


A processzormag a központi feldolgozó egység (CPU) legfontosabb építőköve. Lényegében ez az a rész, amely ténylegesen végrehajtja a számításokat és utasításokat, amelyek a számítógép működését lehetővé teszik. Egyetlen CPU is tartalmazhat több magot, ami lehetővé teszi a párhuzamos feladatvégzést, azaz egyszerre több program futtatását anélkül, hogy a teljesítmény jelentősen csökkenne.
Minden mag rendelkezik saját vezérlőegységgel (CU), aritmetikai-logikai egységgel (ALU) és regiszterkészlettel. A vezérlőegység felelős az utasítások dekódolásáért és a végrehajtásuk koordinálásáért. Az aritmetikai-logikai egység végzi a tényleges matematikai és logikai műveleteket. A regiszterek pedig a gyors elérésű memóriaterületek, amelyek az adatok ideiglenes tárolására szolgálnak a feldolgozás során.
A többmagos processzorok elterjedése forradalmasította a számítástechnikát. Ahelyett, hogy egyetlen mag végezné az összes munkát, a feladatok eloszthatók a különböző magok között, ami jelentősen növeli a rendszer sebességét és hatékonyságát. Ez különösen fontos a modern alkalmazások esetében, amelyek gyakran nagyméretű adathalmazokkal dolgoznak és komplex számításokat igényelnek.
A processzormagok számának növekedése közvetlenül javítja a multitasking képességeket és a ресурсиigényes alkalmazások teljesítményét.
A magok közötti kommunikációt a CPU buszrendszere biztosítja. A magok hozzáférhetnek a rendszer memóriájához és a perifériás eszközökhöz, ami lehetővé teszi a zökkenőmentes adatcserét és a feladatok összehangolt végrehajtását. A modern CPU-k gyakran tartalmaznak beépített gyorsítótárat (cache) is, amely a gyakran használt adatokat tárolja, így még gyorsabbá téve a hozzáférést.
A processzormagok tervezése és optimalizálása folyamatosan fejlődik. A gyártók igyekeznek minél kisebb méretű, de annál erősebb és energiahatékonyabb magokat létrehozni. Ez a versenyhelyzet ösztönzi az innovációt és a teljesítmény növekedését a számítástechnika minden területén.
A processzormag definíciója és alapvető felépítése
A processzormag (angolul processor core) a központi feldolgozó egység (CPU) legfontosabb alkotóeleme. Gyakorlatilag a CPU azon része, amely ténylegesen végrehajtja a számításokat és utasításokat. Régebben a CPU-k egyetlen maggal rendelkeztek, ami azt jelentette, hogy egyszerre csak egy utasítássorozatot tudtak feldolgozni. A modern CPU-k azonban több magot tartalmaznak, lehetővé téve a párhuzamos feldolgozást, ami jelentősen növeli a számítógép teljesítményét.
Minden egyes processzormag rendelkezik saját vezérlőegységgel (Control Unit), aritmetikai-logikai egységgel (ALU) és regiszterkészlettel. A vezérlőegység felelős az utasítások dekódolásáért és a végrehajtás irányításáért. Az aritmetikai-logikai egység végzi a matematikai és logikai műveleteket, míg a regiszterek a feldolgozás során használt adatokat tárolják.
A processzormagok működése az utasítás-végrehajtási ciklus köré épül. Ez a ciklus általában a következő lépésekből áll: az utasítás betöltése a memóriából (fetch), az utasítás dekódolása (decode), az operandusok betöltése (fetch operands), az utasítás végrehajtása (execute) és az eredmény visszairása (write back). Ezt a ciklust ismétli a processzormag folyamatosan, amíg a végrehajtandó feladat be nem fejeződik.
Minél több maggal rendelkezik egy CPU, annál több feladatot képes párhuzamosan elvégezni, ami gyorsabb és hatékonyabb működést eredményez.
A modern processzormagok emellett számos fejlett technológiát alkalmaznak a teljesítmény növelése érdekében. Ilyen például a pipelining, amely lehetővé teszi, hogy egy utasítás végrehajtása megkezdődjön, mielőtt az előző utasítás befejeződne. Egy másik fontos technológia a branch prediction, amely megpróbálja megjósolni a program következő ágát, így elkerülhető a felesleges várakozás. A cache memória szintén kulcsszerepet játszik a teljesítményben, mivel gyors hozzáférést biztosít a gyakran használt adatokhoz és utasításokhoz.
A processzormagok tervezése és gyártása rendkívül összetett folyamat. A gyártók folyamatosan törekednek a magok méretének csökkentésére, a fogyasztásuk optimalizálására és a teljesítményük növelésére. Ez a verseny a technológiai fejlődés motorja, amely lehetővé teszi, hogy számítógépeink egyre gyorsabbak és hatékonyabbak legyenek.
A CPU és a processzormagok kapcsolata: Többmagos processzorok evolúciója
A CPU, vagyis a központi feldolgozó egység, az számítógép „agya”. Feladata a programok utasításainak végrehajtása, a számítások elvégzése és az adatok kezelése. A modern CPU-k nem egyetlen, hanem több processzormagból állnak. Ezek a magok lényegében önálló feldolgozó egységek, amelyek párhuzamosan képesek feladatokat végrehajtani.
