

A feature engineering a nyers adatok átalakításának és feldolgozásának folyamata, melynek célja, hogy a gépi tanulási algoritmusok számára értékesebb, hatékonyabb bemenetet biztosítson. A nyers adatok gyakran zajosak, hiányosak vagy egyszerűen nem a legmegfelelőbb formátumban állnak rendelkezésre ahhoz, hogy a modellekből a maximumot hozzuk ki.
A feature engineering során a meglévő adatokból új változókat (feature-öket) hozunk létre, illetve a meglévőket alakítjuk át. Ez magában foglalhatja a változók kombinálását, lebontását, skálázását, kódolását, vagy akár domain-specifikus tudás felhasználásával új, releváns jellemzők generálását. Például, egy dátum oszlopból kinyerhetjük az év napját, a hét napját, vagy akár a szezont is, melyek mind hasznos információkat hordozhatnak a modell számára.
A feature engineering elengedhetetlen a gépi tanulási projektek sikeréhez, mert a modell teljesítménye nagymértékben függ a bemeneti adatok minőségétől és relevanciájától. Egy jól megtervezett feature set képes leegyszerűsíteni a modell által megtanulandó mintázatokat, ezáltal növelve a pontosságot, a hatékonyságot és az általánosíthatóságot. Ezzel szemben, rosszul megválasztott vagy hiányzó jellemzők esetén a legfejlettebb algoritmusok sem képesek jó eredményeket elérni.
A feature engineering nem csupán egy előfeldolgozási lépés, hanem egy iteratív folyamat, amely szoros kölcsönhatásban áll a modell választásával és a teljesítmény értékelésével.
A feature engineering nem egy egzakt tudomány; inkább egy művészet, mely a domain-ismeret, a statisztikai érzék és a gépi tanulási algoritmusok mély megértését igényli. A sikeres feature engineeringhez elengedhetetlen az adatok alapos feltárása, a releváns mintázatok azonosítása, és a különböző feature-ök hatásának kísérleti tesztelése.
A megfelelő feature-ök kiválasztása és létrehozása jelentősen befolyásolja a modell komplexitását is. Jól megválasztott jellemzőkkel egyszerűbb modellek is képesek lehetnek kiváló eredményekre, míg a rosszul megválasztott jellemzők a komplexebb modelleket is megzavarhatják.
A Feature Engineering alapelvei és célkitűzései
A Feature Engineering a gépi tanulási modellek teljesítményének kulcsfontosságú eleme. Lényege, hogy a nyers adatokat olyan formába alakítsuk, amely a modellek számára könnyebben értelmezhető és felhasználható. Ez nem csupán az adatok tisztítását jelenti, hanem a jellemzők (feature-ök) létrehozását, kiválasztását és átalakítását is, amelyek a modell számára a leginformatívabbak.
A Feature Engineering célja kettős: egyrészt javítani a modell pontosságát és teljesítményét, másrészt csökkenteni a komplexitást, ezáltal gyorsabbá téve a tanítási folyamatot. Jól megtervezett jellemzőkkel a modellek képesek jobban generalizálni az új adatokra, és elkerülhető a túltanulás (overfitting) problémája.
A Feature Engineering során alkalmazott technikák sokfélék lehetnek. Ide tartozik például a numerikus adatok skálázása (pl. normalizálás, standardizálás), a kategorikus adatok kódolása (pl. one-hot encoding), vagy a dátum-idő adatokból új jellemzők kinyerése (pl. nap, hónap, évszak).
A sikeres Feature Engineering iteratív folyamat, amely a probléma mélyebb megértését, a releváns jellemzők azonosítását és a modell teljesítményének folyamatos értékelését igényli.
Az adatok átalakítása során figyelembe kell venni a modell típusát is. Például, a lineáris modellek jobban teljesítenek a lineárisan szeparálható adatokon, míg a döntési fák kevésbé érzékenyek a jellemzők skálázására. A megfelelő Feature Engineering technikák kiválasztása ezért a probléma és a választott modell sajátosságaitól függ.
Végül, a Feature Engineering nem egy egyszeri feladat, hanem egy folyamatos kísérletezés és finomhangolás. Az új adatok megjelenésével, vagy a modell teljesítményének változásával szükség lehet a jellemzők újraértékelésére és átalakítására.
A Feature Engineering helye a gépi tanulási munkafolyamatban
A Feature Engineering a gépi tanulási munkafolyamat kritikus előfeldolgozási lépése. Közvetlenül befolyásolja a modell teljesítményét, mivel az algoritmusok a rendelkezésre álló adatokból tanulnak. A célja, hogy a nyers adatokat olyan formátumra alakítsuk, ami a gépi tanulási algoritmusok számára könnyebben értelmezhető és hasznosítható.
A folyamat során a szakértők megvizsgálják az adatokat, és eldöntik, mely jellemzők (feature-ök) a legrelevánsabbak a probléma szempontjából. Ezután ezeket a jellemzőket átalakítják, például normalizálják, standardizálják, vagy éppen kombinálják új jellemzők létrehozása érdekében.
A jól megtervezett feature-ök lehetővé teszik, hogy a gépi tanulási modellek gyorsabban és pontosabban tanuljanak, minimalizálva a túltanulás kockázatát.
Például, ha egy webshopban vásárlási előzményeket használunk a vásárlói viselkedés előrejelzésére, a nyers adatok (pl. terméknevek, dátumok) nem közvetlenül használhatók. Ehelyett a Feature Engineering segítségével létrehozhatunk olyan jellemzőket, mint a vásárlások gyakorisága, a kedvenc termékkategóriák, vagy a vásárlások közötti átlagos időtartam. Ezek a strukturált jellemzők sokkal informatívabbak a modell számára.
A Feature Engineering egy iteratív folyamat, amely a modell teljesítményének folyamatos javítására törekszik. A kísérletezés és a domain ismerete elengedhetetlen a sikeres feature-ök létrehozásához.
