


A rekord az adatfeldolgozás egyik alapvető építőköve. Lényegében egy egyedi adategyüttes, ami egy adott entitásról vagy objektumról tartalmaz információkat. Gondoljunk például egy személyre: a rekord tartalmazhatja a nevét, címét, telefonszámát és egyéb releváns adatait.
A rekordok strukturált módon szerveződnek, jellemzően mezőkből állnak. Minden mező egy adott adattípust tárol, például szöveget, számot vagy dátumot. Ez a strukturáltság teszi lehetővé az adatok hatékony tárolását, lekérdezését és feldolgozását.
A rekordok kulcsfontosságú szerepet játszanak az adatbázisokban, fájlrendszerekben és más adattárolási rendszerekben, mivel lehetővé teszik az adatok logikus és rendezett tárolását.
A rekordok használata nélkülözhetetlen a modern adatfeldolgozásban. Képzeljük el, hogy egy webáruházban szeretnénk keresni egy terméket. A termék adatbázisban minden termék egy rekordként van tárolva, a rekord mezői pedig a termék nevét, árát, leírását és egyéb jellemzőit tartalmazzák. A keresőmotor a rekordok között keresve találja meg a megfelelő terméket.
A rekordok nem csak adatbázisokban használatosak. Például egy táblázatkezelő programban is rekordoknak nevezzük a táblázat sorait, amelyek egy-egy adategyüttest reprezentálnak.
A rekordok jelentősége abban rejlik, hogy lehetővé teszik az adatok szervezett és hatékony kezelését, ami elengedhetetlen a modern információs rendszerek működéséhez.
A rekord definíciója és alapvető jellemzői
A rekord az adatfeldolgozás egyik alapvető építőköve. Lényegében egy összetett adattípus, amely különböző, egymással valamilyen kapcsolatban álló adatokat foglal magába. Gondoljunk rá úgy, mint egy táblázat egy sorára, ahol minden oszlop egy-egy információt (mezőt) tárol az adott sorhoz (rekordhoz) kapcsolódóan.
Egy rekord mezőkből (angolul: fields) áll, melyek mindegyike egy-egy konkrét adatot tárol. Ezek a mezők különböző adattípusúak lehetnek, például szöveg (string), szám (integer, float), dátum, vagy akár logikai érték (boolean). Például, egy „Vásárló” rekord tartalmazhat mezőket, mint „Vezetéknév” (szöveg), „Keresztnév” (szöveg), „Életkor” (szám), és „Hírlevélre feliratkozott” (logikai érték).
A rekordok szervezett tárolást tesznek lehetővé, és megkönnyítik az adatok elérését és feldolgozását. A struktúrált jellegük miatt az adatbázisok és más adatkezelő rendszerek hatékonyan tudják kezelni a nagymennyiségű adatot. Egy adatbázisban például a táblák rekordokból állnak, ahol minden rekord egy egyedi entitást (pl. egy terméket, egy felhasználót) reprezentál.
A rekordok kulcsfontosságúak az adatfeldolgozásban, mert lehetővé teszik a kapcsolódó adatok logikai egységként való kezelését.
A rekordok szerepe az adatfeldolgozásban sokrétű:
- Adattárolás: A rekordok lehetővé teszik az adatok strukturált és szervezett tárolását.
- Adatkezelés: Megkönnyítik az adatok elérését, módosítását és törlését.
- Adatfeldolgozás: Lehetővé teszik az adatokkal végzett műveleteket, mint például a rendezés, szűrés és csoportosítás.
- Adatcsere: A rekordok használata szabványosítja az adatok formátumát, ami megkönnyíti az adatok cseréjét különböző rendszerek között.
A rekordok használata az adatfeldolgozásban számos előnnyel jár:
- Hatékonyság: A strukturált tárolásnak köszönhetően az adatok gyorsabban elérhetők és feldolgozhatók.
- Rendszeresség: Az adatok egységes formátumban kerülnek tárolásra, ami csökkenti a hibák lehetőségét.
- Skálázhatóság: A rekordok lehetővé teszik a nagy mennyiségű adat hatékony kezelését.
- Karbantarthatóság: A strukturált adatok könnyebben karbantarthatók és módosíthatók.
Például, egy könyvtári rendszerben a „Könyv” rekord tartalmazhat mezőket, mint „Cím”, „Szerző”, „ISBN szám”, „Kiadási év” és „Kölcsönözhető”. Ezek az adatok együttesen írják le az adott könyvet, és a rekord segítségével könnyen kereshetővé és kezelhetővé válnak a könyvtár adatbázisában.