A processzormag szerepe kulcsfontosságú a teljesítmény szempontjából. Egy egymagos processzor csak egy szálat képes egyszerre futtatni, míg egy többmagos processzor egyszerre több szálat is képes kezelni, ezáltal jelentősen növelve a rendszer sebességét és hatékonyságát. A többmagos processzorok megjelenése forradalmasította a számítástechnikát, lehetővé téve a komplex alkalmazások (pl. videószerkesztés, 3D modellezés, játékok) zökkenőmentes futtatását.
A többmagos processzorok megjelenésével a szoftverfejlesztőknek is alkalmazkodniuk kellett, hogy programjaik kihasználják a párhuzamos feldolgozás előnyeit.
A processzormagok működése során az utasításokat dekódolják, végrehajtják és tárolják az eredményeket. Minden mag rendelkezik saját vezérlőegységgel, aritmetikai-logikai egységgel (ALU) és regiszterekkel, melyek a feladatok elvégzéséhez szükségesek. A magok emellett osztozhatnak bizonyos erőforrásokon, például a gyorsítótáron (cache), ami az adatok gyorsabb elérését teszi lehetővé.
A többmagos processzorok evolúciója során a magok száma folyamatosan nőtt. A kezdeti kétmagos (dual-core) processzorokat követték a négymagos (quad-core), hatmagos (hexa-core), nyolcmagos (octa-core) és még több maggal rendelkező processzorok. Ez a tendencia a párhuzamos feldolgozás iránti növekvő igényt tükrözi, amely elengedhetetlen a modern számítógépes feladatok hatékony elvégzéséhez.
A magok közötti kommunikációt és a feladatok elosztását a processzor vezérlőegysége végzi. A modern operációs rendszerek képesek a feladatokat automatikusan elosztani a rendelkezésre álló magok között, optimalizálva a teljesítményt és a terhelést.
Egy mag működése: Utasításlehívás, dekódolás, végrehajtás, visszairás (Fetch, Decode, Execute, Writeback)
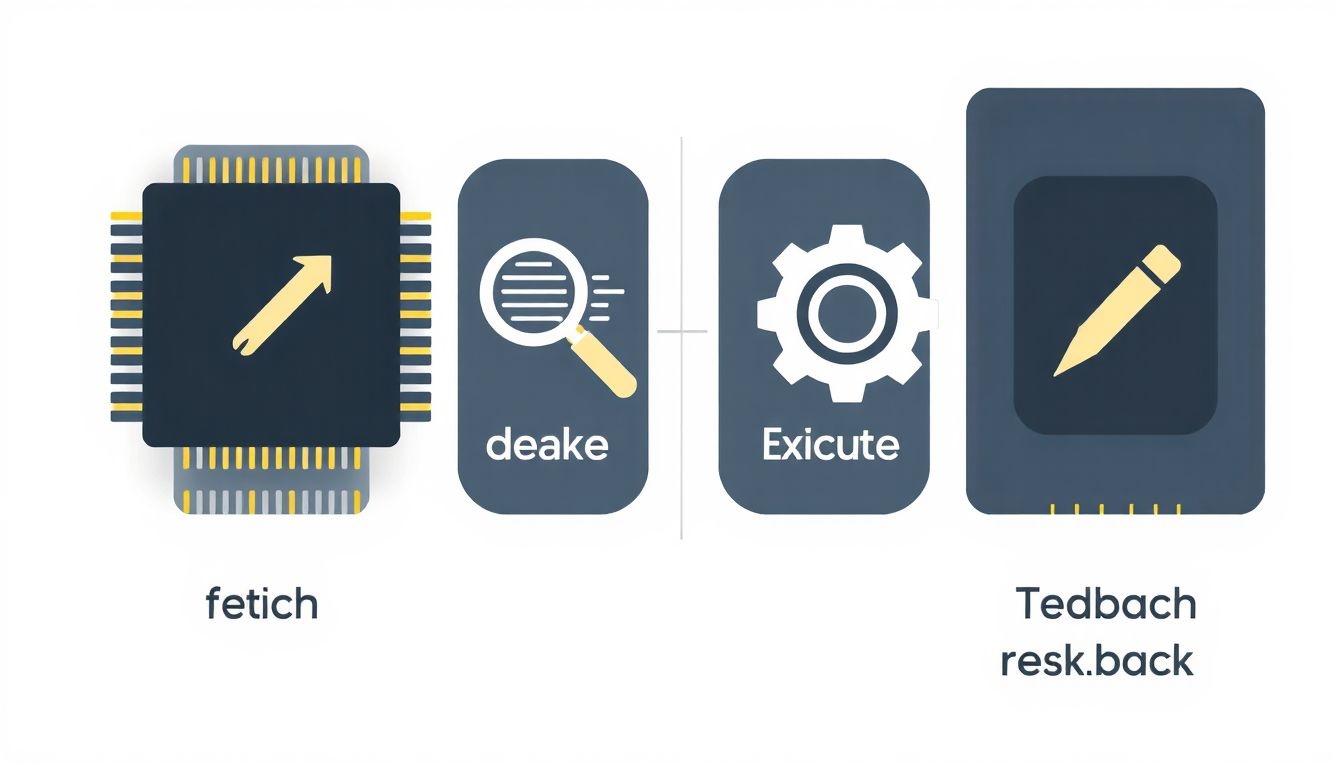
A processzormag a központi feldolgozóegység (CPU) azon része, amely ténylegesen elvégzi a számításokat és az utasítások végrehajtását. Egy modern CPU több magot is tartalmazhat, lehetővé téve a párhuzamos feldolgozást és a teljesítmény növelését. Egyetlen mag működése egy jól meghatározott ciklust követ, melyet Utasításlehívás (Fetch), Dekódolás (Decode), Végrehajtás (Execute) és Visszaírás (Writeback) fázisokra oszthatunk.
