

A modern digitális korban az adatok jelentik az új aranyat, ám ezen érték kiaknázása egyre nagyobb kihívások elé állítja az informatikai rendszereket. Az exponenciálisan növekvő adatmennyiség és az egyre komplexebb, adatintenzívebb számítási feladatok megkövetelik a tárolási infrastruktúra folyamatos fejlődését. A hagyományos fájlrendszerek, amelyek évtizedekig szolgálták ki a standard igényeket, mára elérték teljesítménybeli korlátaikat, különösen a nagy teljesítményű számítástechnika (HPC), a mesterséges intelligencia (AI), a gépi tanulás (ML) és a Big Data analitika területén. Ebben a környezetben vált elengedhetetlenné a párhuzamos fájlrendszer (PFS) technológia, amely alapjaiban reformálja meg az adatok tárolásának és elérésének módját, lehetővé téve a rendkívüli skálázhatóságot és teljesítményt.
A párhuzamos fájlrendszerek nem csupán egy egyszerű továbbfejlesztést jelentenek, hanem egy paradigmaváltást a tárolás terén. Képzeljünk el egy autópályát, ahol a hagyományos rendszerek egyetlen sávot kínálnak, míg a párhuzamos fájlrendszerek több száz, akár több ezer sávot nyitnak meg az adatok számára. Ez a párhuzamosság kulcsfontosságú ahhoz, hogy a modern alkalmazások képesek legyenek hatékonyan feldolgozni a gigabájtos, terabájtos, vagy akár petabájtos adatkészleteket rekordidő alatt. Ennek a technológiának a mélyebb megértése kulcsfontosságú minden olyan szervezet számára, amely a jövő adatvezérelt kihívásaira készül.
A hagyományos fájlrendszerek korlátai és a párhuzamosság igénye
Mielőtt belemerülnénk a párhuzamos fájlrendszerek működésébe, érdemes megvizsgálni, miért is váltak szükségessé. A hagyományos, lokális vagy hálózati fájlrendszerek, mint az NTFS, ext4, NFS (Network File System) vagy SMB (Server Message Block), kiválóan alkalmasak voltak a mindennapi irodai vagy kisebb szerveres környezetekben. Azonban az adatmennyiség robbanásszerű növekedése és a komplex számítási modellek megjelenése alapjaiban rengette meg ezeknek a rendszereknek a stabilitását és teljesítményét.
Az NFS és SMB például egyetlen szerveren keresztül szolgálja ki a kéréseket, ami hamar szűk keresztmetszetté válik, ha több száz vagy ezer kliens próbál egyszerre hozzáférni ugyanazokhoz az adatokhoz. A hálózati késleltetés és a szerver I/O képességei korlátozzák az átviteli sebességet, és a skálázhatóság lineáris növelése szinte lehetetlenné válik. Egy ponton túl hiába növeljük a sávszélességet vagy a szerver erőforrásait, a rendszer egyszerűen nem képes lépést tartani a párhuzamos I/O igényekkel.
A Storage Area Network (SAN) rendszerek, amelyek blokkszinten biztosítanak hozzáférést a tárolóeszközökhöz, jobb teljesítményt nyújtanak, de még ezek is korlátokba ütköznek a nagyméretű, egyidejű hozzáféréseknél. A SAN-ok jellemzően egyetlen vezérlőn vagy egy aktív-passzív páron keresztül kezelik a kéréseket, ami szintén egy ponton szűk keresztmetszetté válhat. Emellett a SAN-ok komplexitása és magas költségei sem teszik őket ideális megoldássá minden nagyméretű adatközpont számára, különösen ott, ahol a költséghatékony skálázhatóság a cél.
A modern alkalmazások, mint például egy klímamodellező szimuláció, vagy egy mélytanulási modell képzése, nem csupán hatalmas adatmennyiséget generálnak, hanem rendkívül magas párhuzamos I/O teljesítményt is igényelnek. Ez azt jelenti, hogy több ezer processzormag vagy GPU dolgozik egyszerre ugyanazokon az adatokon, vagy éppen új adatokat írnak a tárolóra. Ebben a forgatókönyvben a hagyományos fájlrendszerek egyszerűen összeomlanak, vagy olyan lassúvá válnak, hogy a számítási feladatok napokig, hetekig tartanak, ami gazdaságilag és tudományosan is fenntarthatatlan.
„A Big Data és az AI forradalma nemcsak a feldolgozási teljesítményt, hanem a tárolási infrastruktúra I/O képességeit is a végletekig feszegeti, megteremtve a párhuzamos fájlrendszerek iránti elengedhetetlen igényt.”
A párhuzamosság iránti igény nem csupán a sebességről szól, hanem a skálázhatóságról és a megbízhatóságról is. Egy petabájtos adatkészletet nem lehet hatékonyan kezelni egyetlen szerverről vagy SAN rendszerről. Szükség van egy olyan architektúrára, amely képes elosztani az adatokat több száz vagy ezer tárolóeszköz között, és lehetővé teszi, hogy ezekhez az eszközökhöz egyszerre, párhuzamosan férjenek hozzá a számítási csomópontok. Ez a felismerés vezetett a párhuzamos fájlrendszerek kifejlesztéséhez, amelyek képesek kezelni ezt a hihetetlenül nagy adatforgalmat és a komplex hozzáférési mintázatokat.
Mi az a párhuzamos fájlrendszer?
A párhuzamos fájlrendszer (PFS) egy olyan elosztott tárolási architektúra, amelyet kifejezetten a rendkívül nagy adatmennyiségű és I/O-intenzív számítási feladatok támogatására terveztek. Alapvető célja, hogy több szerver, több tárolóeszköz és több kliens egyidejűleg, koordináltan férhessen hozzá ugyanahhoz az adatkészlethez, egyetlen, koherens névtér alatt.
Ellentétben a hagyományos hálózati fájlrendszerekkel, amelyek egy központi szerveren keresztül irányítják az adatforgalmat, a PFS rendszerek az adatokat és a metaadatokat is elosztják több szerver között. Ezáltal a rendszer képes a teljes I/O sávszélességet és az IOPS (Input/Output Operations Per Second) teljesítményt összeadni, amelyet a mögöttes tárolóeszközök és szerverek nyújtanak. Ez a megközelítés lehetővé teszi a lineáris skálázhatóságot, ami azt jelenti, hogy a rendszer teljesítménye és kapacitása arányosan nő a hozzáadott erőforrásokkal.