A rekordok szerepe tehát megkerülhetetlen az adatfeldolgozásban, hiszen nélkülük az adatok kezelése kaotikus és nehézkes lenne. A rekordok biztosítják az adatok strukturált, szervezett és hatékony tárolását és feldolgozását, ami elengedhetetlen a modern információs rendszerek működéséhez.
A rekordok felépítése: mezők, adattípusok és kapcsolatok
A rekordok az adatfeldolgozás alapvető építőkövei, amelyek strukturáltan tárolják az információkat. Egy rekord lényegében egy adategyüttes, amely egyetlen entitást vagy objektumot ír le. A rekordok felépítése kulcsfontosságú a hatékony adatkezeléshez.
A rekordok elsődleges alkotóelemei a mezők (vagy attribútumok). Minden mező egy adott jellemzőt vagy tulajdonságot tárol az adott entitással kapcsolatban. Például, ha egy „személy” rekordot hozunk létre, a mezők lehetnek: név, életkor, cím, telefonszám stb. Minden mező egyedi azonosítóval rendelkezik, ami lehetővé teszi az adatok könnyű elérését és kezelését.
A mezők adattípusa határozza meg, hogy milyen típusú adatot tárolhat az adott mező. A leggyakoribb adattípusok a következők:
- Szöveg (string): Betűk, számok és speciális karakterek kombinációját tárolja.
- Szám (integer, float): Egész számokat vagy tizedes törteket tárol.
- Dátum (date): Dátumértékeket tárol.
- Logikai (boolean): Igaz vagy hamis értékeket tárol.
A megfelelő adattípus kiválasztása elengedhetetlen az adatok integritásának megőrzéséhez és a hatékony adatfeldolgozáshoz. Például, egy telefonszámot szövegként kell tárolni, még akkor is, ha csak számokat tartalmaz, mert a telefonszámokkal általában nem végzünk matematikai műveleteket.
A rekordok nem feltétlenül állnak magukban. Gyakran kapcsolatok vannak közöttük. Ezek a kapcsolatok az adatbázisok alapját képezik, és lehetővé teszik a komplex információk hatékony tárolását és kezelését.
A leggyakoribb kapcsolat típusok a következők:
- Egy-egy (one-to-one): Egy rekord egy másik rekordhoz kapcsolódik. Például, egy személyhez egyetlen útlevél tartozhat.
- Egy-több (one-to-many): Egy rekord több másik rekordhoz kapcsolódik. Például, egy vevőnek több rendelése lehet.
- Több-egy (many-to-one): Több rekord egyetlen rekordhoz kapcsolódik. Például, több rendelés tartozhat egy vevőhöz.
- Több-több (many-to-many): Több rekord több másik rekordhoz kapcsolódik. Például, egy terméket több rendelésben is megrendelhetnek, és egy rendelésben több termék is lehet.
A kapcsolatok létrehozásához általában idegen kulcsokat (foreign keys) használunk. Az idegen kulcs egy mező egy táblában, amely egy másik tábla elsődleges kulcsára (primary key) hivatkozik. Ez a hivatkozás biztosítja az adatok konzisztenciáját és lehetővé teszi a rekordok közötti kapcsolatok lekérdezését.
A rekordok felépítése tehát a mezők, az adattípusok és a kapcsolatok gondos megtervezését igényli. A helyesen tervezett rekordstruktúra kulcsfontosságú az adatbázis hatékonyságához, megbízhatóságához és a benne tárolt információk könnyű elérhetőségéhez.
A rekordok helyes felépítése és a köztük lévő kapcsolatok definiálása alapvetően befolyásolja az adatbázis teljesítményét és a belőle kinyerhető információk minőségét.
Például, egy könyvtári rendszerben a „könyv” rekord tartalmazhat olyan mezőket, mint a cím, szerző, ISBN, kiadási év, és példányszám. A „kölcsönzés” rekord tartalmazhat mezőket, mint a könyv azonosítója (idegen kulcs, amely a könyv rekordjára mutat), a felhasználó azonosítója (idegen kulcs, amely a felhasználó rekordjára mutat), a kölcsönzés dátuma és a visszavitel dátuma. Ezek a rekordok egy „egy-több” kapcsolattal rendelkeznek a felhasználók és a kölcsönzések között, mivel egy felhasználó több könyvet is kikölcsönözhet.
A rekordok és azok kapcsolatai az adatbázis-tervezés alapját képezik, és nélkülözhetetlenek az adatfeldolgozás során.