Utasításlehívás (Fetch): Ez a ciklus első lépése. A mag lekéri a következő végrehajtandó utasítást a memóriából. Az utasításszámláló (program counter, PC) tárolja a következő utasítás memóriacímet. A mag az utasításszámlálóban található címen lévő utasítást olvassa be a memóriából, majd az utasításszámlálót megnöveli, hogy a következő utasításra mutasson (általában az utasítás méretével). Az utasítás általában egy bináris kód, amelyet a processzor értelmezni tud.
Dekódolás (Decode): Miután az utasítás beolvasásra került, a dekódoló egység értelmezi azt. A dekódolás során az utasítás bináris kódját vezérlőjelekké alakítják, amelyek a CPU különböző részeit irányítják. Például, ha az utasítás egy összeadás, a dekódoló egység aktiválja az összeadó áramkört és beállítja a megfelelő operandusokat. A dekódolás során az utasítás operandusait is azonosítják, amelyek regiszterekben vagy a memóriában tárolt adatokra mutathatnak.
Végrehajtás (Execute): A dekódolás után a mag végrehajtja az utasítást. Ez a fázis magában foglalhatja aritmetikai műveletek (összeadás, kivonás, szorzás, osztás), logikai műveletek (ÉS, VAGY, NEM), adatmozgatás (memóriából regiszterbe, regiszterből memóriába) és vezérlésátadás (ugrás, feltételes ugrás) végrehajtását. A végrehajtás során a mag a megfelelő áramköröket (pl. ALU – Arithmetic Logic Unit) használja, és a regiszterekben vagy a memóriában tárolt adatokkal dolgozik.
Visszaírás (Writeback): A végrehajtás eredményét vissza kell írni valahova. Ez általában egy regiszterbe történik, de lehet a memóriába is. A visszaírás lehetővé teszi, hogy az eredményt a következő utasítások felhasználhassák. Például, ha az összeadás eredményét egy regiszterbe írják vissza, a következő utasítás felhasználhatja ezt az értéket egy másik számításhoz. A visszaírás befejezi az utasítás végrehajtási ciklusát, és a mag visszatér az utasításlehívás fázisba, hogy a következő utasítást feldolgozza.
A processzormag működése egy folyamatos ciklus, amely ismétlődően hajtja végre az Utasításlehívás, Dekódolás, Végrehajtás és Visszaírás fázisokat, lehetővé téve a programok futtatását.
Ezen fázisok optimalizálása kulcsfontosságú a processzor teljesítményének növeléséhez. A pipeline technika például lehetővé teszi, hogy a mag egyszerre több utasításon dolgozzon, a különböző fázisokban. Így amíg az egyik utasítás a végrehajtási fázisban van, a következő utasítás dekódolás alatt állhat, és a harmadik utasítás már lehívásra kerülhet. Ez a párhuzamosság jelentősen növeli a processzor sebességét.
A cache memória is fontos szerepet játszik a processzormag működésében. A cache egy gyors, de kisebb méretű memória, amely a gyakran használt adatokat és utasításokat tárolja. Amikor a mag egy adatra vagy utasításra van szüksége, először a cache-ben keresi. Ha megtalálja (cache hit), akkor az adatot gyorsan be tudja olvasni. Ha nincs a cache-ben (cache miss), akkor a lassabb főmemóriából kell beolvasni, ami időt vesz igénybe. A jó cache-kezelés csökkenti a memóriaelérések számát, és javítja a processzor teljesítményét.
Az ALU (Arithmetic Logic Unit) szerepe a processzormagban
Az ALU, vagyis az Arithmetic Logic Unit, a processzormag szíve, az a komponens, ahol a számítási és logikai műveletek ténylegesen végbemennek. A CPU-ban található minden egyes processzormagban (core) legalább egy ALU található, de komplexebb architektúrákban akár több is lehet a párhuzamos feldolgozás érdekében. Az ALU felelős a legalapvetőbb matematikai műveletekért, mint az összeadás, kivonás, szorzás és osztás, de ezen túlmenően logikai műveleteket is végez, mint az ÉS (AND), VAGY (OR), NEM (NOT) és KIZÁRÓ VAGY (XOR).
Az ALU működése a következőképpen zajlik: kap bemenetként operandusokat (számokat vagy adatokat), valamint egy vezérlőjelet, ami meghatározza, hogy milyen műveletet kell elvégeznie. A vezérlőjelet a CPU vezérlőegysége (Control Unit) generálja az éppen futó program utasításai alapján. Az ALU a bemeneti adatokon elvégzi a kért műveletet, és a művelet eredményét adja ki kimenetként. Ezen kívül az ALU statusz biteket is generálhat, amelyek információt hordoznak a művelet eredményéről, például arról, hogy történt-e túlcsordulás (overflow) vagy nulla lett-e az eredmény.
Az ALU teljesítménye közvetlenül befolyásolja a processzor általános sebességét és hatékonyságát.
