentése is lehetséges. Egyes implementációk lehetővé teszik, hogy explicit módon felszabadítsuk a felesleges memóriát, míg mások ezt automatikusan kezelik, amikor a tömb mérete jelentősen csökken. Például, ha egy 1000 elem tárolására alkalmas tömbből csak 10 elemet használunk, érdemes lehet a tömb méretét csökkenteni, hogy elkerüljük a felesleges memóriahasználatot.
A dinamikus tömbök használatakor figyelni kell a következőkre:
- A memóriafoglalás gyakorisága: a gyakori átméretezések lassíthatják a programot.
- A memóriaszivárgás elkerülése: ha a tömböt nem megfelelően kezeljük, a program feleslegesen foglalhat memóriát.
- A megfelelő adatszerkezet kiválasztása: ha a tömb mérete ritkán változik, vagy előre ismert, a statikus tömb jobb választás lehet.
A dinamikus tömbök tehát hatékony eszközt jelentenek az adatok tárolására, de használatuk körültekintést igényel a teljesítmény és a memóriahasználat szempontjából.
Tömbök rendezése: alapvető rendezési algoritmusok (buborék, beszúrásos, kiválasztásos)
A tömbök rendezése az egyik leggyakoribb feladat a programozásban. Számos algoritmus létezik erre a célra, melyek közül a legegyszerűbbek és leggyakrabban tanultak a buborékrendezés, a beszúrásos rendezés és a kiválasztásos rendezés. Ezek az algoritmusok jól szemléltetik a rendezési elvek alapjait, bár hatékonyságuk bizonyos esetekben korlátozott lehet.
Buborékrendezés (Bubble Sort):
A buborékrendezés lényege, hogy ismételten összehasonlítja a szomszédos elemeket egy tömbben, és felcseréli őket, ha rossz sorrendben vannak. Ez az eljárás addig ismétlődik, amíg a tömb rendezetté nem válik. A nagyobb elemek a tömb végére "buborékolnak" fel, innen ered az algoritmus neve. A buborékrendezés egyszerűen implementálható, de kevésbé hatékony nagy adathalmazok esetén.
Egy lehetséges implementáció:
- Végigmegyünk a tömbön.
- Összehasonlítjuk az i-edik és az i+1-edik elemet.
- Ha az i-edik elem nagyobb, mint az i+1-edik, felcseréljük őket.
- Ezt az eljárást (n-1)-szer megismételjük, ahol n a tömb mérete.
A buborékrendezés az egyik legegyszerűbb, de egyben legkevésbé hatékony rendezési algoritmus.
Beszúrásos rendezés (Insertion Sort):
A beszúrásos rendezés egy inkrementális algoritmus. A tömb elejét rendezettnek tekinti, majd sorban veszi a többi elemet, és beszúrja a megfelelő helyre a rendezett részbe. Ezt úgy éri el, hogy az aktuális elemet összehasonlítja a rendezett rész elemeivel, és addig tolja el a nagyobb elemeket, amíg helyet nem csinál az új elemnek. A beszúrásos rendezés jól teljesít kisebb adathalmazok esetén, vagy ha a tömb majdnem rendezett.
A működése:
- Az első elemet rendezettnek tekintjük.
- A második elemtől kezdve minden elemet megnézünk.
- Az aktuális elemet összehasonlítjuk a rendezett rész elemeivel, jobbról balra haladva.
- Ha az aktuális elem kisebb, mint egy elem a rendezett részben, eltoljuk a nagyobb elemet egy pozícióval jobbra.
- Ezt addig folytatjuk, amíg helyet nem találunk az aktuális elemnek, majd beszúrjuk oda.