Rekordok típusai: fix és változó hosszúságú rekordok
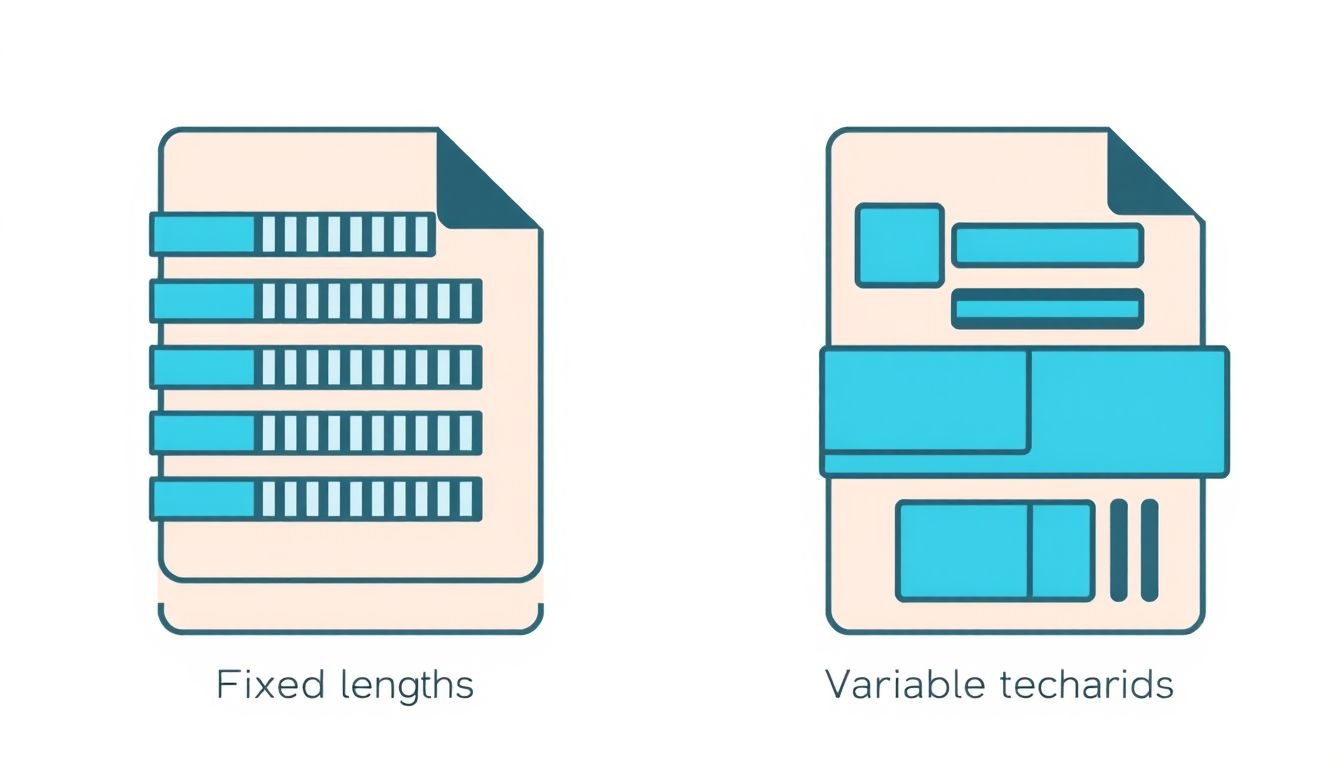
A rekordok az adatfeldolgozás alapvető építőkövei, amelyek strukturált módon tárolják az adatokat. A rekordokon belül található mezők (vagy attribútumok) különböző típusú információkat tartalmazhatnak, például szöveget, számokat vagy dátumokat. A rekordok hossza alapvetően kétféle lehet: fix hosszúságú és változó hosszúságú.
A fix hosszúságú rekordok esetében minden rekord azonos méretű, függetlenül a benne tárolt adatoktól. Ez azt jelenti, hogy minden mező előre meghatározott mennyiségű helyet foglal el a memóriában vagy a tárolóeszközön. Például, ha egy név mező maximum 20 karaktert tárolhat, akkor minden rekordban 20 karakterhely van fenntartva a név számára, még akkor is, ha a tényleges név csak 10 karakter hosszú. A fix hosszúságú rekordok előnye a gyors hozzáférés és a könnyű kezelhetőség, mivel a rekordok helye a fájlban vagy adatbázisban egyszerűen kiszámítható. Ugyanakkor a helykihasználás nem optimális, ha a legtöbb mezőben kevesebb adatot tárolunk a maximálisan engedélyezettnél.
A fix hosszúságú rekordok egyszerűsítik az adatbázisok és fájlok kezelését, de pazarlóak lehetnek a tárhely szempontjából.