A modern ALU-k rendkívül komplex áramkörök, amelyek optimalizáltak a sebességre és az energiahatékonyságra. Számos technika létezik az ALU teljesítményének növelésére, például a carry-lookahead adder, ami felgyorsítja az összeadás műveletet, vagy a pipelining, ami lehetővé teszi, hogy az ALU egyszerre több műveleten dolgozzon. A processzorgyártók folyamatosan fejlesztik az ALU-k architektúráját, hogy minél gyorsabb és hatékonyabb számítási képességeket biztosítsanak a felhasználóknak.
Az ALU-k építőelemei a logikai kapuk (pl. AND, OR, NOT kapuk), amelyek tranzisztorokból épülnek fel. A logikai kapuk kombinációjával bonyolultabb áramkörök hozhatók létre, amelyek képesek elvégezni a kívánt aritmetikai és logikai műveleteket. A regiszterek is fontos szerepet játszanak az ALU működésében, mivel ezekben tárolódnak az operandusok és a művelet eredménye.
A vezérlőegység (Control Unit) feladatai a magon belül
A processzormagon belül a vezérlőegység (Control Unit, CU) kulcsszerepet játszik a végrehajtási folyamat koordinálásában. A CU felelős az utasítások értelmezéséért és a megfelelő jelek generálásáért, amelyek irányítják a CPU többi részének működését. Gyakorlatilag a karmester szerepét tölti be a processzorban.
A vezérlőegység elsődleges feladata az utasítások lekérése a memóriából. Miután lekérte az utasítást, a CU dekódolja azt, azaz értelmezi, hogy a processzornak pontosan mit kell tennie. Ez a dekódolási folyamat elengedhetetlen ahhoz, hogy a CPU megértse, milyen műveleteket kell végrehajtania (pl. összeadás, kivonás, adatmozgatás).
A dekódolást követően a vezérlőegység vezérlőjeleket generál. Ezek a jelek aktiválják a processzor különböző részeit, például az aritmetikai-logikai egységet (ALU), a regisztereket és a memóriát. A vezérlőjelek biztosítják, hogy az adatok a megfelelő helyre kerüljenek, és a műveletek a helyes sorrendben hajtódjanak végre. Például, ha egy utasítás két szám összeadását írja elő, a CU aktiválja az ALU összeadó áramkörét, és biztosítja, hogy a két szám az ALU bemenetére kerüljön.
A vezérlőegység központi szerepet játszik a CPU működésében, hiszen ő felel a programkód utasításainak értelmezéséért és a megfelelő végrehajtási lépések koordinálásáért.
A CU működése ciklikus: lekérés, dekódolás, végrehajtás. Ezt a ciklust folyamatosan ismétli a processzor, amíg a program fut. A ciklus sebessége (a processzor órajele) határozza meg, hogy milyen gyorsan képes a CPU végrehajtani az utasításokat.
A modern processzorokban a vezérlőegységek rendkívül összetettek és optimalizáltak. Különböző technikákat alkalmaznak a teljesítmény növelésére, például pipeline-ozást (több utasítás párhuzamos feldolgozása) és spekulatív végrehajtást (az utasítások végrehajtása még azelőtt, hogy biztos lenne a szükségességük). Mindezek a fejlesztések a vezérlőegység hatékonyságát növelik, ami végső soron a számítógép teljesítményében mutatkozik meg.
Regiszterek a processzormagban: Típusok és funkciók
A processzormagban található regiszterek kulcsfontosságú szerepet töltenek be a CPU működésében. Ezek a nagy sebességű tárolóhelyek, amelyek közvetlenül a processzor elérhetőségi körében vannak, és lehetővé teszik az adatok és utasítások gyors tárolását és elérését. A regiszterek különböző típusokra oszthatók, mindegyiknek megvan a maga speciális funkciója.
Az egyik legfontosabb típus az általános célú regiszter (General Purpose Register, GPR). Ezek a regiszterek az adatok ideiglenes tárolására szolgálnak a számítások során. A GPR-ek használhatók operandusok tárolására matematikai műveletekhez, memóriacímek tárolására, vagy egyszerűen csak adatok pufferelésére.
A programszámláló (Program Counter, PC) egy másik kritikus regiszter. A PC a következő végrehajtandó utasítás memóriacímét tárolja. A CPU minden utasítás végrehajtása után automatikusan növeli a PC értékét, hogy a következő utasításra mutasson. Elágazási utasítások esetén a PC értéke megváltozhat, ami a program futásának menetét befolyásolja.
A veremmutató (Stack Pointer, SP) a verem tetejére mutat a memóriában. A verem ideiglenes adatok tárolására, például függvényhívások során a visszatérési címek és lokális változók tárolására szolgál. A veremmutató biztosítja, hogy a verem helyesen működjön a push (adat elhelyezése a veremben) és pop (adat eltávolítása a veremből) műveletek során.
Az utasításregiszter (Instruction Register, IR) az éppen végrehajtásra váró utasítást tárolja. Az utasítás a memóriából kerül beolvasásra, majd az IR-be helyezésre, ahol a dekódoló áramkör értelmezi és végrehajtja. Az IR tartalma határozza meg a CPU által végrehajtandó műveletet.
A státuszregiszter (Status Register, más néven Flag Register) különböző biteket tartalmaz, amelyek a CPU állapotát tükrözik. Ezek a bitek, más néven flag-ek, jelezhetik például, hogy egy aritmetikai művelet eredménye nulla volt-e, negatív volt-e, történt-e túlcsordulás, vagy hogy egy összehasonlítás eredménye egyenlő volt-e. A státuszregiszter flag-jeit a feltételes elágazási utasítások használják a program futásának irányítására.