A Feature Engineering előnyei: Pontosság, teljesítmény és értelmezhetőség javítása

A Feature Engineering kulcsfontosságú szerepet játszik a gépi tanulási modellek teljesítményének javításában. A jól megtervezett jellemzők (feature) nem csupán növelik a modellek pontosságát, hanem jelentősen javítják azok hatékonyságát is.
A pontosság növelése érdekében a feature engineering során olyan új változókat hozunk létre, amelyek jobban megragadják az adatokban rejlő lényegi információkat. Ezáltal a modellek képesek lesznek finomabb összefüggéseket feltárni, és pontosabb előrejelzéseket adni.
A hatékony feature engineering nem csak a modell teljesítményét javítja, hanem az értelmezhetőségét is.
Azáltal, hogy a modellek számára releváns és érthető jellemzőket biztosítunk, könnyebben megérthetjük, hogy a modell miért hoz egy adott döntést. Ez különösen fontos olyan területeken, mint az orvostudomány vagy a pénzügy, ahol a modellek döntéseinek átláthatósága elengedhetetlen.
Emellett a megfelelően kiválasztott és átalakított jellemzők csökkenthetik a modell komplexitását, ami gyorsabb betanítást és kevesebb számítási igényt eredményez. Ez különösen nagy adathalmazok esetén jelentős előnyt jelent.
A Feature Engineering kihívásai: Túltanulás, adatszivárgás és a „fekete doboz” probléma
A Feature Engineering során számos kihívással kell szembenéznünk, melyek közül a túltanulás, az adatszivárgás és a „fekete doboz” probléma a legjelentősebbek közé tartoznak. A túltanulás akkor következik be, amikor a modell túlságosan jól illeszkedik a tanító adatokhoz, és emiatt gyengébben teljesít az új, korábban nem látott adatokon. Ez gyakran a túl sok vagy túl komplex feature használatának eredménye.
Az adatszivárgás egy még alattomosabb probléma. Ez azt jelenti, hogy a modell olyan információkhoz jut a tanítási fázisban, amelyek valójában nem lennének elérhetőek a valós előrejelzések során. Például, ha a célváltozó jövőbeli értékeire vonatkozó információk valamilyen formában bekerülnek a feature-ök közé, az irreálisan jó eredményekhez vezethet a teszt adatokon, de a valós használat során a modell megbukik.
Az adatszivárgás elkerülése érdekében kritikus, hogy a feature engineering lépéseit szigorúan elkülönítsük a tanító és a teszt adatokon, és csak a tanító adatokból származó statisztikákat használjunk az adatok transzformálására.
Végül, a „fekete doboz” probléma a feature engineering során azt jelenti, hogy nem mindig világos, hogy egy adott feature miért javítja (vagy rontja) a modell teljesítményét. Ez különösen igaz a komplex, automatizált feature engineering technikák esetében. Bár az eredmények javulhatnak, a modellek értelmezhetősége csökken, ami megnehezíti a hibák feltárását és a modell finomhangolását. A feature-ök hatásának megértése érdekében a feature importance technikák és a modell interpretációs módszerek alkalmazása elengedhetetlen.
Adattípusok és azok Feature Engineering szempontú kezelése
A feature engineering során az adattípusok megfelelő kezelése kulcsfontosságú a gépi tanulási modellek teljesítményének optimalizálásához. A különböző adattípusok más-más megközelítést igényelnek az átalakítás során.
Numerikus adatok: Ezek lehetnek folytonosak (pl. hőmérséklet) vagy diszkrétek (pl. családtagok száma). A feature engineering itt magában foglalhatja a skálázást (pl. standardizálás, normalizálás), a nemlineáris transzformációkat (pl. logaritmikus, hatványozás), vagy a binning-et (értéktartományokba sorolás). Ezek a technikák segítenek a kiugró értékek kezelésében és a modell stabilitásának növelésében.
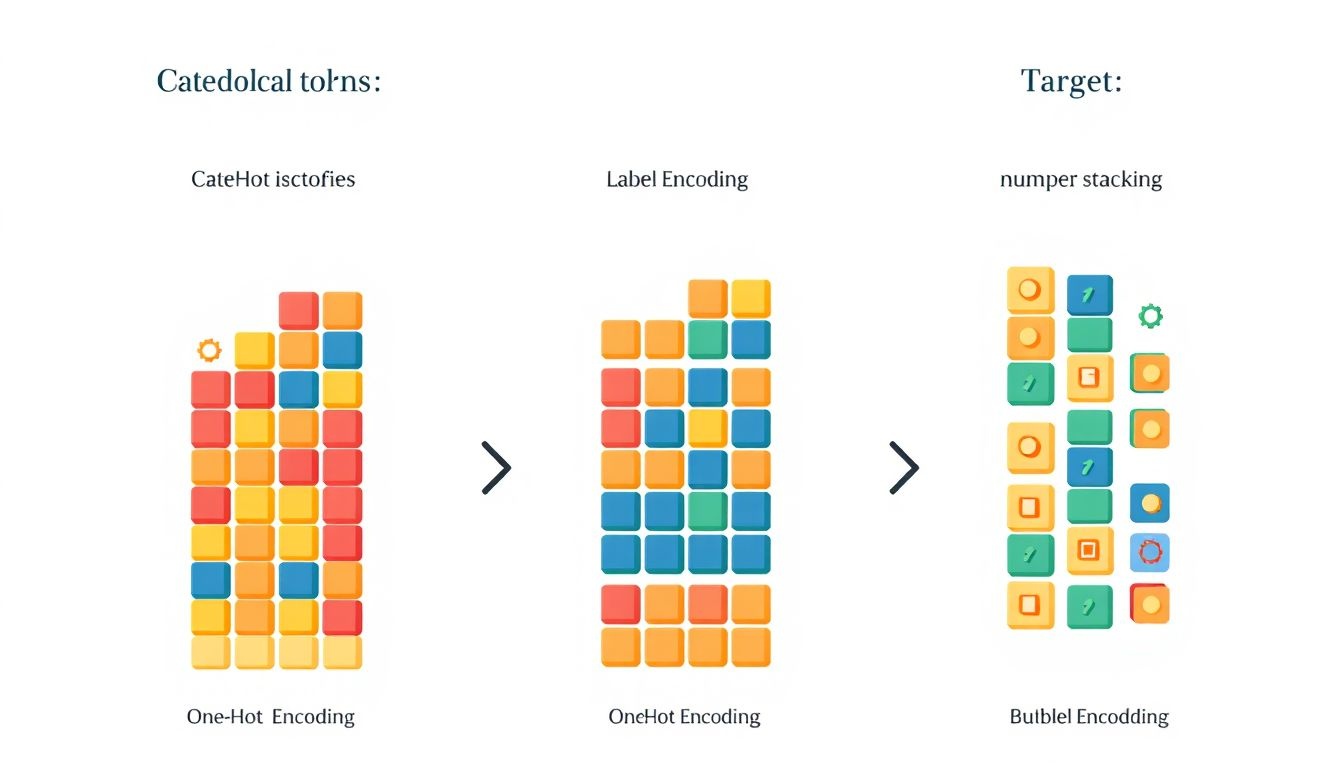