Ezzel szemben a változó hosszúságú rekordok hossza változó, azaz az egyes rekordok eltérő méretűek lehetnek. Ez lehetővé teszi, hogy a rekordok csak annyi helyet foglaljanak el, amennyire a bennük tárolt adatokhoz szükség van. A változó hosszúságú rekordok alkalmazásához általában valamilyen határolójelet (delimiter) vagy hosszúságjelzőt használnak. A határolójel a mezők végét jelzi, míg a hosszúságjelző a mező vagy a teljes rekord hosszát adja meg. A változó hosszúságú rekordok előnye a jobb helykihasználás, mivel nem pazarolnak felesleges helyet. Azonban a kezelésük bonyolultabb, mivel a rekordok helye nem számítható ki előre, hanem minden rekordot be kell olvasni a hosszának megállapításához.
A két típus közötti választás az alkalmazás igényeitől függ. Ha a gyors hozzáférés és a könnyű kezelhetőség a prioritás, akkor a fix hosszúságú rekordok a megfelelő választás. Ha a helykihasználás a legfontosabb szempont, akkor a változó hosszúságú rekordok előnyösebbek.
A gyakorlatban gyakran kombinálják a két megközelítést. Például egy rekord tartalmazhat fix hosszúságú mezőket (pl. azonosítókat) és változó hosszúságú mezőket (pl. szöveges leírásokat). Ez lehetővé teszi a kompromisszumot a helykihasználás és a kezelhetőség között.
A rekordok szerepe az adatbázisokban
A rekord az adatbázisok egyik alapvető építőköve. Lényegében egy sor egy táblázatban, amely egy adott entitás vagy objektum összetartozó tulajdonságait reprezentálja. Gondoljunk egy ügyfélnyilvántartásra: minden egyes ügyfél adatai – név, cím, telefonszám, e-mail cím – egyetlen rekordban tárolódnak.
A rekordok kulcsfontosságúak az adatok strukturált tárolásában. Ahelyett, hogy az információk rendezetlenül, például egy szöveges fájlban lennének tárolva, a rekordok lehetővé teszik, hogy az adatokat meghatározott mezőkben tároljuk, amelyek mindegyike egy adott adattípust tartalmaz (pl. szöveg, szám, dátum). Ez a strukturáltság elengedhetetlen az adatok hatékony lekérdezéséhez, rendezéséhez és elemzéséhez.
A rekordok szerepe az adatbázisokban nem korlátozódik a puszta tárolásra. Lehetővé teszik az adatbázis-kezelő rendszerek (DBMS) számára, hogy a következőket végezzék:
- Adatok integritásának biztosítása: A rekordokba beépíthetők érvényességi szabályok, amelyek garantálják, hogy csak érvényes adatok kerüljenek tárolásra. Például egy korhatárt csak 18 évnél idősebb személyekkel lehet kitölteni.
- Adatok közötti kapcsolatok kezelése: A rekordok kapcsolatban állhatnak más rekordokkal, akár ugyanabban a táblában, akár más táblákban. Ez lehetővé teszi a relációs adatbázisok létrehozását, amelyekben az adatok közötti kapcsolatok komplex rendszereket alkotnak. Például egy rendelés rekord tartalmazhat hivatkozást a hozzá tartozó ügyfél rekordra.
- Hatékony keresés és lekérdezés: A rekordok indexelhetők, ami azt jelenti, hogy a DBMS gyorsan megtalálhatja azokat a rekordokat, amelyek megfelelnek egy adott keresési feltételnek. Ez kritikus fontosságú a nagy adatbázisoknál, ahol a manuális keresés gyakorlatilag lehetetlen lenne.
A rekordok felépítése általában a következő elemeket tartalmazza:
- Mezők: A rekord egyes tulajdonságait reprezentáló oszlopok. Minden mezőnek van egy neve és egy adattípusa.
- Kulcsok: Egy vagy több mező, amely egyedileg azonosítja a rekordot. A primary key egy táblában egyedi, míg a foreign key egy másik táblára mutat, lehetővé téve a táblák közötti kapcsolatot.
- Adattípusok: Meghatározzák, hogy egy adott mezőben milyen típusú adat tárolható (pl. egész szám, szöveg, dátum).
A rekordok módosítása, létrehozása és törlése az adatbázis-kezelő rendszeren (DBMS) keresztül történik. A DBMS biztosítja, hogy ezek a műveletek konzisztensek és biztonságosak legyenek. A rekordok manipulálása általában SQL (Structured Query Language) nyelven történik.
A rekordok az adatbázisok alapvető építőkövei, amelyek lehetővé teszik az adatok strukturált tárolását, hatékony lekérdezését és az adatok közötti kapcsolatok kezelését.
Például, egy webáruházban a termékek adatait tartalmazó táblában minden termék egy rekordot képvisel. A rekord mezői tartalmazhatják a termék nevét, árát, leírását, képét és a készleten lévő mennyiséget. Egy másik táblázatban a rendelések szerepelnek, minden rendelés egy rekord. A rendelés rekord tartalmazhatja a rendelés dátumát, a szállítási címet és a megrendelt termékek listáját (amelyek hivatkoznak a termékeket tartalmazó tábla rekordjaira).