A regiszterek sebessége és közvetlen elérhetősége elengedhetetlen a CPU teljesítményéhez, mivel minimalizálják a memóriából történő adatolvasás és -írás szükségességét.
Példák a regiszterek használatára:
- Adatok betöltése a memóriából egy regiszterbe, műveletek végrehajtása a regiszteren lévő adatokkal, majd az eredmény visszamentése a memóriába.
- Függvényhíváskor a paraméterek és a visszatérési címek regiszterekben kerülnek átadásra.
- Interrupt kezelés során a CPU állapotát (beleértve a regiszterek tartalmát) elmenti a verembe, majd a interrupt kezelő rutin lefutása után visszaállítja az eredeti állapotot.
A regiszterek száma és típusa processzorarchitektúránként változik, de a fenti alapelvek minden architektúrában érvényesek. A regiszterek hatékony használata kulcsfontosságú a programok optimalizálásához és a CPU maximális teljesítményének eléréséhez.
Cache memória a processzormagban: L1, L2, L3 cache szintek

A modern processzorok teljesítményének kulcseleme a cache memória, ami a processzormagon belül helyezkedik el. Ennek a memóriának a célja, hogy a CPU gyorsabban hozzáférjen a gyakran használt adatokhoz és utasításokhoz, elkerülve a lassabb RAM-hoz való folyamatos fordulást.
A cache memória több szinten szerveződik, általában L1, L2 és L3 cache szinteket különböztetünk meg. Mindegyik szint különböző méretű, sebességű és elhelyezkedésű a processzormagon belül.
Az L1 cache a leggyorsabb és legkisebb, közvetlenül a processzormagban található. Gyakran ketté van választva adat (data) és utasítás (instruction) cache-re, ami lehetővé teszi a párhuzamos hozzáférést az adatokhoz és a végrehajtandó kódhoz. Mivel a legközelebb van a processzorhoz, a hozzáférési ideje rendkívül rövid, azonban a mérete korlátozott, tipikusan néhány tíz kilobájt (KB).
Az L1 cache elsődleges célja a leggyakrabban használt adatok és utasítások tárolása, ezzel minimalizálva a késleltetést és maximalizálva a processzor hatékonyságát.
Az L2 cache nagyobb, mint az L1, de lassabb is. Általában a processzormagon belül található, de távolabb az L1 cache-től. Az L2 cache mérete általában néhány száz kilobájt (KB) vagy akár néhány megabájt (MB) is lehet. Az L2 cache pufferként szolgál az L1 és a RAM között, tárolva azokat az adatokat, amelyek nem férnek el az L1-ben, de valószínűleg a közeljövőben szükség lesz rájuk.
Az L3 cache a legnagyobb és leglassabb a három szint közül. Általában a processzormagok között oszlik meg, vagyis több mag is hozzáférhet ugyanahhoz az L3 cache-hez. Mérete több megabájt (MB) is lehet. Az L3 cache célja, hogy tárolja azokat az adatokat, amelyek nem férnek el az L1 és L2 cache-ben, de még mindig gyorsabban elérhetőek, mint a RAM. Ez a megosztott cache különösen hasznos a többmagos processzorok esetében, mivel lehetővé teszi a magok közötti adatok gyors megosztását.
A cache hierarchia működése a következő: amikor a processzor adatra van szüksége, először az L1 cache-ben keresi. Ha ott nem találja (cache miss), akkor az L2 cache-ben, majd az L3 cache-ben keresi. Ha az adat egyik cache-ben sincs jelen, akkor a RAM-ból kell betölteni, ami jelentős késleltetést okoz. Ezt a folyamatot cache hit-nek nevezzük, ha az adat valamelyik cache-ben megtalálható.
A cache memória hatékonyságát számos tényező befolyásolja, beleértve a cache méretét, a cache vonal méretét (cache line size) és a cache helyettesítési algoritmusát. A nagyobb cache méret általában jobb teljesítményt eredményez, de nagyobb helyet és energiafogyasztást is jelent. A hatékony cache helyettesítési algoritmusok (például LRU – Least Recently Used) biztosítják, hogy a legkevésbé használt adatok kerüljenek eltávolításra a cache-ből, amikor új adatoknak kell helyet csinálni.
A cache memória optimalizálása kritikus fontosságú a processzor teljesítményének maximalizálásához. A szoftverfejlesztők is optimalizálhatják a kódjukat úgy, hogy a programok által használt adatok a lehető leggyakrabban a cache-ben legyenek, minimalizálva ezzel a lassabb RAM-hozzáférések számát.
A pipeline technológia: Hogyan gyorsítja fel a processzormag a végrehajtást
A processzormagok teljesítményének növelésében kulcsszerepet játszik a pipeline technológia. Ez a technika lehetővé teszi, hogy a processzor egyszerre több utasítást is feldolgozzon, ezzel jelentősen felgyorsítva a végrehajtást.
Képzeljünk el egy futószalagot egy gyárban. A pipeline hasonló elven működik: az utasítások feldolgozása több szakaszra van osztva (pl. utasításlehívás, dekódolás, végrehajtás, memóriahozzáférés, eredmény visszairás). Minden egyes szakasz egy adott időpillanatban egy-egy utasításon dolgozik, de amint egy utasítás továbblép a következő szakaszba, a korábbi szakasz máris elkezdhet egy új utasítással foglalkozni.