A párhuzamos fájlrendszerek legfontosabb jellemzője a globális névtér. Ez azt jelenti, hogy minden csatlakoztatott kliens ugyanazt a fájlrendszer-struktúrát látja, függetlenül attól, hogy melyik szerverről vagy tárolóegységről származik az adat. A felhasználók számára az egész rendszer egyetlen logikai tárolóként jelenik meg, ami jelentősen leegyszerűsíti az adatok kezelését és elérését.
A technológia a párhuzamos adatátvitelre épül. Amikor egy kliens egy nagy fájlt olvas vagy ír, az adatot nem egyetlen szerverről kapja vagy egyetlen szerverre küldi, hanem az több tárolóeszközre van felosztva (csíkozás, stripping), és ezekhez az eszközökhöz egyszerre, párhuzamosan fér hozzá. Ez a megközelítés drámaian megnöveli az adatátviteli sebességet, és csökkenti a késleltetést, ami kritikus fontosságú a nagyméretű adatfolyamok és a valós idejű feldolgozás során.
A PFS-ek alapvető célja tehát nem csupán a kapacitás növelése, hanem a teljesítmény maximalizálása is, különösen azokban a környezetekben, ahol több ezer processzormag vagy GPU dolgozik egyszerre. Ez a technológia teszi lehetővé, hogy a legmodernebb szuperszámítógépek, AI klaszterek és Big Data platformok képesek legyenek kihasználni teljes számítási potenciáljukat, anélkül, hogy az I/O alrendszer szűk keresztmetszetté válna.
A párhuzamos fájlrendszerek működési elvei
A párhuzamos fájlrendszerek működésének megértéséhez kulcsfontosságú néhány alapvető elv megismerése. Ezek az elvek biztosítják a rendszer rendkívüli teljesítményét, skálázhatóságát és megbízhatóságát.
Adatcsíkozás (data stripping)
Az egyik legfontosabb működési elv az adatcsíkozás. Ez azt jelenti, hogy egy nagy fájlt logikai szegmensekre, úgynevezett „csíkokra” (strips) osztanak fel, és ezeket a csíkokat elosztva tárolják több, független tárolóeszközön, vagy „objektumtároló-szerveren” (OSS). Amikor egy kliens olvasni vagy írni szeretne egy fájlt, a művelet nem egyetlen tárolóeszközre irányul, hanem párhuzamosan történik több OSS felé. Ezzel a technikával a rendszer képes kihasználni az összes mögöttes tárolóegység együttes sávszélességét és IOPS teljesítményét, drámaian megnövelve az adatátviteli sebességet.
Képzeljünk el egy videófájlt, amely több gigabájtos méretű. Ahelyett, hogy egyetlen merevlemezen tárolnánk, a PFS felosztja a fájlt kisebb darabokra, és ezeket a darabokat különböző szerverekhez csatlakoztatott lemezekre menti. Amikor a videót lejátszuk, a különböző darabok egyszerre érkeznek be a klienstől, jelentősen felgyorsítva a betöltési és lejátszási folyamatot. Ez a módszer elengedhetetlen a magas átviteli sebesség eléréséhez.
Elosztott metaadat-kezelés
A fájlrendszerek nem csak az adatokról, hanem a metaadatokról is szólnak. A metaadatok olyan információkat tartalmaznak, mint a fájl neve, mérete, létrehozásának dátuma, tulajdonosa, jogosultságok, és ami a legfontosabb, a fájl fizikai elhelyezkedése a tárolóeszközökön. Hagyományos rendszerekben a metaadatokat egyetlen szerver kezeli, ami könnyen szűk keresztmetszetté válhat, különösen sok kis fájl esetén.
A párhuzamos fájlrendszerekben a metaadat-kezelés is elosztott. Egy vagy több metaadat-szerver (MDS) felelős a fájlrendszer struktúrájának karbantartásáért. Amikor egy kliens egy fájlhoz szeretne hozzáférni, először az MDS-sel kommunikál, amely megadja a fájl fizikai elhelyezkedésére vonatkozó információkat (melyik OSS-en, melyik csíkon található). Ez az elosztott megközelítés biztosítja, hogy a metaadat-műveletek is hatékonyan, párhuzamosan történjenek, elkerülve a központi vezérlő túlterhelését.
Több I/O út
A PFS rendszerek alapvetően arra épülnek, hogy a kliensek és a tárolóeszközök között több független adatút létezik. Ahelyett, hogy minden adatforgalom egyetlen hálózati kapcsolaton vagy egyetlen szerverprocesszoron keresztül haladna, a kliensek közvetlenül kommunikálhatnak több objektumtároló-szerverrel. Ez a képesség lehetővé teszi, hogy több kliens egyidejűleg, különböző adatfolyamokon keresztül olvasson vagy írjon, maximalizálva az elérhető hálózati és tárolási erőforrásokat. Ez a valódi párhuzamosság alapja, amely megkülönbözteti a PFS rendszereket a hagyományos megoldásoktól.
Globális névtér (global namespace)
A globális névtér egy kritikus elv, amely a felhasználói élményt és a kezelhetőséget egyszerűsíti. Bár az adatok fizikailag több tucat vagy akár több száz szerveren és tárolóeszközön oszlanak el, a kliensek számára a teljes rendszer egyetlen, egységes fájlrendszerként jelenik meg. Nincs szükség arra, hogy a felhasználók tudják, melyik szerveren melyik fájldarab található; egyszerűen csak hozzáférnek a kívánt fájlhoz a megszokott elérési útvonalon keresztül. Ez a transzparencia jelentősen leegyszerűsíti az alkalmazások fejlesztését és a rendszer adminisztrációját.