A rekordok megfelelő tervezése és kezelése kulcsfontosságú az adatbázis hatékony és megbízható működéséhez. A rosszul megtervezett rekordok adatvesztéshez, inkonzisztenciához és teljesítményproblémákhoz vezethetnek.
Rekordok a fájlkezelésben: szekvenciális és direkt elérés
A rekord az adatbázisok és fájlkezelés alapvető építőköve. Gyakorlatilag egy logikailag összetartozó adatmezők halmaza, melyek egyetlen entitást vagy objektumot írnak le. A fájlkezelés szempontjából a rekordok tárolási és hozzáférési módszerei kulcsfontosságúak.
Két fő módszer létezik a rekordok elérésére egy fájlban: a szekvenciális elérés és a direkt elérés (más néven véletlen elérés).
A szekvenciális elérés azt jelenti, hogy a rekordokat egymás után, a fájlban elfoglalt sorrendjükben olvassuk be. Ahhoz, hogy egy adott rekordhoz hozzáférjünk, be kell olvasnunk az összes előtte lévő rekordot. Ez a módszer egyszerűen implementálható, de lassú és nem hatékony, ha a fájlban távolabb lévő rekordokat kell elérnünk.
A szekvenciális elérés előnyei közé tartozik az egyszerűség és az, hogy kevés erőforrást igényel. Ugyanakkor hátránya, hogy a keresés időigényes. Például, ha egy névsort tartalmazó fájlban szeretnénk megtalálni a „Zoltán” nevet, akkor végig kell olvasnunk az összes nevet az elejétől kezdve, amíg el nem érjük a keresett nevet.
A direkt elérés lehetővé teszi, hogy közvetlenül, egy adott rekord címének ismeretében érjük el a rekordot a fájlban. Ehhez általában egy indexet használunk, amely a rekordok kulcsmezőit (például azonosítóját) és a hozzájuk tartozó fájlban lévő címét (offset) tartalmazza. A direkt elérés sokkal gyorsabb és hatékonyabb, mint a szekvenciális elérés, különösen nagy fájlok esetén, ahol gyakran kell egyedi rekordokat lekérdezni.
A direkt elérés lényege, hogy nem kell sorban beolvasni a rekordokat, hanem közvetlenül a kívánt rekordra ugorhatunk.
A direkt elérés implementálása bonyolultabb, mint a szekvenciális elérés, és több erőforrást igényel az index karbantartása miatt. Az index frissítésekor (új rekord hozzáadásakor, meglévő rekord módosításakor vagy törlésekor) gondoskodni kell arról, hogy az index mindig naprakész legyen.
A direkt eléréshez gyakran használnak hash függvényeket, amelyek a rekord kulcsmezőjéből számítanak ki egy címet a fájlban. Ez a módszer nagyon gyors hozzáférést tesz lehetővé, de ütközések (két különböző kulcs ugyanazt a címet generálja) esetén kezelni kell azokat.
A fájlkezelés során a megfelelő eljárás megválasztása az alkalmazás igényeitől függ. Ha a rekordokat gyakran kell sorrendben feldolgozni, a szekvenciális elérés lehet a megfelelő választás. Ha viszont gyakran kell egyedi rekordokat lekérdezni, a direkt elérés a hatékonyabb megoldás.
Rekordok a programozási nyelvekben: struktúrák és osztályok
A rekordok, mint az adatfeldolgozás alapvető építőkövei, a programozási nyelvekben különféle formákban jelennek meg, leggyakrabban struktúrák és osztályok formájában. Mindkettő célja, hogy logikailag összetartozó, de különböző adattípusú elemeket egyetlen egységként kezeljünk.
A struktúrák (angolul structs) általában egyszerűbb, kevésbé komplex adatszerkezetek. Gyakran használják őket adatbázis-rekordok, fájlformátumok vagy egyéb egyszerű adathalmazok reprezentálására. A struktúrákban definiált elemeket mezőknek (angolul fields) nevezzük. Például egy személy adatait tároló struktúra tartalmazhat mezőket a név, a kor, a cím és a telefonszám számára.
A struktúrák lényege, hogy egyetlen néven hivatkozhatunk egy összetett adathalmazra, ami jelentősen leegyszerűsíti a kód olvashatóságát és karbantarthatóságát.
Ezzel szemben az osztályok (angolul classes) összetettebb koncepciót képviselnek. Az osztályok nem csak adatokat (attribútumokat), hanem metódusokat (függvényeket) is tartalmazhatnak, amelyek az osztály példányaival (objektumokkal) végeznek műveleteket. Ez az objektumorientált programozás (OOP) alapja.