Kiválasztásos rendezés (Selection Sort):
A kiválasztásos rendezés megkeresi a legkisebb elemet a tömbben, és felcseréli az első elemmel. Ezután megkeresi a második legkisebb elemet, és felcseréli a második elemmel, és így tovább. Az algoritmus minden lépésben kiválasztja a maradék rész legkisebb elemét, és a megfelelő helyre teszi. A kiválasztásos rendezés nem hatékony nagy adathalmazok esetén, de kevesebb cserét hajt végre, mint a buborékrendezés.
Az algoritmus lépései:
- Megkeressük a legkisebb elemet a tömbben.
- Felcseréljük a legkisebb elemet az első elemmel.
- Megkeressük a második legkisebb elemet a tömb maradék részében.
- Felcseréljük a második legkisebb elemet a második elemmel.
- Ezt az eljárást folytatjuk, amíg a tömb rendezetté nem válik.
Ezek az algoritmusok a rendezési elvek alapjait mutatják be. Bár egyszerűek és könnyen érthetőek, nagy adathalmazok esetén léteznek hatékonyabb rendezési algoritmusok, mint például a mergesort vagy a quicksort.
Tömbökben való keresés: lineáris és bináris keresés
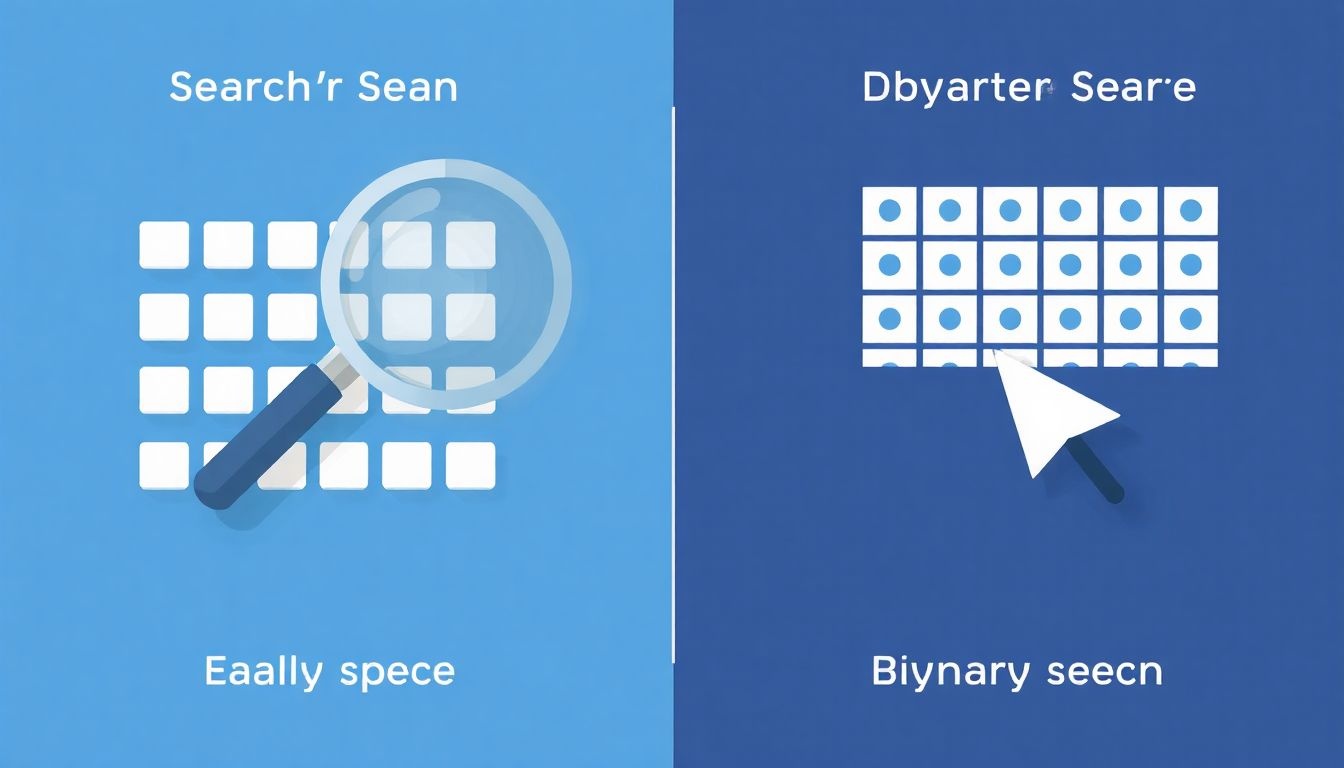
A tömbökben való keresés alapvető művelet, amely lehetővé teszi, hogy egy adott értéket (más néven kulcsot) megtaláljunk a tömb elemei között. Két elterjedt keresési algoritmus létezik: a lineáris keresés és a bináris keresés.