Kliens-szerver architektúra
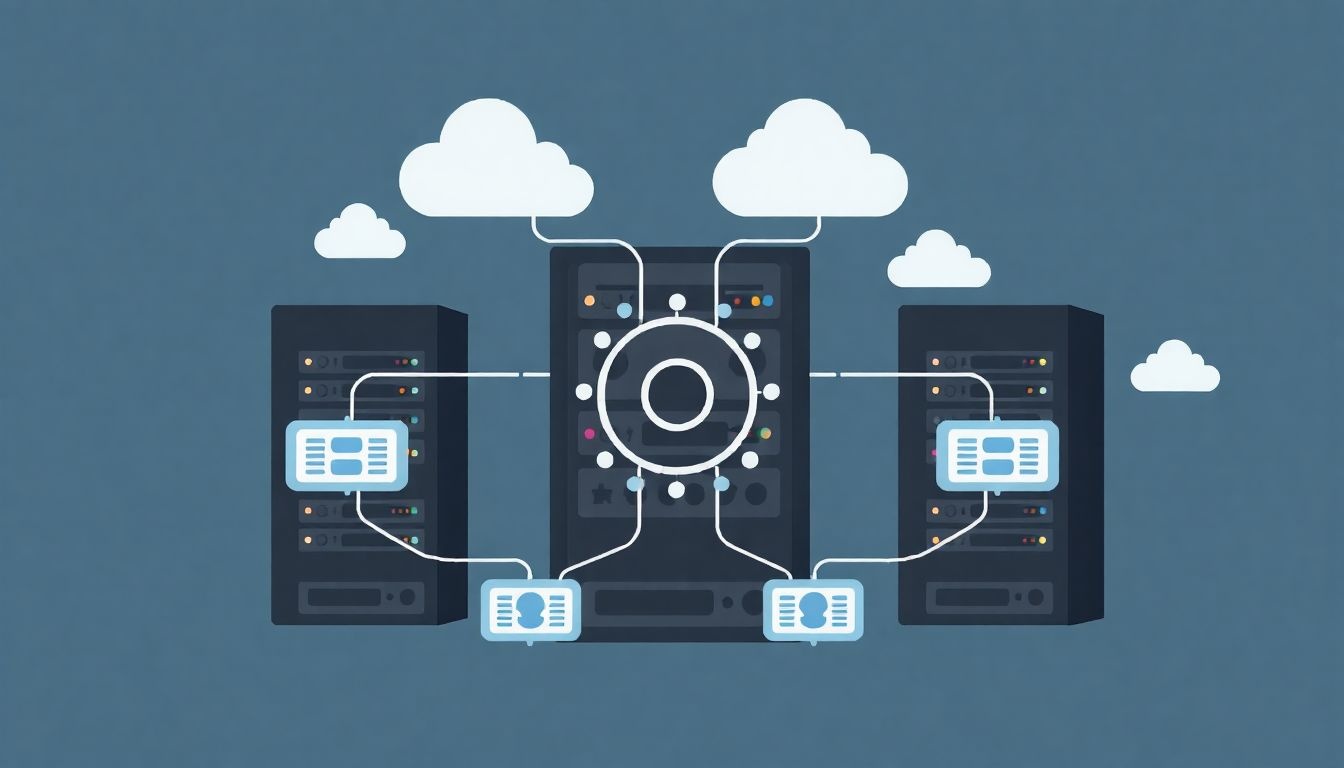
A párhuzamos fájlrendszerek tipikusan egy kliens-szerver architektúrát követnek, amelyben a szerepek világosan el vannak választva. A kliensek a számítási csomópontok, amelyek hozzáférnek az adatokhoz. Ezek rendelkeznek egy speciális PFS kliens szoftverrel, amely lehetővé teszi számukra, hogy kommunikáljanak a metaadat-szerverekkel és az objektumtároló-szerverekkel. A szerver oldalon találhatóak az MDS-ek (metadata servers) és az OSS-ek (object storage servers), amelyek a fájlrendszer logikáját és az adatok fizikai tárolását biztosítják. Ez a moduláris felépítés hozzájárul a rendszer skálázhatóságához és hibatűrő képességéhez.
Összességében ezek az elvek együttesen teszik lehetővé, hogy a párhuzamos fájlrendszerek képesek legyenek kezelni a modern adatintenzív feladatok támasztotta rendkívüli igényeket, biztosítva a páratlan teljesítményt és rugalmasságot.
A párhuzamos fájlrendszerek architektúrájának kulcsfontosságú elemei

A párhuzamos fájlrendszerek összetett rendszerek, amelyek számos komponensből épülnek fel, melyek mindegyike specifikus feladatot lát el a teljesítmény, skálázhatóság és megbízhatóság biztosítása érdekében. Az alábbiakban bemutatjuk a legfontosabb építőelemeket.
Kliensek
A kliensek azok a számítási csomópontok (szerverek, munkaállomások, virtuális gépek, konténerek), amelyek hozzáférnek a párhuzamos fájlrendszerhez. Minden kliensen fut egy speciális szoftver, amely lehetővé teszi a közvetlen kommunikációt a fájlrendszer szerverkomponenseivel. Ez a kliensszoftver felelős a fájlrendszer globális névtérének megjelenítéséért, a metaadat-kérések továbbításáért a metaadat-szerverek felé, és az adatok közvetlen olvasásáért/írásáért az objektumtároló-szerverekkel.
A kliensek tipikusan magas sávszélességű hálózati kapcsolattal rendelkeznek, mint például InfiniBand, RoCE (RDMA over Converged Ethernet) vagy 100GbE, hogy maximalizálják az adatátviteli sebességet és minimalizálják a késleltetést. A kliensoldali gyorsítótárazás (caching) is gyakori, hogy csökkentse a hálózati I/O-t és tovább növelje az alkalmazások teljesítményét a gyakran hozzáférő adatok esetében.
Metaadat-szerverek (MDS)
A metaadat-szerverek (MDS) a párhuzamos fájlrendszer agyát képezik. Fő feladatuk a fájlrendszer struktúrájának, azaz az összes fájl és könyvtár metaadatainak kezelése. Ide tartozik a fájlok neve, mérete, tulajdonosa, jogosultságai, időbélyegei, és ami a legfontosabb, a fájlok fizikai elhelyezkedésére vonatkozó információk – melyik objektumtároló-szerveren (OSS) és milyen csíkozással (striping) találhatók az adatok.
Az MDS-ek nem tárolják magukat az adatokat, csak az adatokra mutató hivatkozásokat. Egyetlen fájlrendszer több MDS-t is tartalmazhat, amelyek elosztott vagy klaszteres konfigurációban működnek a magas rendelkezésre állás és a skálázhatóság érdekében. A modern PFS rendszerekben az MDS-ek gyakran SSD-ket vagy NVMe meghajtókat használnak a metaadat-műveletek rendkívül gyors kiszolgálásához, mivel a metaadat-hozzáférés gyakran a leggyakoribb művelet.
„A metaadat-szerverek optimalizálása kulcsfontosságú a párhuzamos fájlrendszerek teljesítményéhez, hiszen ők irányítják az adatforgalmat és biztosítják a koherens névtér működését.”