Kategorikus adatok: Ezek az adatok nem numerikus értékeket képviselnek (pl. szín, terméktípus). A leggyakoribb módszer a kategorikus adatok numerikussá alakítására az one-hot encoding, mely minden kategóriához létrehoz egy bináris (0 vagy 1) oszlopot. Egy másik lehetőség a label encoding, ahol minden kategóriához egy egyedi számot rendelünk. Azonban a label encoding használatakor figyelni kell, mert a modell tévesen feltételezhet rendezettséget a kategóriák között.
Szöveges adatok: A szöveges adatok feldolgozása komplexebb feladat. A gyakori technikák közé tartozik a tokenizáció (a szöveg szavakra bontása), a stop word removal (a gyakori, jelentéktelen szavak eltávolítása), a stemming és lemmatizáció (a szavak alapformájának meghatározása), valamint a TF-IDF (term frequency-inverse document frequency) használata, mely a szavak fontosságát méri egy dokumentumban a korpuszhoz viszonyítva.
A megfelelő adattípus-specifikus feature engineering nem csupán javítja a modell pontosságát, hanem segíthet a jobb értelmezhetőségben és a rejtett mintázatok feltárásában is.
Idősor adatok: Az idősor adatok speciális kezelést igényelnek, mivel az időbeli összefüggéseket is figyelembe kell venni. Feature engineering itt magában foglalhatja a trendek és szezonalitás azonosítását, a késleltetett értékek (lagged variables) létrehozását, vagy a mozgóátlagok és exponenciális simítás alkalmazását.
Hiányzó értékek: A hiányzó értékek kezelése is a feature engineering része. A legegyszerűbb megoldás a hiányzó értékek eltávolítása, de ez adatvesztéssel járhat. Alternatív megoldások közé tartozik a hiányzó értékek becslése (imputáció) a középértékkel, mediánnal, vagy egy bonyolultabb modell segítségével.
Numerikus adatok átalakítása: Skálázás, normalizálás és binning
A numerikus adatok átalakítása a feature engineering kritikus lépése, amely közvetlen hatással van a gépi tanulási modellek teljesítményére. Három gyakori technika a skálázás, a normalizálás és a binning, amelyek mindegyike más célt szolgál.
A skálázás célja, hogy a numerikus értékeket egy meghatározott tartományba szorítsa. Ez különösen fontos, ha különböző mértékegységű vagy nagyságrendű adatokkal dolgozunk. A leggyakoribb módszerek közé tartozik a Min-Max skálázás, amely az értékeket 0 és 1 közé transzformálja, és a Standard skálázás (vagy Z-score normalizálás), amely az adatokat úgy alakítja át, hogy átlaguk 0 és szórásuk 1 legyen.
A normalizálás fő célja, hogy az adatok eloszlását megváltoztassa, gyakran azért, hogy közelítsen egy normális eloszláshoz. Ez különösen hasznos lehet olyan algoritmusoknál, amelyek érzékenyek a nem normális eloszlásokra. A normalizálás gyakran magában foglalja az adatok transzformálását, például logaritmikus vagy hatványozási transzformációval.
A skálázás és a normalizálás segíthet elkerülni, hogy bizonyos jellemzők túlságosan domináljanak a modellben, pusztán azért, mert nagyobb értékeket vesznek fel.
A binning, más néven diszkretizálás, a numerikus adatokat kategóriákká vagy „bin”-ekké alakítja. Ez a technika különösen hasznos lehet, ha a numerikus adatok nemlineáris kapcsolatban állnak a célváltozóval, vagy ha zajosak. A binning csökkenti az adatok komplexitását és potenciálisan javíthatja a modell robusztusságát. A bin-ek lehetnek egyenlő szélességűek, vagy az adatok eloszlásához igazodóak (pl. kvantilisek alapján).
Például, tegyük fel, hogy van egy „életkor” nevű jellemzőnk, amely 0 és 100 közötti értékeket vehet fel. Skálázhatjuk ezt a jellemzőt Min-Max skálázással, hogy az értékek 0 és 1 közé essenek. Normalizálhatjuk logaritmikus transzformációval, ha az életkor eloszlása jobbra ferde. Végül, alkalmazhatunk binning-et, hogy az életkorokat korosztályokba soroljuk (pl. 0-18: gyerek, 19-65: felnőtt, 65+: idős).
A megfelelő technika kiválasztása az adatok sajátosságaitól és a használt gépi tanulási algoritmustól függ. Fontos kísérletezni különböző módszerekkel, hogy megtaláljuk a legjobb teljesítményt nyújtó megoldást.