A lineáris keresés a legegyszerűbb módszer. Sorban végigmegy a tömb elemein, és minden elemet összehasonlít a keresett kulccsal. Ha egyezést talál, visszaadja az elem indexét (vagy magát az elemet), különben jelzi, hogy az elem nem található. Előnye, hogy bármilyen tömbre alkalmazható, rendezetlenre is. Hátránya, hogy a legrosszabb esetben (amikor a keresett elem az utolsó, vagy egyáltalán nem szerepel a tömbben) a teljes tömböt végig kell vizsgálnia, ami nagyméretű tömbök esetén időigényes lehet. A lineáris keresés időkomplexitása O(n), ahol n a tömb mérete.
A bináris keresés sokkal hatékonyabb, de csak rendezett tömbökön alkalmazható. Lényege, hogy a tömböt folyamatosan felezi, amíg meg nem találja a keresett elemet, vagy amíg üres nem lesz a keresési intervallum. Először a tömb középső elemét hasonlítja össze a kulccsal. Ha a kulcs kisebb, mint a középső elem, akkor a keresést a tömb bal felében folytatja. Ha nagyobb, akkor a jobb felében. Ezt a folyamatot ismétli, amíg meg nem találja a kulcsot, vagy amíg a keresési intervallum ki nem ürül. A bináris keresés időkomplexitása O(log n), ami azt jelenti, hogy sokkal gyorsabb a lineáris keresésnél nagyméretű tömbök esetén.
A bináris keresés hatékonysága a rendezett adatokban rejlő lehetőségek kihasználásán alapul.
A két keresési módszer közötti választás a tömb méretétől és rendezettségétől függ. Kis méretű tömbök esetén a lineáris keresés elegendő lehet, míg nagyméretű, rendezett tömbök esetén a bináris keresés a preferált megoldás.
Tömbökkel kapcsolatos gyakori hibák és azok elkerülése
Tömbök használata során gyakran előfordulnak hibák, melyek elkerülése kulcsfontosságú a hatékony programozáshoz. Az egyik leggyakoribb hiba a tömb indexének túllépése, amikor a program egy olyan elemhez próbál hozzáférni, ami nem létezik a tömbben. Ez futásidejű hibát okozhat.
Egy másik gyakori probléma a nem inicializált tömbök használata. Ha egy tömböt deklarálunk, de nem adunk neki kezdőértéket, az értékei definiálatlanok lehetnek, ami váratlan eredményekhez vezethet.
A tömbök méretének helytelen kezelése is problémát okozhat. Ha egy tömb túl kicsi ahhoz, hogy az összes adatot tárolja, akkor adatvesztés léphet fel. Ha viszont túl nagy, akkor feleslegesen foglalunk memóriát.
A tömbök indexe általában 0-tól indul, ezt sosem szabad elfelejteni!
A tömbök másolása is trükkös lehet. A sekély másolat (shallow copy) csak a tömb memóriacímét másolja, így ha az egyik tömbben módosítjuk az adatokat, az a másikban is megváltozik. A mély másolat (deep copy) viszont az összes elemet átmásolja, így a két tömb független lesz egymástól.