Objektumtároló-szerverek (OSS) / Adatszerverek
Az objektumtároló-szerverek (OSS), más néven adatszerverek, az adatok tényleges tárolásáért felelnek. Ezek a szerverek tartalmazzák a merevlemezeket (HDD-ket) vagy SSD-ket, amelyekre a fájlok adatai vannak felcsíkozva. Minden OSS számos tárolóeszközhöz csatlakozik, és képes az adatok olvasására és írására a kliensek kérése alapján. Az OSS-ek is hálózaton keresztül kommunikálnak a kliensekkel, közvetlenül, a metaadat-szerverek megkerülésével az adatátviteli fázisban.
A rendszer skálázhatósága nagymértékben függ az OSS-ek számától. Minél több OSS van, annál több tárolóeszköz és annál nagyobb együttes sávszélesség áll rendelkezésre. Az OSS-ek konfigurációja gyakran tartalmaz RAID tömböket vagy más adatvédelmi mechanizmusokat a hibatűrő képesség növelése érdekében. Néhány PFS rendszerben az OSS-ek úgynevezett „objektumokat” tárolnak, amelyek a fájlok csíkjai, és ezeket egy egyedi azonosítóval (OID) látják el.
Hálózati infrastruktúra
A hálózati infrastruktúra a párhuzamos fájlrendszer gerincét képezi, és kritikus fontosságú a rendszer teljesítménye szempontjából. A nagy teljesítményű, alacsony késleltetésű hálózatok, mint az InfiniBand, a RoCE (RDMA over Converged Ethernet), vagy a 100 Gigabit Ethernet (100GbE), elengedhetetlenek az adatok gyors és hatékony mozgatásához a kliensek, az MDS-ek és az OSS-ek között.
Az InfiniBand és a RoCE különösen fontos a HPC környezetekben, mivel támogatják az RDMA (Remote Direct Memory Access) technológiát. Az RDMA lehetővé teszi, hogy az adatok közvetlenül a hálózati kártya és a memória között mozogjanak, megkerülve a CPU-t és az operációs rendszer kernelét, ezzel jelentősen csökkentve a késleltetést és a CPU terhelését. Ez a képesség teszi lehetővé a rendkívül magas I/O teljesítményt, amelyet a modern párhuzamos fájlrendszerek nyújtanak. A hálózatot úgy kell tervezni, hogy elegendő sávszélességet biztosítson a maximális párhuzamos adatforgalomhoz, elkerülve a szűk keresztmetszeteket.
Ezen komponensek harmonikus együttműködése teszi lehetővé a párhuzamos fájlrendszerek számára, hogy a hagyományos tárolási megoldásokhoz képest nagyságrendekkel nagyobb teljesítményt és skálázhatóságot nyújtsanak, kielégítve a legigényesebb adatintenzív alkalmazások szükségleteit.
Részletes működés: Olvasási és írási műveletek
A párhuzamos fájlrendszerek igazi ereje abban rejlik, ahogyan az olvasási és írási műveleteket kezelik, kihasználva a párhuzamosságot és az elosztott architektúrát. Nézzük meg részletesebben, hogyan zajlanak ezek a kritikus folyamatok.
Fájlnyitás és metaadat-lekérdezés
Amikor egy kliens alkalmazás egy fájlhoz szeretne hozzáférni (olvasás vagy írás céljából), az első lépés mindig a fájlnyitás. Ebben a fázisban a kliens szoftver nem közvetlenül az adatszerverekkel kommunikál, hanem a metaadat-szerverrel (MDS). A kliens elküldi a fájl elérési útvonalát az MDS-nek, amely megkeresi a fájlhoz tartozó metaadatokat.
A metaadatok tartalmazzák a fájl nevét, méretét, tulajdonosát, jogosultságait, és ami a legfontosabb, azt az információt, hogy a fájl adatai melyik objektumtároló-szervereken (OSS) és milyen csíkozási mintázatban (striping pattern) vannak elhelyezve. Az MDS ellenőrzi a kliens jogosultságait is a fájlhoz való hozzáférésre. Ha minden rendben van, az MDS visszaküldi ezeket a metaadatokat a kliensnek.
Ez a lépés rendkívül gyors, mivel az MDS-ek jellemzően gyors SSD-ken vagy NVMe meghajtókon tárolják a metaadatokat, és optimalizált algoritmusokat használnak a kereséshez. A metaadat-lekérdezés eredményeként a kliens pontosan tudja, melyik OSS-ekhez kell fordulnia, és milyen módon kell szegmentálnia vagy összeállítania az adatokat.
Adatolvasás
Miután a kliens megkapta a metaadatokat az MDS-től, elindul az adatolvasási fázis. A kliens szoftver a kapott információk alapján közvetlenül kommunikál azokkal az OSS-ekkel, amelyek a kért fájl adatcsíkjait tárolják. A kliens párhuzamosan kezdeményez olvasási kéréseket az összes érintett OSS felé, kérve a releváns adatcsíkokat.
Az OSS-ek a kéréseket feldolgozzák, és a kért adatdarabokat közvetlenül a kliensnek küldik, kihasználva a nagy sávszélességű hálózati kapcsolatot (pl. InfiniBand RDMA). A kliens szoftver feladata, hogy az összes beérkező adatcsíkot a megfelelő sorrendben és pozícióban összeállítsa a memóriájában, rekonstruálva az eredeti fájlt. Ez a párhuzamos adatfolyam az, ami drámaian megnöveli az olvasási teljesítményt, lehetővé téve a gigabájtok, vagy akár terabájtok másodpercenkénti átvitelét.
Fájlírás
A fájlírási művelet hasonlóan zajlik, de fordított sorrendben. Amikor a kliens egy új fájlt szeretne létrehozni vagy egy meglévőt módosítani, először szintén az MDS-sel kommunikál. Új fájl esetén az MDS kioszt egy egyedi fájlazonosítót, és meghatározza a csíkozási stratégiát (melyik OSS-eken, milyen méretű csíkokban tárolódjanak az adatok). Ezután az MDS létrehozza a fájl metaadat-bejegyzését, amely tartalmazza a fájl nevét és az OSS-ekre vonatkozó információkat.
Miután a kliens megkapta a csíkozási információkat az MDS-től, elkezdi az adatokat felosztani a meghatározott csíkokra. Ezeket a felosztott adatcsíkokat ezután párhuzamosan küldi el a megfelelő OSS-eknek a hálózaton keresztül. Minden OSS a saját feladata, hogy a hozzá érkező adatcsíkokat a hozzá csatlakoztatott tárolóeszközökre írja. Az adatátvitel itt is közvetlenül a kliens és az OSS-ek között történik, maximalizálva az írási sávszélességet.