Az osztályok öröklődést is lehetővé tesznek, ami azt jelenti, hogy egy osztály (az alosztály) átveheti egy másik osztály (a szülőosztály) attribútumait és metódusait, és kiegészítheti azokat saját, speciális funkcionalitással. Ez rendkívül hatékony a kód újrafelhasználására és a komplex rendszerek modellezésére.
A különbség a struktúrák és osztályok között a programozási nyelvtől függően változhat. Néhány nyelvben (pl. C++) a struktúrák és osztályok szinte teljesen egyenértékűek, a fő különbség a tagok alapértelmezett láthatóságában rejlik (struktúráknál public, osztályoknál private). Más nyelvekben (pl. Java) minden adat objektumként van kezelve, így kizárólag osztályok léteznek. C# nyelvben mindkettő megtalálható, a struct egy érték típusú, míg a class egy referencia típusú adatszerkezetet hoz létre.
A megfelelő adatszerkezet kiválasztása (struktúra vagy osztály) a feladat komplexitásától és a programozási paradigma követelményeitől függ. Ha egyszerű adatok csoportosítására van szükség, a struktúra elegendő lehet. Ha viszont komplexebb funkcionalitásra és objektumorientált megközelítésre van szükség, akkor az osztály a megfelelő választás.
Az adatfeldolgozás során mindkét konstrukció elengedhetetlen. A struktúrák gyors és hatékony módot kínálnak az adatok tárolására és kezelésére, míg az osztályok lehetővé teszik a valós világbeli entitások modellezését és a komplex problémák elegáns megoldását.
Rekordok és a relációs adatmodell
A rekord az adatfeldolgozásban egy összetett adattípus, amely különböző, egymással logikailag összefüggő adatmezőket (attribútumokat) tartalmaz. Ezek az adatmezők eltérő adattípusúak lehetnek, például szöveg, szám, dátum, stb. A rekordokat gyakran használják arra, hogy egy entitás (valós vagy elvont dolog) tulajdonságait ábrázolják.
A relációs adatmodellben a rekordok központi szerepet töltenek be. Itt a rekordok sorokként jelennek meg egy táblában (relációban). Minden sor egy-egy egyedi rekordot reprezentál, a tábla oszlopai pedig az adott entitás attribútumait (mezőit) jelölik. A tábla minden sora egyedi, bár előfordulhat, hogy bizonyos attribútumok értékei megegyeznek.
A relációs adatmodell alapelvei szerint a rekordoknak atomisnak kell lenniük. Ez azt jelenti, hogy egy adatmező nem bontható tovább kisebb részekre. Például egy teljes név helyett külön kell tárolni a vezetéknevet és a keresztnevet. Ez az atomicitás elve elengedhetetlen a hatékony adatkezelés és lekérdezések szempontjából.
A rekordok közötti kapcsolatokat kulcsok segítségével lehet definiálni. A primary key (elsődleges kulcs) egy vagy több attribútum, amely egyedileg azonosítja a rekordot a táblán belül. A foreign key (idegen kulcs) egy olyan attribútum, amely egy másik tábla elsődleges kulcsára hivatkozik, ezáltal kapcsolatot teremtve a két tábla rekordjai között.
Az idegen kulcsok teszik lehetővé a táblák közötti kapcsolatok definiálását, ami a relációs adatmodell egyik legfontosabb jellemzője.
Például, egy „Ügyfelek” tábla tartalmazhat olyan attribútumokat, mint ÜgyfélID (elsődleges kulcs), Név, Cím, Telefonszám. Egy „Rendelések” tábla pedig tartalmazhat olyan attribútumokat, mint RendelésID (elsődleges kulcs), ÜgyfélID (idegen kulcs, amely az „Ügyfelek” táblára mutat), Dátum, Összeg. Az ÜgyfélID idegen kulcs segítségével tudjuk összekapcsolni az ügyfeleket a rendeléseikkel.
A rekordok kezelése a relációs adatbázis-kezelő rendszerek (RDBMS) alapvető feladata. Az RDBMS-ek lehetővé teszik a rekordok létrehozását, olvasását, frissítését és törlését (CRUD műveletek). A SQL (Structured Query Language) a legelterjedtebb nyelv a relációs adatbázisokkal való interakcióra. Az SQL segítségével lehet lekérdezni, szűrni, rendezni és módosítani a rekordokat.
A rekordok és a relációs adatmodell kombinációja hatékony és rugalmas módot kínál az adatok strukturálására és kezelésére. Lehetővé teszi a komplex adatkapcsolatok ábrázolását, az adatok integritásának biztosítását és a hatékony adatlekérdezést.