Hagyományos, nem-pipeline processzorok esetén egy utasítás teljes feldolgozása után kezdődhet csak a következő utasítás feldolgozása. Ezzel szemben a pipeline technológia lehetővé teszi, hogy az utasítások átfedésben legyenek, így a processzor hatékonyabban használja ki az erőforrásait.
Például, amíg az első utasítás a végrehajtási szakaszban van, a második utasítás dekódolható, a harmadik pedig lehívható a memóriából. Ez a párhuzamosság jelentősen csökkenti az üresjáratokat és növeli a teljesítményt.
A pipeline hatékonyságát befolyásolhatják a veszélyek (hazards). Ezek olyan helyzetek, amikor egy utasításnak várnia kell egy korábbi utasításra, mielőtt folytathatná a végrehajtást. Három fő típusú veszély létezik:
- Adatfüggőség (Data Hazard): Egy utasításnak szüksége van egy korábbi utasítás eredményére.
- Vezérlési függőség (Control Hazard): Egy elágazás (branch) utasítás befolyásolja, hogy melyik utasítás kerül végrehajtásra a következő lépésben.
- Strukturális függőség (Structural Hazard): Két utasításnak ugyanarra az erőforrásra van szüksége egyszerre.
A processzorok különböző technikákat alkalmaznak a veszélyek kezelésére, például:
- Adattovábbítás (Data Forwarding): Az eredményt közvetlenül a következő utasításnak adják át, ahelyett, hogy a memóriába írnák és onnan olvasnák vissza.
- Elágazás előrejelzés (Branch Prediction): Megpróbálják előre megjósolni, hogy egy elágazás hova fog ugrani, hogy a megfelelő utasításokat már időben elkezdhessék lehívni.
- Stall-ok (Pipeline Stalls): Ha a veszélyt nem lehet elkerülni, a pipeline megáll, amíg a probléma megoldódik.
A pipeline technológia mélysége is fontos tényező. A mélyebb pipeline több szakaszra bontja az utasítások feldolgozását, ami elméletileg nagyobb teljesítményt eredményezhet. Azonban a mélyebb pipeline érzékenyebb a veszélyekre, és a stall-ok nagyobb teljesítménycsökkenést okozhatnak.
A pipeline technológia alapvetően megváltoztatta a processzorok működését, lehetővé téve a sokkal gyorsabb és hatékonyabb végrehajtást.
A modern processzorok komplex pipeline-okat használnak, amelyek számos optimalizációt tartalmaznak a veszélyek minimalizálására és a teljesítmény maximalizálására. A pipeline technológia nélkül a mai számítógépek nem lennének képesek a jelenlegi komplex feladatok elvégzésére.
A superscalar architektúra: Párhuzamos utasításvégrehajtás
A superscalar architektúra egy olyan processzor tervezési elv, amely lehetővé teszi a több utasítás egyidejű végrehajtását egyetlen processzormagon belül. Ezzel jelentősen növelhető a CPU teljesítménye anélkül, hogy az órajelet növelni kellene. A hagyományos, nem-superscalar processzorok minden órajelciklusban csak egy utasítást képesek végrehajtani.
A superscalar architektúra alapja, hogy a processzor több végrehajtó egységet (pl. aritmetikai logikai egység, lebegőpontos egység, betöltő/tároló egység) tartalmaz. Ezek az egységek párhuzamosan tudnak működni. A processzor hardvere képes megvizsgálni az utasítássort, és azonosítani azokat az utasításokat, amelyek nincsenek egymástól függőségben, azaz párhuzamosan végrehajthatók.
A superscalar architektúra lényege tehát, hogy a processzor képes egyszerre több utasítást kibocsátani és végrehajtani, kihasználva a programokban rejlő párhuzamosságot.
A superscalar működéshez elengedhetetlen a utasítás ütemező (instruction scheduler), ami felelős az utasítások sorrendjének optimalizálásáért a párhuzamos végrehajtás maximalizálása érdekében. Ez az ütemező bonyolult algoritmusokat használ a függőségek feloldására és a végrehajtó egységek hatékony kihasználására.
A superscalar architektúra hatékonysága nagyban függ a programkódtól. Ha a kód sok egymástól függő utasítást tartalmaz, a párhuzamosítás lehetősége korlátozott. Ezért fontos a kódot optimalizálni a párhuzamos végrehajtás szempontjából.
Például, ha egy processzor két aritmetikai és egy lebegőpontos egységgel rendelkezik, akkor egyidejűleg végrehajthat két összeadást és egy szorzást, feltéve, hogy ezek az utasítások nem függnek egymástól. Azonban, ha az összeadás eredménye szükséges a szorzás végrehajtásához, akkor a szorzásnak meg kell várnia az összeadás befejezését.
A superscalar architektúrák különböző technikákat alkalmaznak a teljesítmény további növelésére, mint például a utasítás spekuláció (branch prediction), amely megpróbálja előre jelezni a feltételes elágazások eredményét, és a regiszter átnevezés (register renaming), amely megszünteti a hamis függőségeket.
A SMT (Simultaneous Multithreading) technológia, avagy a Hyper-Threading
A Simultaneous Multithreading (SMT), közismertebb nevén Hyper-Threading (HT), egy olyan technológia, amely lehetővé teszi egyetlen fizikai processzormag számára, hogy több szálat (thread) párhuzamosan futtasson. Ezt úgy éri el, hogy a processzor erőforrásait, például a végrehajtási egységeket és a gyorsítótárat, megosztja a szálak között.