Cache-koherencia és zárolás
Az elosztott környezetben az adatkonzisztencia és a cache-koherencia biztosítása kritikus kihívás. Mivel több kliens is hozzáférhet ugyanahhoz a fájlhoz vagy annak részeihez, szükséges valamilyen mechanizmus, amely megakadályozza az adatok sérülését vagy az inkonzisztens állapotokat. Erre szolgálnak a zárolási mechanizmusok és a cache-koherencia protokollok.
Amikor egy kliens írni kezd egy fájlba, a PFS rendszer általában zárolja a fájl érintett részeit, hogy megakadályozza más kliensek egyidejű írását ugyanazon a területen. Az olvasási műveletek általában megengedettek maradnak, de a rendszer biztosítja, hogy a kliensek mindig a legfrissebb adatokat lássák. Ez gyakran a kliens oldali gyorsítótárak invalidálásával vagy frissítésével történik, amikor egy másik kliens módosítja az adatokat. Az MDS-ek kulcsszerepet játszanak ebben a koordinációban, figyelemmel kísérve a zárolásokat és a cache állapotokat.
Ezek a komplex mechanizmusok biztosítják, hogy a párhuzamos fájlrendszerek ne csak gyorsak és skálázhatók legyenek, hanem megbízhatóak és adatintegritás szempontjából is biztonságosak maradjanak, még a leginkább terhelt környezetekben is.
A párhuzamos fájlrendszerek előnyei
A párhuzamos fájlrendszerek bevezetése jelentős előnyökkel jár a modern, adatintenzív környezetekben. Ezek az előnyök teszik őket nélkülözhetetlenné a HPC, AI és Big Data alkalmazások számára.
Páratlan teljesítmény
A párhuzamos fájlrendszerek legkézenfekvőbb és legfontosabb előnye a páratlan teljesítmény. Az adatok több szerverre és tárolóeszközre való elosztásával, valamint a párhuzamos I/O utakkal a rendszer képes aggregálni az összes komponens sávszélességét és IOPS teljesítményét. Ez azt jelenti, hogy a hagyományos fájlrendszerekhez képest nagyságrendekkel nagyobb átviteli sebességet és I/O művelet/másodperc (IOPS) számot érhet el. Ez kritikus fontosságú olyan feladatoknál, mint a nagyméretű adatkészletek gyors betöltése, a komplex szimulációk eredményeinek írása, vagy a valós idejű adatelemzés.
Kiváló skálázhatóság
A PFS rendszerek alapvetően lineárisan skálázhatók, mind kapacitás, mind teljesítmény tekintetében. Ez azt jelenti, hogy a tárolási kapacitás és az I/O teljesítmény egyszerűen növelhető új objektumtároló-szerverek (OSS) és tárolóeszközök hozzáadásával. Az architektúra inherent módon támogatja az erőforrások dinamikus bővítését anélkül, hogy a meglévő rendszert le kellene állítani vagy jelentős átkonfigurálásra lenne szükség. Ez a rugalmasság lehetővé teszi a szervezetek számára, hogy az igényeiknek megfelelően növeljék vagy csökkentsék a tárolási infrastruktúrájukat.
Fokozott megbízhatóság és adatvédelem
A párhuzamos fájlrendszerek inherent módon magasabb megbízhatóságot és hibatűrő képességet kínálnak, mint a legtöbb hagyományos fájlrendszer. Mivel az adatok több komponensre oszlanak el, egyetlen szerver vagy tárolóeszköz meghibásodása általában nem okozza a teljes rendszer leállását vagy adatvesztést. A rendszerek gyakran használnak redundancia mechanizmusokat, mint például RAID tömböket az OSS-eken belül, vagy elosztott paritásos kódolást az adatok között, hogy biztosítsák az adatok integritását és elérhetőségét még hardverhibák esetén is. A metaadat-szerverek is klaszteres konfigurációban működhetnek, garantálva a metaadat-szolgáltatás folyamatos elérhetőségét.
Egyszerűsített kezelés
Bár a mögöttes architektúra komplex, a felhasználók és az alkalmazások számára a párhuzamos fájlrendszer egy egyetlen, egységes logikai egységként jelenik meg, az úgynevezett globális névtérnek köszönhetően. Ez nagymértékben leegyszerűsíti az adatok kezelését, mivel a felhasználóknak nem kell tudniuk, hol tárolódnak fizikailag az adataik. Az adminisztrátorok számára is egyszerűbb a rendszer felügyelete és karbantartása, mivel a teljes tárolási infrastruktúra egyetlen pontról kezelhető.
Költséghatékonyság
Hosszú távon a párhuzamos fájlrendszerek költséghatékonyabbak lehetnek, mint a dedikált, drága SAN megoldások. Mivel a PFS rendszerek gyakran standard, kereskedelmi forgalomban kapható szervereken és tárolóeszközökön futnak, az induló beruházási költségek alacsonyabbak lehetnek. A skálázhatóság azt is jelenti, hogy a szervezetek csak annyi erőforrást vásárolnak, amennyire aktuálisan szükségük van, és később bővíthetik a rendszert, elkerülve a túlméretezést és a felesleges kiadásokat. Az elosztott architektúra emellett lehetővé teszi a nagyobb kihasználtságot és az erőforrások hatékonyabb elosztását.
Rugalmasság
A párhuzamos fájlrendszerek rendkívül rugalmasak, és számos különböző alkalmazási területen használhatók. Támogatják a POSIX-kompatibilis fájlrendszer-interfészeket, ami azt jelenti, hogy a legtöbb meglévő alkalmazás módosítás nélkül futtatható rajtuk. Emellett képesek kezelni a legkülönfélébb I/O mintázatokat, legyen szó nagyméretű, szekvenciális olvasásokról/írásokról (pl. videófeldolgozás), vagy kis fájlok nagy számú, véletlenszerű hozzáféréséről (bár ez utóbbi kihívást is jelenthet, ahogy látni fogjuk). Ez a rugalmasság teszi őket ideális választássá a komplex és változatos adatintenzív környezetekben.
Ezen előnyök együttesen biztosítják, hogy a párhuzamos fájlrendszerek a modern adatkezelési stratégiák sarokkövévé váljanak, lehetővé téve a szervezetek számára, hogy a lehető legteljesebb mértékben kihasználják az adataikban rejlő potenciált.