Rekordok a NoSQL adatbázisokban
A NoSQL adatbázisokban a „rekord” fogalma jelentősen eltérhet a relációs adatbázisok hagyományos táblázatos felépítésétől. Míg a relációs adatbázisokban a rekordok sorok egy táblázatban, amelyek előre meghatározott oszlopokkal (sémával) rendelkeznek, a NoSQL rendszerekben a rekordok (gyakran „dokumentumoknak” is nevezik őket) sokkal rugalmasabbak lehetnek.
A NoSQL adatbázisok séma-nélküliek vagy séma-olvasáskor-érvényesítettek. Ez azt jelenti, hogy nem kell előre definiálni az adatstruktúrát. Egy adott „rekord” tartalmazhat bármilyen mezőt, és a mezők típusa is eltérhet a többi rekord mezőtípusától. Ez a rugalmasság különösen előnyös akkor, ha változó adatstruktúrákkal dolgozunk, vagy ha gyorsan kell prototípusokat készíteni.
Például, egy dokumentum-orientált adatbázisban, mint a MongoDB, egy „rekord” (dokumentum) egy JSON-szerű objektum. Ez az objektum tartalmazhat különböző adattípusokat, beleértve a beágyazott objektumokat és tömböket.
- Kulcs-érték tárolók: Ebben a modellben a „rekord” egy kulcs és egy hozzá tartozó érték páros. Az érték bármilyen adat lehet, a egyszerű szövegtől a komplex objektumokig.
- Dokumentum-orientált adatbázisok: A rekord egy dokumentum, amely általában JSON vagy XML formátumban van tárolva. Minden dokumentum önálló egységként kezelt, és tartalmazhat különböző mezőket és beágyazott dokumentumokat.
- Oszlop-orientált adatbázisok: A rekord egy sor, amely oszlopcsaládokba van rendezve. Minden oszlopcsalád egyedi adatszerkezetet tartalmazhat.
- Gráf adatbázisok: A rekord egy csomópont vagy él a gráfban. A csomópontok entitásokat, az élek pedig kapcsolatokat reprezentálnak.
A NoSQL adatbázisok egyik legfontosabb előnye a horizontális skálázhatóság. A rekordok eloszthatók több szerver között, ami lehetővé teszi a nagy mennyiségű adat kezelését és a magas terhelés elviselését.
A NoSQL rendszerekben a „rekord” fogalma nem csak egy sor adatot jelent, hanem egy önálló, rugalmasan definiálható adategységet, amely alkalmazkodik az adott adatbázis modellhez és az alkalmazás igényeihez.
A NoSQL adatbázisokban a lekérdezések általában a rekordok tartalmára fókuszálnak, nem pedig a sémára. Ez lehetővé teszi a rugalmasabb és hatékonyabb adatlekérdezést, különösen akkor, ha komplex adatokkal dolgozunk.
Bár a NoSQL adatbázisok rugalmasságot kínálnak, fontos megjegyezni, hogy a megfelelő adatmodell kiválasztása kulcsfontosságú a hatékony adatkezeléshez. A sémamentesség nem jelenti azt, hogy nincs szükség tervezésre; éppen ellenkezőleg, alapos megfontolást igényel, hogy az adatok hogyan lesznek tárolva és lekérdezve.
A tranzakciókezelés is eltérhet a NoSQL adatbázisokban a relációs adatbázisokhoz képest. Míg a relációs adatbázisok ACID tranzakciókat biztosítanak, a NoSQL rendszerek gyakran a BASE elveket követik (Basically Available, Soft state, Eventually consistent), ami nagyobb teljesítményt és skálázhatóságot eredményez, de kompromisszumokat követelhet a konzisztencia terén. Ez azt jelenti, hogy a „rekord” módosítások nem feltétlenül azonnal láthatóak mindenhol a rendszerben, hanem idővel válnak konzisztenssé.
Rekordok serializálása és deserializálása
A rekordok, mint strukturált adategységek, az adatfeldolgozás alapkövei. A serializálás és deserializálás kulcsfontosságú folyamatok, amikor ezeket a rekordokat tárolni vagy továbbítani kell.
A serializálás lényegében a rekordok memóriában tárolt formátumának átalakítása egy olyan formátumba, amely alkalmas a tárolásra (például fájlba írásra) vagy a hálózaton keresztüli továbbításra. Ez a folyamat gyakran jár az adatok tömörítésével is, hogy kevesebb helyet foglaljanak, illetve gyorsabban lehessen őket továbbítani. A serializálás során az összetett adatstruktúrákat, mint például a rekordokat, egy sorba rendezett bájtfolyammá alakítják.