Hagyományosan egy processzormag egyidejűleg csak egy szálat képes végrehajtani. A Hyper-Threading ezt a korlátot oldja fel azáltal, hogy a mag operációs rendszer felé úgy tűnik, mintha két logikai mag lenne. Ez lehetővé teszi az operációs rendszer számára, hogy egyidejűleg két szálat ütemezzen egyetlen fizikai magra.
A Hyper-Threading előnye, hogy javítja a processzor kihasználtságát. Ha egy szál várakozik például a memóriából származó adatokra, a másik szál továbbra is futhat, így a processzor nem tétlenkedik. Ez növeli a teljesítményt, különösen olyan feladatoknál, amelyek nagymértékben támaszkodnak a párhuzamosításra. A teljesítmény növekedése azonban nem lineáris. Általában 15-30% körüli javulást eredményez, mivel a szálak megosztják ugyanazokat a fizikai erőforrásokat.
A Hyper-Threading működésének lényege, hogy kihasználja a modern processzorok architektúrájának azon tulajdonságát, hogy bizonyos erőforrások (pl. az aritmetikai logikai egység, ALU) egy szál futása közben is kihasználatlanok maradhatnak. A HT lehetővé teszi, hogy egy másik szál használja ezeket az erőforrásokat, amíg az első szál várakozik.
A Hyper-Threading nem helyettesíti a valódi többmagos processzorokat, de egy hatékony módja annak, hogy a meglévő processzor erőforrásokat jobban kihasználjuk.
A technológia nem minden esetben hoz javulást. Bizonyos esetekben, például olyan alkalmazásoknál, amelyek teljes mértékben kihasználják a processzor összes erőforrását, a Hyper-Threading akár teljesítménycsökkenést is okozhat. Ennek oka, hogy a szálak versengenek a korlátozott erőforrásokért.
A Hyper-Threading engedélyezése vagy letiltása általában a BIOS-ban vagy UEFI-ben történik. A legtöbb modern operációs rendszer automatikusan felismeri és kihasználja a Hyper-Threading előnyeit, ha az engedélyezve van.
Processzormagok típusai: CISC vs. RISC architektúrák

A processzormagok (processor core) alapvetően két fő architektúra szerint épülhetnek fel: CISC (Complex Instruction Set Computing) és RISC (Reduced Instruction Set Computing). Mindkét megközelítés célja a számítások elvégzése, de a módszereik jelentősen eltérnek.
A CISC architektúra arra törekszik, hogy minél összetettebb utasításokat implementáljon a hardverben. Ez azt jelenti, hogy egyetlen utasítás képes elvégezni egy teljes műveletsorozatot, amire RISC architektúrában több egyszerű utasításra lenne szükség. Például, egy CISC processzor tartalmazhat egyetlen utasítást, ami közvetlenül kezeli a memóriából való adatbetöltést, a matematikai műveletet és az eredmény visszamentését a memóriába. Az x86 architektúra, amelyet az Intel és az AMD processzorai használnak, a CISC egyik elterjedt példája.
A RISC architektúra ezzel szemben az egyszerűségre és a hatékonyságra fókuszál. A RISC processzorok kevesebb, de egyszerűbb utasításkészlettel rendelkeznek. Minden utasítás általában egyetlen, jól definiált feladatot hajt végre. Az összetett műveleteket több egyszerű utasítás kombinációjával valósítják meg. Ez a megközelítés lehetővé teszi a processzor számára, hogy gyorsabban és hatékonyabban hajtsa végre az utasításokat. Az ARM architektúra, amelyet okostelefonokban, tabletekben és más beágyazott rendszerekben használnak, a RISC egyik legismertebb képviselője.
A RISC architektúra gyakran kevesebb tranzisztort igényel, ami alacsonyabb energiafogyasztást és kisebb hőtermelést eredményez.
A két architektúra közötti különbségek a tervezés és a teljesítmény szempontjából is jelentősek. A CISC processzorok bonyolultabb vezérlési logikát igényelnek az összetett utasítások dekódolásához és végrehajtásához. Ezzel szemben a RISC processzorok egyszerűbb vezérléssel rendelkeznek, ami lehetővé teszi a magasabb órajelet és a hatékonyabb párhuzamosítást.
Az alábbi táblázat összefoglalja a főbb különbségeket:
| Jellemző | CISC | RISC |
|---|---|---|
| Utasításkészlet | Komplex, sok utasítás | Egyszerű, kevés utasítás |
| Utasítás hossza | Változó | Fix |
| Címzési módok | Sokféle | Korlátozott |
| Általános célú regiszterek | Kevés | Sok |
| Kódméret | Kisebb | Nagyobb |
A processzormagok órajele és a teljesítmény kapcsolata
A processzormagok órajele, amelyet GHz-ben mérnek, kulcsfontosságú tényező a CPU teljesítményének meghatározásában. Az órajel azt mutatja meg, hogy a mag másodpercenként hány ciklust képes végrehajtani. Egy magasabb órajel elvileg több utasítás végrehajtását teszi lehetővé ugyanazon idő alatt, ami gyorsabb működést eredményez.