Kategorikus adatok kódolása: One-Hot Encoding, Label Encoding és Target Encoding
A kategorikus adatok kódolása kritikus lépés a feature engineering folyamatában, mivel a gépi tanulási algoritmusok többsége numerikus bemenetet vár. A kategorikus változók, amelyek nem numerikus értékeket tartalmaznak (pl. színek, városok, termékkategóriák), ezért valamilyen numerikus formátumra kell alakítani őket.
Három gyakran használt technika a kategorikus adatok kódolására:
- One-Hot Encoding: Létrehoz egy új bináris (0 vagy 1) oszlopot minden egyes kategória számára a kategorikus változóban. Ha egy adott sorban az eredeti változó értéke megegyezik az oszlop nevével, akkor az adott oszlopban 1 lesz az érték, egyébként 0. Ez a módszer különösen hasznos, ha a kategóriák között nincs természetes sorrend, és szeretnénk elkerülni, hogy a modell feltételezzen valamilyen kapcsolatot a kategóriák között.
- Label Encoding: Minden egyedi kategóriát egy egész számmal helyettesít. Például, ha van egy „Szín” nevű oszlopunk, melynek értékei „Piros”, „Zöld” és „Kék”, akkor ezeket rendre 0, 1 és 2 értékekkel helyettesíthetjük. Ez a módszer egyszerű és gyors, de a modell feltételezhet egy sorrendet a kategóriák között, ami nem feltétlenül helyes.
- Target Encoding: A kategóriákat a célváltozó átlagos értékével helyettesíti az adott kategórián belül. Például, ha a célváltozó a „Vásárlás” (igen/nem), és a „Város” oszlopunkban van egy „Budapest” kategóriánk, akkor a „Budapest” kategóriát azzal az aránnyal helyettesítjük, hogy a Budapesten élők hány százaléka vásárolt. Ez a módszer hatékony lehet, de fennáll a túltanulás veszélye, különösen kis adathalmazok esetén.
A One-Hot Encoding előnye, hogy nem vezet be hamis sorrendet a kategóriák között, de hátránya, hogy jelentősen megnövelheti az adathalmaz dimenzióját, különösen sok kategória esetén. A Label Encoding egyszerű és gyors, de a kategóriák közötti sorrend feltételezése problémás lehet. A Target Encoding hatékony, de a túltanulás kockázatát hordozza magában, amit regularizációs technikákkal lehet kezelni.
A megfelelő kódolási módszer kiválasztása az adathalmaz sajátosságaitól és a gépi tanulási modelltől függ. Fontos figyelembe venni a kategóriák számát, a kategóriák közötti esetleges sorrendet, és a célváltozóval való kapcsolatot.
A kategorikus adatok helyes kódolása elengedhetetlen a gépi tanulási modellek pontosságának és megbízhatóságának biztosításához.
Például, ha egy modellnek városokat kell osztályoznia, a One-Hot Encoding lehet a legjobb választás, mivel nem feltételezünk sorrendet a városok között. Ha viszont egy modellnek termékminőséget kell osztályoznia (pl. „jó”, „közepes”, „rossz”), a Label Encoding megfelelő lehet, mivel a kategóriák között van egy természetes sorrend.
A Target Encoding különösen hasznos lehet olyan esetekben, amikor a kategóriák száma nagy, és a One-Hot Encoding túl sok új oszlopot hozna létre. Azonban fontos a túltanulás elkerülése, például cross-validation technikákkal és regularizációval.
Szöveges adatok Feature Engineeringje: Tokenizálás, TF-IDF és Word Embeddings
A szöveges adatok feature engineeringje elengedhetetlen lépés a természetes nyelvfeldolgozási (NLP) feladatokban. A nyers szöveg önmagában nem alkalmas a gépi tanulási algoritmusok számára, ezért valamilyen numerikus formába kell alakítani. Ezt a folyamatot nevezzük feature engineeringnek, melynek célja olyan jellemzők (feature-ök) létrehozása, amelyek a lehető legjobban reprezentálják a szöveget és a modell számára értelmezhetőek.
Az egyik leggyakoribb technika a tokenizálás. Ez a szöveg kisebb egységekre, úgynevezett tokenekre bontását jelenti. A tokenek általában szavak, de lehetnek mondatok, karakterek vagy akár n-gramok (szavak vagy karakterek sorozatai). A tokenizálás során figyelembe kell venni a speciális karaktereket, írásjeleket és a kis- és nagybetűket is. Például a „The quick brown fox” mondat tokenizálva a következő tokeneket eredményezheti: „The”, „quick”, „brown”, „fox”.
A tokenizálást követően a tokenek gyakoriságát is figyelembe vehetjük. A TF-IDF (Term Frequency-Inverse Document Frequency) egy olyan módszer, amely a szavak gyakoriságát súlyozza azzal, hogy mennyire gyakoriak az adott szó az egész dokumentumhalmazban. A TF (Term Frequency) azt mutatja meg, hogy egy adott szó hányszor fordul elő egy dokumentumban. Az IDF (Inverse Document Frequency) pedig azt, hogy az adott szó mennyire ritka az összes dokumentumban. A TF-IDF értéke a TF és IDF szorzatával egyenlő. Minél magasabb a TF-IDF értéke egy szónak, annál fontosabb az adott szó az adott dokumentumban.
A TF-IDF célja, hogy kiszűrje azokat a gyakori szavakat (pl. „a”, „az”, „és”), amelyek nem hordoznak sok információt, és kiemelje azokat a szavakat, amelyek specifikusak az adott dokumentumra.