Kihívások és megfontolások a párhuzamos fájlrendszerek bevezetésénél
Bár a párhuzamos fájlrendszerek számos előnnyel járnak, bevezetésük és üzemeltetésük nem mentes a kihívásoktól. Fontos, hogy a szervezetek tisztában legyenek ezekkel a tényezőkkel, mielőtt elkötelezik magukat egy ilyen megoldás mellett.
Komplexitás
A párhuzamos fájlrendszerek architektúrája és működése jelentősen komplexebb, mint a hagyományos fájlrendszereké. A tervezés, telepítés, konfigurálás és üzemeltetés magas szintű szakértelmet igényel. Az elosztott metaadat-kezelés, az adatcsíkozási stratégiák, a hálózati infrastruktúra optimalizálása és a cache-koherencia biztosítása mind olyan területek, amelyek mélyreható ismereteket kívánnak. A hibaelhárítás is bonyolultabb lehet egy elosztott rendszerben, ahol több komponens együttes működését kell figyelembe venni.
Költségek
Bár hosszú távon költséghatékonyabbak lehetnek, a párhuzamos fájlrendszerek kezdeti beruházási költségei magasabbak lehetnek. Ez nem csak a hardverre (nagyszámú szerver, tárolóeszköz, nagy sávszélességű hálózati komponensek, mint InfiniBand vagy 100GbE) vonatkozik, hanem a szoftverlicencekre (bizonyos kereskedelmi PFS-ek esetén) és a szükséges szakértelem megszerzésére vagy bérlésére is. A rendszer méretezése és optimalizálása is idő- és erőforrásigényes lehet.
Kis fájlok kezelése (small file problem)
A párhuzamos fájlrendszereket elsősorban a nagyméretű fájlok hatékony kezelésére tervezték, ahol az adatcsíkozás és a párhuzamos I/O utakon keresztüli adatátvitel maximalizálja a teljesítményt. Azonban a kis fájlok nagy számú kezelése (az úgynevezett „small file problem”) jelentős kihívást jelenthet. Minden egyes kis fájlhoz metaadat-művelet szükséges az MDS-en, és minden fájl egyedi zárolást igényelhet. Ha több millió apró fájlhoz kell hozzáférni, a metaadat-szerver könnyen szűk keresztmetszetté válhat, jelentősen rontva a teljesítményt. Néhány PFS rendszer kínál megoldásokat erre a problémára (pl. kis fájlok aggregálása), de ez továbbra is egy fontos szempont a tervezésnél.
Adatkonzisztencia és zárolás
Az elosztott környezetben az adatkonzisztencia és a zárolás fenntartása összetett feladat. A párhuzamos fájlrendszereknek kifinomult mechanizmusokat kell alkalmazniuk annak biztosítására, hogy több kliens egyidejű hozzáférése esetén az adatok integritása megmaradjon, és mindenki a legfrissebb verziót lássa. Ez magában foglalja a megosztott írási zárolásokat, a cache-koherencia protokollokat és a naplózási rendszereket. Ezek a mechanizmusok növelhetik a rendszer overheadjét és komplexitását, és hibás konfiguráció esetén teljesítménycsökkenéshez vagy akár adatsérüléshez is vezethetnek.
„A párhuzamos fájlrendszerek bevezetése egy stratégiai döntés, amely mélyreható tervezést és szakértelmet igényel a maximális előnyök eléréséhez és a potenciális buktatók elkerüléséhez.”
Vendor lock-in és interoperabilitás
Néhány kereskedelmi párhuzamos fájlrendszer specifikus hardverekhez vagy zárt ökoszisztémákhoz kötött, ami vendor lock-inhoz vezethet. Ez korlátozhatja a választási szabadságot a jövőbeni bővítések vagy hardverfrissítések során. Emellett az interoperabilitás más rendszerekkel is kihívást jelenthet. Bár a POSIX-kompatibilitás alapvető, a speciális funkciók vagy az integráció más felhő- vagy Big Data platformokkal további fejlesztést vagy adaptációt igényelhet.
Telepítés és karbantartás
A párhuzamos fájlrendszerek telepítése és karbantartása jelentős erőfeszítést igényel. A rendszer komponenseinek (MDS-ek, OSS-ek, kliensek, hálózat) megfelelő konfigurálása, a szoftverfrissítések kezelése és a teljesítmény monitorozása folyamatos figyelmet igényel. A rendszer optimalizálása a specifikus munkaterhelésekhez (pl. nagy fájlok szekvenciális I/O-ja vs. kis fájlok véletlenszerű I/O-ja) is folyamatos finomhangolást igényelhet.
Ezen kihívások ellenére a párhuzamos fájlrendszerek által kínált előnyök gyakran felülmúlják a nehézségeket, különösen ott, ahol a teljesítmény és a skálázhatóság kritikus fontosságú. A sikeres bevezetéshez azonban alapos tervezésre, megfelelő szakértelemre és a potenciális buktatók tudatos kezelésére van szükség.
Alkalmazási területek: Hol van szükség párhuzamos fájlrendszerekre?
A párhuzamos fájlrendszerek széles körben alkalmazhatók azokban a környezetekben, ahol a hagyományos tárolási megoldások már nem képesek kielégíteni az extrém teljesítmény- és skálázhatósági igényeket. Nézzük meg a legfontosabb területeket, ahol a PFS rendszerek nélkülözhetetlenné váltak.
Nagy teljesítményű számítástechnika (HPC)
A Nagy teljesítményű számítástechnika (HPC) a párhuzamos fájlrendszerek elsődleges alkalmazási területe. A szuperszámítógépek, klaszterek és Grid rendszerek hatalmas mennyiségű adatot generálnak és dolgoznak fel tudományos szimulációk, modellezés és elemzések során. Ilyenek például a klímamodellezés, az anyagtudományi szimulációk, a részecskefizikai kutatások vagy a gyógyszerfejlesztés. Ezek a feladatok gyakran igényelnek több ezer processzormag vagy GPU egyidejű hozzáférését ugyanazokhoz az adatkészletekhez, rendkívül magas I/O sávszélességgel. A PFS rendszerek biztosítják az ehhez szükséges sebességet és skálázhatóságot, elkerülve az I/O szűk keresztmetszeteket, amelyek lelassítanák a komplex számításokat.