Azonban a valóság ennél árnyaltabb. Bár az órajel fontos, nem az egyetlen meghatározó tényező. A processzormag architektúrája, a cache mérete, és az utasításkészlet mind befolyásolják a teljesítményt. Például, egy újabb architektúrájú processzor alacsonyabb órajellel is felülmúlhat egy régebbi, magasabb órajelű processzort.
Az órajel önmagában nem ad teljes képet a processzor teljesítményéről.
Továbbá, a többmagos processzorok esetében az órajel hatása még összetettebb. Egy többmagos processzor több feladatot képes párhuzamosan végrehajtani, de az egyes magok órajele nem adja meg közvetlenül a teljes processzor teljesítményét. A szoftvernek is optimalizálva kell lennie a többmagos működésre ahhoz, hogy a teljes potenciált ki lehessen aknázni.
A turbo boost technológia lehetővé teszi, hogy a processzormagok az alap órajelüknél magasabb frekvencián működjenek, ha a hőmérséklet és az energiafogyasztás engedi. Ez javíthatja a teljesítményt, de nem garantált, hogy minden helyzetben elérhető.
Végül, az energiafogyasztás is szorosan összefügg az órajellel. A magasabb órajel általában nagyobb energiafogyasztást és hőtermelést jelent, ami korlátozhatja a maximális órajelet, amit egy processzor tartósan képes fenntartani.
A processzormagok energiafogyasztása és hőtermelése
A processzormagok energiafogyasztása és hőtermelése kritikus szempontok a CPU tervezése és használata során. Minél több mag található egy processzorban, és minél nagyobb a magok órajele, annál nagyobb az energiafogyasztásuk és a hőtermelésük.
Az energiafogyasztás, amelyet általában Wattban mérnek, közvetlenül befolyásolja a CPU által termelt hő mennyiségét. A hőtermelés a processzor hatékonyságának egyik legfontosabb mutatója. A túlzott hő károsíthatja a processzort, és instabilitást okozhat a rendszerben. Ezért van szükség hatékony hűtési megoldásokra, például hűtőbordákra és ventilátorokra.
A magasabb energiafogyasztás és hőtermelés nem feltétlenül jelenti azt, hogy a processzor jobb teljesítményt nyújt.
A processzorgyártók folyamatosan törekednek az energiahatékonyság javítására. Ennek érdekében különböző technikákat alkalmaznak, mint például a dinamikus órajel-szabályozás és a feszültség-szabályozás. Ezek a technikák lehetővé teszik, hogy a processzor a terheléshez igazítsa az órajelét és a feszültségét, ezáltal csökkentve az energiafogyasztást és a hőtermelést, amikor nincs szükség maximális teljesítményre.
A magok számának növelése önmagában is növelheti az energiafogyasztást, de okos tervezéssel a több mag lehetővé teheti a feladatok párhuzamos feldolgozását, ami végső soron hatékonyabb energiafelhasználást eredményezhet bizonyos munkaterhelések esetén. A modern processzorok gyakran tartalmaznak olyan energiagazdálkodási funkciókat, amelyek lehetővé teszik a nem használt magok kikapcsolását, tovább csökkentve az energiafogyasztást.
A processzormagok teljesítményének mérése: Benchmarking és metrikák
A processzormagok teljesítményének mérése kulcsfontosságú a számítógépek képességeinek felméréséhez. A benchmarking egy módszer, amellyel a processzorok teljesítményét standardizált tesztekkel értékeljük. Ezek a tesztek valós felhasználási helyzeteket szimulálnak, például videószerkesztést, játékot vagy szoftverfejlesztést.
Számos metrika létezik a processzormagok teljesítményének mérésére. Az egyik leggyakoribb a CPU órajel, ami megmutatja, hogy a processzor másodpercenként hány ciklust képes végrehajtani. Magasabb órajel általában jobb teljesítményt jelent, de nem feltétlenül tükrözi a valós teljesítményt, mivel az architektúra is jelentős szerepet játszik.
A teljesítmény mérésekor figyelembe kell venni a magok számát, az órajelet, a cache méretét és a processzor architektúráját is.
A magok száma szintén fontos tényező. Több mag lehetővé teszi a párhuzamos feladatvégzést, ami javítja a teljesítményt olyan alkalmazásokban, amelyek képesek kihasználni a többmagos architektúrát. A cache mérete is befolyásolja a teljesítményt, mivel a nagyobb cache gyorsabb hozzáférést biztosít a gyakran használt adatokhoz.
A benchmarking szoftverek különböző metrikákat használnak a teljesítmény értékelésére. Ilyen például a FLOPS (Floating Point Operations Per Second), ami a lebegőpontos műveletek sebességét méri. A SPECint és SPECfp tesztek az általános számítási és lebegőpontos teljesítményt mérik. Játékok esetében a FPS (Frames Per Second) az egyik legfontosabb metrika, ami megmutatja, hogy a játék milyen simán fut.
A valós teljesítmény azonban nem csak a nyers adatokon múlik. A szoftver optimalizálása, az operációs rendszer beállításai és a hardveres környezet is befolyásolják a végső eredményt. Ezért fontos, hogy a benchmark eredményeket kontextusban értelmezzük, és figyelembe vegyük a felhasználási területet is.
A benchmarking eredmények segítenek a felhasználóknak összehasonlítani a különböző processzorokat, és kiválasztani a legmegfelelőbbet az igényeiknek megfelelően. A gyártók is használják a benchmarkokat a processzorok fejlesztéséhez és optimalizálásához.