Egy másik, modernebb megközelítés a word embeddings használata. A word embeddings olyan vektorreprezentációk, amelyek szavakat rendelnek egy többdimenziós térbe. Ebben a térben a hasonló jelentésű szavak közel helyezkednek el egymáshoz. A legismertebb word embedding modellek közé tartozik a Word2Vec, a GloVe és a FastText. Ezek a modellek nagy mennyiségű szöveges adaton taníthatók, és képesek megragadni a szavak közötti szemantikai kapcsolatokat.
A word embeddings előnye, hogy képesek kezelni a szavak szinonimáit és antonimáit, valamint a szavak közötti egyéb komplex kapcsolatokat. Például, ha a „király” és „királynő” szavak közel helyezkednek el egymáshoz a vektor térben, akkor a modell képes lesz felismerni, hogy ezek a szavak hasonló jelentésűek. A word embeddings használatával a gépi tanulási modellek hatékonyabban képesek feldolgozni a szöveges adatokat és pontosabb eredményeket elérni.
A megfelelő feature engineering technika kiválasztása függ a konkrét feladattól és a rendelkezésre álló adatoktól. Fontos kísérletezni különböző módszerekkel, és kiértékelni a modellek teljesítményét, hogy megtaláljuk a legoptimálisabb megoldást.
Dátum és idő adatok Feature Engineeringje: Időszakok, ciklusok és események kinyerése
A dátum és idő adatok feature engineeringje kulcsfontosságú lépés a gépi tanulási modellek hatékonyságának növelésében, különösen idősoros adatok elemzésekor. A nyers dátum- és időpont információk önmagukban gyakran nem hordoznak elegendő információt a modellek számára. Ezért átalakítjuk őket olyan numerikus vagy kategorikus jellemzőkké, amelyek jobban megragadják az időbeli mintázatokat és ciklusokat.
Az egyik leggyakoribb módszer az időszakok kinyerése. Ez magában foglalja a dátumok felbontását különböző komponensekre, mint például az év, hónap, nap, a hét napja, az óra, perc, másodperc. Ezek a komponensek külön-külön használhatók feature-ként. Például, a hét napja segíthet azonosítani a hétvégi forgalom növekedését egy webáruházban.
A ciklusok azonosítása is kritikus fontosságú. Az időciklusok, mint például a napi, heti, havi vagy éves szezonalitás, jelentős hatással lehetnek az adatokra. A ciklusok kinyerésére trigonometrikus függvényeket (szinusz és koszinusz) használhatunk. Például, egy napi ciklus modellezéséhez a nap óráját átalakíthatjuk egy szinusz- és koszinuszértékké, ami lehetővé teszi a modell számára, hogy megragadja a nap különböző szakaszaiban bekövetkező változásokat.
A trigonometrikus transzformációk előnye, hogy megőrzik az időbeli folytonosságot, ellentétben a kategorikus ábrázolással, ahol például a nap egyes órái közötti kapcsolat elveszne.
Az események, például ünnepnapok, promóciók vagy különleges események, szintén fontos feature-ök lehetnek. Ezeket bináris változókkal (0 vagy 1) reprezentálhatjuk, jelezve, hogy az adott dátumon történt-e az esemény. Az események hatása időben eltolódhat, ezért érdemes késleltetett (lagged) feature-öket is létrehozni, amelyek az eseményt megelőző vagy követő időszakokat is figyelembe veszik.
Például:
- Évszakok: Tavasz, Nyár, Ősz, Tél kategorikus változóként.
- Ünnepnapok: Bináris változóként (1, ha ünnepnap, 0, ha nem).
- Eltelt idő egy esemény óta: Numerikus változóként, napokban vagy órákban mérve.
A megfelelő feature engineering technikák alkalmazásával a dátum- és időadatokból értékes információkat nyerhetünk ki, amelyek jelentősen javíthatják a gépi tanulási modellek teljesítményét.
Hiányzó értékek kezelése a Feature Engineering során
A hiányzó értékek kezelése a feature engineering során kritikus lépés. Ezek az értékek torzíthatják a gépi tanulási modelleket, ezért fontos a megfelelő stratégia kiválasztása.
Számos módszer létezik a hiányzó értékek kezelésére. Az egyik legegyszerűbb a hiányzó értékek törlése. Ezt akkor alkalmazzuk, ha a hiányzó adatok aránya alacsony, és nem befolyásolják jelentősen az eredményeket. Ugyanakkor ez adatvesztéssel jár, ami ronthatja a modell teljesítményét.
Egy másik gyakori módszer az imputálás, amikor a hiányzó értékeket valamilyen statisztikai adattal helyettesítjük. Ez lehet például az adott oszlop átlaga, mediánja vagy módusza. Komplexebb módszerek is léteznek, mint például a K legközelebbi szomszéd (KNN) imputáció, mely a hasonló adatok alapján becsüli meg a hiányzó értéket.
A helyesen megválasztott imputációs stratégia jelentősen javíthatja a modell pontosságát és robusztusságát.
Fontos, hogy az imputációs módszert a konkrét adathalmazhoz és a problémához igazítsuk. Például, idősorok esetén gyakran az előző vagy következő értékkel helyettesítik a hiányzó adatot.
Létrehozhatunk egy új, bináris változót is, amely jelzi, hogy egy adott érték eredetileg hiányzott-e. Ez a módszer különösen akkor hasznos, ha a hiányzásnak önmagában is van jelentősége.
Outlierek (kiugró értékek) kezelése a Feature Engineering során

Az outlierek, vagyis a kiugró értékek jelentős problémát okozhatnak a gépi tanulási modellek teljesítményében. A feature engineering során kiemelt figyelmet kell fordítani a kezelésükre, mivel torzíthatják az eredményeket, különösen érzékeny modellek esetén.
Számos módszer áll rendelkezésünkre az outlierek kezelésére. Az egyik leggyakoribb a csonkolás (trimming), mely során a szélső értékeket egyszerűen eltávolítjuk az adathalmazból. Egy másik lehetőség a helyettesítés (winsorizing), amikor a kiugró értékeket a megadott percentilis értékekre cseréljük. Például, az 1. és 99. percentilis közé szorítjuk az adatokat.