Mesterséges intelligencia (AI) és Gépi tanulás (ML)
Az Mesterséges intelligencia (AI) és Gépi tanulás (ML) robbanásszerű fejlődése szintén hatalmas adatigényt támaszt. A mélytanulási modellek képzése során gigabájtos, sőt terabájtos adatkészleteket kell gyorsan betölteni a GPU memóriába. A kép-, videó-, hang- és szöveges adatok feldolgozása során a modellek folyamatosan olvasnak és írnak hatalmas mennyiségű adatot. A párhuzamos fájlrendszerek biztosítják a szükséges magas átviteli sebességet, amely elengedhetetlen a képzési folyamatok felgyorsításához, lehetővé téve a kutatók és fejlesztők számára, hogy nagyobb modelleket és komplexebb adatkészleteket használjanak, rövidebb idő alatt.
Big Data analitika
A Big Data analitika platformok, mint például a Hadoop vagy a Spark klaszterek, szintén profitálnak a párhuzamos fájlrendszerekből. Bár a HDFS (Hadoop Distributed File System) maga is egyfajta párhuzamos fájlrendszer, sok esetben egy külső, POSIX-kompatibilis PFS, mint a Lustre vagy a GPFS, biztosíthatja a szükséges gyorsabb adatelérést és a rugalmasabb integrációt más alkalmazásokkal. A nagyméretű logfájlok, szenzoradatok vagy egyéb strukturálatlan adatok feldolgozása során a PFS rendszerek garantálják, hogy az adatok gyorsan elérhetőek legyenek az analitikai motorok számára, felgyorsítva az adatelemzési ciklusokat.
Média és szórakoztatóipar
A média és szórakoztatóipar is jelentős felhasználója a párhuzamos fájlrendszereknek. A 4K, 8K, vagy akár magasabb felbontású videók szerkesztése, a speciális effektek renderelése, az animációk és a valós idejű streaming szolgáltatások mind óriási sávszélességet igényelnek. Egyetlen nagyfelbontású videófájl is több tíz vagy száz gigabájt lehet, és több szerkesztő vagy renderelő munkaállomásnak kell egyszerre hozzáférnie ehhez az adathoz. A PFS rendszerek biztosítják a szükséges I/O teljesítményt és a megosztott hozzáférést, lehetővé téve a zökkenőmentes munkafolyamatokat és a gyors gyártási ciklusokat.
Tudományos kutatás
A különböző tudományágakban, mint a genomika, az asztrofizika, a geofizika vagy a biológia, a kutatók hatalmas adatkészletekkel dolgoznak, amelyek elemzése és tárolása jelentős kihívást jelent. A genomikai szekvenálás például óriási mennyiségű nyers adatot generál, amelyet gyorsan kell feldolgozni és tárolni. A párhuzamos fájlrendszerek segítik a kutatókat abban, hogy hatékonyabban kezeljék és elemezzék ezeket az adatkészleteket, felgyorsítva a tudományos felfedezéseket.
Felhőalapú környezetek
A felhőalapú környezetekben is egyre nagyobb szerepet kapnak a párhuzamos fájlrendszerek, különösen a nagy teljesítményű számítási és adatelemzési szolgáltatások (HPCaaS, AIaaS) részeként. A felhőszolgáltatók skálázható és rugalmas tárolási megoldásokat kínálnak, amelyek a PFS technológiára épülnek, lehetővé téve az ügyfelek számára, hogy igény szerint skálázzák az I/O teljesítményt és a kapacitást. Ez különösen hasznos a hibrid felhő stratégiákban, ahol a helyi HPC klaszterek és a felhőerőforrások közötti adatmozgatás optimalizálása kulcsfontosságú.
Összességében a párhuzamos fájlrendszerek kulcsfontosságú technológiát jelentenek minden olyan iparágban és kutatási területen, ahol a nagy adatmennyiségek és a rendkívüli I/O igények meghatározóak. Képességük, hogy skálázhatóan és hatékonyan kezeljék ezeket az igényeket, alapvető fontosságúvá teszi őket a jövő adatvezérelt innovációihoz.
Népszerű párhuzamos fájlrendszerek áttekintése
A párhuzamos fájlrendszerek piacán számos megoldás létezik, amelyek különböző architektúrával, funkciókkal és célpiacokkal rendelkeznek. Az alábbiakban bemutatunk néhányat a legnépszerűbb és legelterjedtebb PFS rendszerek közül.
Lustre
A Lustre (Linux Cluster File System) egy nyílt forráskódú, rendkívül skálázható párhuzamos fájlrendszer, amelyet elsősorban a Nagy teljesítményű számítástechnika (HPC) környezetekben használnak. Számos a világ leggyorsabb szuperszámítógépe közül a Lustre-t használja tárolási megoldásként. Architektúrája magában foglalja a Metaadat-szervereket (MDS) a metaadatok kezelésére, és az Objektumtároló-szervereket (OSS) az adatok tárolására, amelyek között a kliensek közvetlenül kommunikálnak. A Lustre kiválóan alkalmas a nagy fájlok szekvenciális olvasására és írására, és rendkívül magas sávszélességet képes elérni.
IBM Spectrum Scale (korábban GPFS)
Az IBM Spectrum Scale, korábbi nevén GPFS (General Parallel File System), az IBM egyik vezető párhuzamos fájlrendszer megoldása. Ez egy vállalati szintű, robusztus PFS, amelyet nem csak HPC környezetekben, hanem Big Data analitikában, felhőalapú tárolásban, média- és szórakoztatóiparban is széles körben alkalmaznak. Az IBM Spectrum Scale híres a magas rendelkezésre állásáról, a fejlett adatkezelési funkcióiról (pl. automatikus tiering, snapshotok, replikáció) és a rugalmas konfigurálhatóságáról. Képes kezelni a fájlok, objektumok és blokkok tárolását egyetlen névtér alatt, és kiválóan teljesít mind a nagy, mind a kis fájlok kezelésében.
Ceph
A Ceph egy nyílt forráskódú, elosztott tárolási platform, amely objektum-, blokk- és fájlrendszer-interfészeket is biztosít. Bár alapvetően objektumtárolásra tervezték (Ceph Object Gateway), a CephFS (Ceph File System) komponens egy POSIX-kompatibilis párhuzamos fájlrendszert kínál. A Ceph ereje a rendkívüli rugalmasságában és a szoftveresen definiált tárolás (SDS) megközelítésében rejlik, amely lehetővé teszi, hogy standard hardvereken futtassák. A CephFS egy elosztott metaadat-kiszolgáló klasztert (MDS) és egy elosztott objektumtároló klasztert (OSD-k) használ. Egyre népszerűbb a felhőalapú és konténerizált környezetekben a skálázhatósága és a hibatűrő képessége miatt.