A deserializálás a serializálás fordítottja: a tárolt vagy továbbított bájtfolyamból visszaállítja az eredeti rekordot a memóriában. Ez lehetővé teszi, hogy a rekordot a program újra használhassa.
Számos serializációs formátum létezik, melyek közül a legnépszerűbbek:
- JSON (JavaScript Object Notation): Egy ember által is olvasható, szöveges formátum, amely széles körben elterjedt a webes alkalmazásokban.
- XML (eXtensible Markup Language): Egy másik szöveges formátum, amely nagyobb rugalmasságot biztosít, de általában terjedelmesebb, mint a JSON.
- Protocol Buffers: A Google által fejlesztett bináris formátum, amely nagy hatékonyságot és kis méretet kínál.
- Avro: Egy adat-serializációs rendszer, amelyet a Hadoop ökoszisztémában használnak, és amely támogatja a séma-evolúciót.
A serializálás és deserializálás elengedhetetlen a perzisztens adattároláshoz és a különböző rendszerek közötti adatcseréhez.
A serializálás során figyelembe kell venni az adattípusok kompatibilitását. Például, ha egy rekordot egy adott programnyelven serializálunk, majd egy másik programnyelven deserializáljuk, akkor gondoskodni kell arról, hogy az adattípusok megfelelően legyenek leképezve egymásra. Ezen kívül, fontos a verziókezelés, mert a rekordok struktúrája idővel változhat. A deserializáló programnak képesnek kell lennie kezelni a különböző verziójú rekordokat.
A serializálás és deserializálás során felléphetnek biztonsági kockázatok is. Például, ha a deserializált adatok tartalmaznak rosszindulatú kódot, az a program sérülését okozhatja. Ezért fontos a bemeneti adatok validálása és a biztonságos serializációs könyvtárak használata.
A hatékony serializálás és deserializálás jelentősen befolyásolhatja az alkalmazások teljesítményét. A lassú serializációs/deserializációs folyamatok szűk keresztmetszetet jelenthetnek, különösen nagy adatmennyiségek esetén. Ezért fontos a megfelelő serializációs formátum és könyvtár kiválasztása, figyelembe véve az alkalmazás specifikus igényeit.
A serializálás és deserializálás gyakori alkalmazási területei:
- Adatbázisok: A rekordok tárolása és visszaállítása.
- Hálózati kommunikáció: Adatok továbbítása a kliens és a szerver között.
- Üzenetkezelő rendszerek: Üzenetek küldése és fogadása.
- Konfigurációs fájlok: Alkalmazások konfigurációs adatainak tárolása.
Összességében a serializálás és deserializálás kritikus fontosságú a modern szoftverfejlesztésben, lehetővé téve a rekordok hatékony tárolását, továbbítását és feldolgozását.
Rekordok validálása és adatminőség
A rekordok validálása kritikus fontosságú az adatminőség biztosításában. Mivel a rekordok strukturált adatokat tartalmaznak, lehetőségünk van ellenőrizni, hogy az egyes mezők tartalma megfelel-e az előre definiált szabályoknak és elvárásoknak.
A validálás során számos szempontot figyelembe vehetünk:
- Adattípus ellenőrzés: Meggyőződünk arról, hogy a mezőben tárolt adat a megfelelő típusú-e (pl. szám, szöveg, dátum).
- Értéktartomány ellenőrzés: Ellenőrizzük, hogy az érték egy elfogadható tartományba esik-e (pl. egy életkor nem lehet negatív).
- Formátum ellenőrzés: Biztosítjuk, hogy az adatok a megfelelő formátumban vannak-e (pl. egy telefonszám megfelelő formátumú-e).
- Kötelező mezők ellenőrzése: Megvizsgáljuk, hogy a kötelező mezők ki vannak-e töltve.
- Egyediség ellenőrzése: Ellenőrizzük, hogy egy adott mező értéke egyedi-e (pl. egy felhasználónév nem lehet kétszer ugyanaz).
A validálási folyamat során talált hibákat javítani kell. Ez történhet automatikusan, vagy manuálisan, attól függően, hogy a hiba milyen jellegű és milyen szabályok vonatkoznak rá.
A helytelenül validált rekordok hibás elemzésekhez, rossz döntésekhez és végső soron veszteségekhez vezethetnek.
Az adatminőség fenntartása érdekében a validálást rendszeresen el kell végezni, különösen az adatbevitel és az adatmigráció során. Az adatminőség nem egy egyszeri feladat, hanem egy folyamatos erőfeszítés.
A validáláshoz különböző eszközök és technikák állnak rendelkezésre, beleértve az adatbázis-kezelő rendszerek beépített funkcióit, az egyedi szkripteket és a dedikált adatminőség-kezelő szoftvereket.