Az outlierek azonosítása történhet statisztikai módszerekkel, például a z-score vagy az IQR (interkvartilis terjedelem) segítségével. Vizualizációs technikák, mint a box plot is segíthetnek a kiugró értékek feltárásában.
A kiugró értékek kezelése nem mindig egyértelmű. Fontos megérteni az outlierek okát. Ha az adatok hibás mérés eredményei, akkor a törlés indokolt lehet. Ha azonban valós, de ritka jelenséget tükröznek, akkor a megtartásuk értékes információt hordozhat.
Néhány esetben a transzformációk, mint például a logaritmikus vagy a négyzetgyök transzformáció, segíthetnek a kiugró értékek hatásának csökkentésében, anélkül, hogy eltávolítanánk őket. A transzformációk segíthetnek az adatok normalizálásában, ami javíthatja a modellek teljesítményét.
Feature kiválasztás: A legfontosabb jellemzők azonosítása
A feature kiválasztás kulcsfontosságú lépés a feature engineering folyamatában, amelynek célja, hogy azonosítsuk a legrelevánsabb jellemzőket a gépi tanulási modellünk számára. Ez a lépés azért kritikus, mert nem minden jellemző egyformán hasznos; egyesek zajt tartalmazhatnak, redundánsak lehetnek, vagy egyszerűen nem befolyásolják a célváltozót.
A feature kiválasztás nem csak a modell teljesítményét javíthatja, hanem csökkentheti a számítási igényt és egyszerűsítheti a modellt, ami könnyebbé teszi az értelmezését és a karbantartását. Többféle módszer létezik a feature kiválasztására:
- Filter módszerek: Ezek a módszerek statisztikai teszteket használnak a jellemzők és a célváltozó közötti kapcsolat erősségének mérésére. Például a korreláció vagy a chi-négyzet teszt.
- Wrapper módszerek: Ezek a módszerek a modell teljesítményét használják a jellemzők halmazának értékelésére. Például a rekurzív feature elimináció (RFE), amely iteratívan távolítja el a legkevésbé fontos jellemzőket.
- Beágyazott módszerek: Ezek a módszerek a modell képzése során automatikusan végzik a feature kiválasztást. Például a L1 regularizáció (Lasso), amely a kevésbé fontos jellemzők együtthatóit nullára kényszeríti.
A megfelelő feature kiválasztási módszer kiválasztása a konkrét problémától és a rendelkezésre álló adatoktól függ. Fontos kísérletezni különböző módszerekkel és értékelni a modell teljesítményét a kiválasztott jellemzőkkel.
A feature kiválasztás célja, hogy megtaláljuk azt a legkisebb jellemzőkészletet, amely a lehető legjobb teljesítményt biztosítja a gépi tanulási modellünk számára.
A feature kiválasztás során figyelembe kell venni a következőket:
- A jellemzők relevanciája: Mennyire kapcsolódik a jellemző a célváltozóhoz?
- A jellemzők redundanciája: Vannak-e olyan jellemzők, amelyek hasonló információt hordoznak?
- A modell komplexitása: A kevesebb jellemző általában egyszerűbb és könnyebben értelmezhető modellt eredményez.
Feature létrehozás: Új jellemzők generálása meglévőkből
A feature létrehozás a feature engineering egyik kulcsfontosságú eleme, amely során a meglévő jellemzőkből új, releváns jellemzőket generálunk. Ennek célja, hogy javítsuk a gépi tanulási modellek teljesítményét és pontosságát.
A nyers adatok gyakran nem közvetlenül alkalmasak a gépi tanulási algoritmusok számára. Lehet, hogy hiányoznak bizonyos információk, vagy az adatok formátuma nem optimális. A feature létrehozás lehetővé teszi, hogy ezeket a hiányosságokat pótoljuk, és az adatokat a modellek számára könnyebben értelmezhetővé tegyük.
Számos módszer létezik a feature létrehozására. Néhány példa:
- Matematikai műveletek: Két vagy több meglévő jellemző kombinálása összeadással, kivonással, szorzással, osztással, vagy más matematikai függvényekkel. Például, ha van egy „bevétel” és egy „költség” jellemzőnk, létrehozhatunk egy „profit” jellemzőt a bevétel és a költség különbségéből.
- Dátum és idő jellemzők: A dátum és idő információkból különböző jellemzőket nyerhetünk ki, például a napot, a hónapot, az évet, a hét napját, vagy az órák számát.
- Szöveges adatok jellemzői: Szöveges adatokból, mint például termékleírásokból vagy vásárlói véleményekből, különböző jellemzőket nyerhetünk ki, például a szavak gyakoriságát, a hangulatot, vagy a kulcsszavakat.
- Bináris jellemzők létrehozása: Egy folytonos változót kategorizálhatunk, létrehozva bináris jellemzőket. Például a felhasználó életkorát egy „fiatal” (0-30), „középkorú” (31-60) és „idős” (61+) kategóriákba sorolhatjuk.
A feature létrehozás során a lényeg, hogy olyan új jellemzőket hozzunk létre, amelyek értékes információt hordoznak a célváltozó szempontjából, és amelyek segítenek a modellnek a jobb előrejelzésben.
A feature létrehozás iteratív folyamat, amely során különböző módszereket próbálunk ki, és értékeljük az eredményeket. A cél az, hogy megtaláljuk azokat a jellemzőket, amelyek a legnagyobb mértékben javítják a modell teljesítményét.
Domain tudás szerepe a Feature Engineeringben
A domain tudás kritikus szerepet játszik a feature engineering során. Anélkül, hogy ismernénk az adatokat generáló területet, nehéz releváns és hatékony jellemzőket létrehozni. A domain tudás segít megérteni az adatok közötti összefüggéseket, a lehetséges torzításokat, és azokat a rejtett mintázatokat, amelyek önmagukban nem lennének nyilvánvalóak.