BeeGFS
A BeeGFS (korábban FhGFS) egy másik népszerű nyílt forráskódú párhuzamos fájlrendszer, amelyet Németországban fejlesztettek ki. Fő jellemzői a könnyűsúlyú felépítés, a modularitás és az egyszerű telepítés. A BeeGFS is Metaadat-szerverekre és Objektumtároló-szerverekre épül, és kiemelkedő teljesítményt nyújt a nagy fájlok kezelésében. Különösen népszerű a kisebb és közepes méretű HPC klaszterekben, ahol az egyszerűség és a hatékonyság kulcsfontosságú. A BeeGFS kliens modulja a Linux kernelbe integrálódik, ami optimalizált teljesítményt biztosít.
HDFS (Hadoop Distributed File System)
Bár nem egy hagyományos POSIX-kompatibilis párhuzamos fájlrendszer, a HDFS (Hadoop Distributed File System) kulcsfontosságú szerepet játszik a Big Data ökoszisztémában. A HDFS a Hadoop keretrendszer alapvető tárolási rétege, amelyet nagy adatkészletek tárolására és feldolgozására terveztek, különösen a MapReduce és a Spark alkalmazások számára. Jellemzői a blokk alapú tárolás, az adatreplikáció a hibatűrő képesség érdekében, és az adatlokalitás (a számítási feladatok az adatok közelében futnak). A HDFS nem kínál globális névtér hozzáférést a hagyományos értelemben, és nem POSIX-kompatibilis, de az elosztott tárolás és a párhuzamos hozzáférés alapelveit alkalmazza a Big Data feladatokhoz.
Ez a rövid áttekintés bemutatja, hogy a párhuzamos fájlrendszerek milyen sokszínűek lehetnek, és hogyan alkalmazkodnak a különböző igényekhez és munkaterhelésekhez. A megfelelő PFS kiválasztása nagyban függ a specifikus alkalmazási területtől, a teljesítményigényektől, a skálázhatósági céloktól és a rendelkezésre álló erőforrásoktól.
A párhuzamos fájlrendszerek jövője és fejlődési irányai
A párhuzamos fájlrendszerek technológiája folyamatosan fejlődik, hogy lépést tartson az adatok növekedésével és az új számítási paradigmákkal. A jövőbeli irányok számos izgalmas innovációt ígérnek, amelyek tovább növelik a teljesítményt, a rugalmasságot és az intelligenciát.
NVMe-oF (NVMe over Fabrics)
Az egyik legfontosabb fejlődési irány az NVMe-oF (NVMe over Fabrics) technológia szélesebb körű integrációja. Az NVMe (Non-Volatile Memory Express) protokoll a flash alapú tárolók (SSD-k, NVMe meghajtók) rendkívüli sebességét hivatott kihasználni, jelentősen csökkentve a késleltetést és növelve az IOPS-t. Az NVMe-oF lehetővé teszi, hogy az NVMe meghajtók hálózaton keresztül legyenek elérhetők, mint egy blokkeszköz. Amikor ezt a technológiát párhuzamos fájlrendszerekkel kombinálják, a rendszer képes lesz a flash tárolók teljes potenciálját kiaknázni, példátlanul alacsony késleltetést és magas I/O teljesítményt biztosítva, ami kritikus az AI/ML és valós idejű analitikai alkalmazások számára.
Perzisztens memória (PMEM)
A perzisztens memória (PMEM), mint például az Intel Optane DC Persistent Memory, egy új tárolási hierarchiát vezet be, amely a DRAM sebességét kombinálja a hagyományos tárolók perzisztenciájával. A PMEM integrálása a párhuzamos fájlrendszerekbe lehetővé teszi, hogy a metaadatok vagy a kritikus, gyakran hozzáférő adatok memória-közeli sebességgel legyenek elérhetők, még áramszünet esetén is. Ez drámaian csökkentheti a késleltetést a metaadat-műveleteknél és a gyorsítótárazásnál, tovább gyorsítva az I/O intenzív feladatokat.
Felhőintegráció és hibrid megoldások
A felhőalapú számítástechnika térnyerésével a párhuzamos fájlrendszerek egyre inkább integrálódnak a felhőplatformokkal. A jövőben várhatóan még több hibrid és multicloud megoldás jelenik meg, ahol a helyi PFS klaszterek zökkenőmentesen működnek együtt a felhőalapú tárolási és számítási szolgáltatásokkal. Ez lehetővé teszi a szervezetek számára, hogy a helyi infrastruktúrájukat kiterjesszék a felhőbe, rugalmasan skálázva az erőforrásokat a változó igények szerint. A felhőben futó PFS instanciák, mint például az AWS FSx for Lustre vagy az Azure HPC Cache, már most is jelzik ezt az irányt.
Konténerizáció és mikroarchitektúrák
A konténerizáció (pl. Docker, Kubernetes) és a mikroarchitektúrák elterjedése új kihívásokat és lehetőségeket teremt a párhuzamos fájlrendszerek számára. A konténerizált alkalmazások dinamikusabb és rugalmasabb tárolási megoldásokat igényelnek. A PFS rendszereknek képesnek kell lenniük arra, hogy perzisztens tárolást biztosítsanak a konténerek számára, és támogassák a dinamikus erőforrás-allokációt és a skálázhatóságot. A jövőben várhatóan még szorosabb integrációra kerül sor a konténer-orkesztrációs platformokkal, lehetővé téve a PFS erőforrások egyszerűbb kezelését és automatizálását.
Adatkezelési intelligencia és automatizálás
A jövő párhuzamos fájlrendszerei egyre intelligensebbé válnak az adatkezelés terén. Ez magában foglalja az automatikus tiering (adatok mozgatása különböző sebességű és költségű tárolórétegek között), a proaktív hibaelhárítást, a teljesítmény-optimalizációt a munkaterhelés alapján, és a beépített biztonsági funkciókat. A gépi tanulási algoritmusok segíthetnek előre jelezni a tárolási igényeket, optimalizálni az adatcsíkozási mintázatokat és javítani az erőforrás-kihasználtságot. Az automatizálás kulcsszerepet játszik majd a komplex rendszerek üzemeltetésének egyszerűsítésében és a TCO (Total Cost of Ownership) csökkentésében.
A párhuzamos fájlrendszerek tehát nem csupán a jelenlegi kihívásokra adnak választ, hanem aktívan formálják a jövő adatvezérelt világának tárolási infrastruktúráját. A folyamatos innováció biztosítja, hogy továbbra is ők maradjanak a legmegfelelőbb megoldás a legigényesebb számítási feladatok és adatközpontok számára.