A szakértői tudás lehetővé teszi, hogy olyan jellemzőket generáljunk, amelyek a gépi tanulási modell számára a leginformatívabbak, és amelyek a leginkább relevánsak a célfeladat szempontjából.
Például, egy orvosi diagnosztikai rendszer fejlesztésekor az orvosi ismeretek elengedhetetlenek ahhoz, hogy a laboratóriumi eredményekből, a beteg kórtörténetéből és a fizikai vizsgálat eredményeiből olyan jellemzőket hozzunk létre, amelyek a betegség pontos azonosításához vezetnek. Egy pénzügyi csalásfelderítő rendszerben a pénzügyi tranzakciók, a felhasználói viselkedés és a piaci trendek ismerete nélkülözhetetlen a csalárd tevékenységek azonosításához.
A domain tudás tehát nem csupán kiegészítő, hanem alapvető a feature engineering sikerességéhez. Segít a megfelelő jellemzők kiválasztásában, a szükségtelen jellemzők elkerülésében és a jellemzők hatékony kombinálásában.
Automatikus Feature Engineering: Eszközök és technikák

Az automatikus feature engineering (AFE) célja, hogy minimalizálja az emberi beavatkozást a feature engineering folyamatában. Számos eszköz és technika létezik, amelyek automatikusan generálnak új jellemzőket a nyers adatokból.
Az egyik megközelítés a gépi tanulási modellek használata a feature-ök kiválasztására és kombinálására. Például, genetikus algoritmusok alkalmazhatók a legjobb jellemzőkombinációk megtalálására, amelyek maximalizálják a modell teljesítményét. Ezek az algoritmusok iteratívan generálnak, értékelnek és kombinálnak különböző jellemzőket, hogy megtalálják az optimális készletet.
Másik népszerű technika a mélytanulás alkalmazása a feature reprezentációk automatikus megtanulására. Például, autoencoderek használhatók a nyers adatok tömör, alacsony dimenziós reprezentációinak megtanulására, amelyek aztán használhatók a gépi tanulási modellek betanításához.
Számos szoftvercsomag és könyvtár is létezik, amelyek támogatják az AFE-t. Ilyenek például az Featuretools, amely automatikusan generál új jellemzőket relációs adatbázisokból, vagy a TPOT, amely automatikusan optimalizálja a gépi tanulási folyamatot, beleértve a feature engineeringet is.
Az AFE lehetővé teszi a gépi tanulási szakértők számára, hogy a modellépítésre és a problémamegoldásra koncentráljanak, ahelyett, hogy manuálisan hoznának létre új jellemzőket.
Az automatikus feature engineering előnyei közé tartozik a gyorsabb fejlesztési idő, a nagyobb pontosság és a kevesebb emberi hiba. Azonban fontos megjegyezni, hogy az AFE nem helyettesíti teljesen az emberi szakértelmet. A domain tudás továbbra is elengedhetetlen a releváns és értelmes jellemzők kiválasztásához és értelmezéséhez.
Az AFE eszközök és technikák folyamatosan fejlődnek, és egyre fontosabb szerepet játszanak a gépi tanulási projektekben. A megfelelő eszközök és technikák kiválasztása a konkrét problémától és az elérhető adatoktól függ.
Feature Engineering Python könyvtárakkal: Scikit-learn, Pandas és Featuretools
A Feature Engineering a nyers adatok átalakításának kulcsfontosságú folyamata a gépi tanulásban. A Python nyelv ehhez számos hatékony könyvtárat kínál, mint például a Scikit-learn, a Pandas és a Featuretools.
A Scikit-learn elsősorban a numerikus adatok kezelésére és transzformálására specializálódott. Olyan eszközöket biztosít, mint a StandardScaler a normalizáláshoz, a PolynomialFeatures a nemlineáris összefüggések feltárásához, és a OneHotEncoder a kategorikus változók kódolásához. Ezek a transzformációk elősegítik a modellek jobb teljesítményét.
A Pandas a strukturált adatok elemzésére és manipulálására szolgál. Lehetővé teszi az adatok tisztítását, hiányzó értékek kezelését és új oszlopok létrehozását meglévőkből. A Pandas használata elengedhetetlen az adatok előkészítéséhez a gépi tanulási modellek számára.
A Featuretools egy automatizált feature engineering könyvtár, amely képes automatikusan új jellemzőket generálni a relációs adatokból. Ez a könyvtár különösen hasznos, ha komplex adatbázisokkal dolgozunk, és nehéz kézzel létrehozni releváns jellemzőket.
Ezen könyvtárak kombinált használata lehetővé teszi a gépi tanulási modellek számára optimális bemeneti adatok előállítását, ami jelentősen javíthatja a modellek pontosságát és általánosíthatóságát. A Feature Engineering során elengedhetetlen a probléma alapos ismerete és a megfelelő transzformációk kiválasztása.
Esettanulmány: Feature Engineering egy konkrét gépi tanulási problémában
Vegyünk egy példát a banki ügyféllemorzsolódás előrejelzésére. A nyers adataink tartalmazhatnak demográfiai információkat (életkor, nem, lakhely), számlainformációkat (számlatípus, egyenleg, tranzakciók száma), és ügyfélkapcsolati adatokat (panaszok száma, kapcsolatfelvételek gyakorisága). Azonban ezek a nyers adatok önmagukban nem biztos, hogy a leghatékonyabbak a modell számára.
Az egyik legfontosabb lépés a kategorikus változók kezelése. Tegyük fel, hogy van egy „Lakhely” oszlopunk, amely városneveket tartalmaz. Ezt nem tudjuk közvetlenül a modellbe táplálni. Helyette használhatunk one-hot encodingot, ami minden egyes városból egy bináris oszlopot hoz létre. Egy másik megközelítés lehet a lakhelyek csoportosítása (pl. nagyváros, kisváros, falu), ami csökkenti a dimenziószámot és potenciálisan javítja a modell teljesítményét.
A számszerű adatok átalakítása is kulcsfontosságú. Például, az „Egyenleg” oszlop eloszlása valószínűleg nem normális. Alkalmazhatunk logaritmikus transzformációt, hogy az eloszlás szimmetrikusabb legyen, ami a lineáris modellek teljesítményét javíthatja. Ezenkívül, létrehozhatunk új változókat, például az „Egyenleg/Tranzakciók száma” hányadost, ami az ügyfél pénzkezelési szokásairól adhat információt.
Az ügyfélkapcsolati adatok elemzése is fontos. A „Panaszok száma” oszlopot kombinálhatjuk az „Ügyfélkapcsolatok gyakorisága” oszloppal, hogy létrehozzunk egy „Ügyfélelégedettségi indexet”. Ez egy komplexebb változó, ami jobban tükrözi az ügyfél elégedettségét, mint a két változó külön-külön.
A feature scaling, mint például a standardizálás vagy a normalizálás, szintén elengedhetetlen. Ez biztosítja, hogy minden változó azonos skálán legyen, ami megakadályozza, hogy a nagyobb értékekkel rendelkező változók túlságosan befolyásolják a modellt.
A cél a megfelelő feature engineeringgel az, hogy a modell számára könnyebben felismerhetővé tegyük a mintákat az adatokban, ezáltal javítva a pontosságot és a megbízhatóságot.
Végül, a feature selection segítségével kiválaszthatjuk a legfontosabb változókat. Használhatunk különböző módszereket, például a feature importance-ot (fa alapú modelleknél), vagy a recursive feature elimination-t. Ez segít csökkenteni a modell komplexitását és elkerülni a túltanulást.
Például, a „Számlatípus” oszlopot kombinálhatjuk az „Egyenleg” oszloppal egy új változó létrehozásához: „Átlagos egyenleg számlatípusonként”. Ez a változó segíthet megkülönböztetni azokat az ügyfeleket, akik magas egyenleggel rendelkeznek egy adott számlatípuson, ami potenciálisan jelzi a lehetséges lemorzsolódást.
Gyakori hibák a Feature Engineering során és azok elkerülése
A feature engineering során elkövetett hibák jelentősen ronthatják a gépi tanulási modellek teljesítményét. Az egyik leggyakoribb hiba az adatszivárgás, amikor a modell képzése során olyan információkhoz fér hozzá, amelyek a valós életben nem lennének elérhetőek. Például, ha a jövőbeli adatokat használjuk a jellemzők létrehozásához, az irreálisan magas pontosságot eredményezhet a tesztadatokon, de a modell a gyakorlatban gyengén fog teljesíteni.
Egy másik gyakori hiba a túl sok jellemző létrehozása anélkül, hogy megfelelően szűrnénk azokat. Ez a túlilleszkedéshez vezethet, ahol a modell túlságosan a képzési adatokra van optimalizálva, és nem képes jól általánosítani az új adatokra.
A irreleváns vagy redundáns jellemzők eltávolítása, valamint a megfelelő jellemzők kiválasztása kulcsfontosságú a modell teljesítményének javításához.
A nem megfelelő skálázás is problémát okozhat. A különböző jellemzők eltérő skálán való mérése befolyásolhatja az algoritmusok működését, különösen a távolság alapú módszereknél, mint például a k-nearest neighbors. A jellemzők standardizálása vagy normalizálása segíthet elkerülni ezt a problémát.
Végül, a hiányzó adatok helytelen kezelése is gyakori hiba. A hiányzó értékek egyszerű törlése értékes információt veszíthet, míg a helytelen imputálás torzíthatja az adatokat. A hiányzó adatok kezelésére számos módszer létezik, és a megfelelő módszer kiválasztása az adott adathalmaz és a modell követelményeitől függ.
A Feature Engineering jövője: Automatizálás és új módszerek

A feature engineering jövője egyértelműen az automatizálás felé mutat. Az AutoML (Automated Machine Learning) platformok egyre kifinomultabbak, képesek automatikusan feltárni és létrehozni releváns új jellemzőket a nyers adatokból. Ez jelentősen csökkenti a kézi munkát és lehetővé teszi a szakemberek számára, hogy a modellépítés stratégiai kérdéseire koncentráljanak.
Az automatizálás mellett a transzfer tanulás is egyre nagyobb szerepet kap. Előre betanított modelleket használva, amelyek nagy mennyiségű adaton tanultak, a feature engineering hatékonyabbá tehető, különösen olyan esetekben, amikor korlátozott mennyiségű címkézett adat áll rendelkezésre.
A mélytanulás területén is megfigyelhető egy eltolódás a kézi feature engineering felől az automatikus jellemzőkivonás irányába. A konvolúciós neurális hálózatok (CNN-ek) és a rekurrens neurális hálózatok (RNN-ek) képesek automatikusan megtanulni a releváns jellemzőket a kép-, szöveg- és idősor adatokból.
Az automatizálás és a transzfer tanulás kombinációja a feature engineering hatékonyságának és eredményességének jelentős növekedéséhez vezethet.
Új módszerek is megjelennek, mint például a generatív modellek (GAN-ok), melyek segítségével szintetikus adatokat generálhatunk, ezzel bővítve a rendelkezésre álló adatmennyiséget és javítva a modellek teljesítményét. Emellett a feature selection módszerek is finomodnak, lehetővé téve a legrelevánsabb jellemzők kiválasztását a modell komplexitásának csökkentése és a teljesítmény javítása érdekében.
A jövőben a feature engineering egyre inkább egy iteratív és kísérletező folyamat lesz, ahol az automatizált eszközök és az új módszerek segítik a szakembereket a legjobb jellemzők megtalálásában és a gépi tanulási modellek optimalizálásában.