

A modern adatközpontú világban az információ ereje felbecsülhetetlen. Nap mint nap hatalmas mennyiségű adattal találkozunk, de gyakran előfordul, hogy a rendelkezésre álló adatsorok hiányosak, vagy éppen a jövőre vonatkozó becslésekre lenne szükségünk. Ezen kihívások kezelésére szolgál az interpoláció és az extrapoláció tudománya, két alapvető statisztikai és matematikai eszköz, amelyek segítségével ismeretlen érték becslése válik lehetővé a már ismert adatok alapján. Ezek a módszerek kulcsfontosságúak az üzleti döntéshozatalban, a tudományos kutatásban, a mérnöki tervezésben és gyakorlatilag minden olyan területen, ahol a múltbeli trendekből következtetni szeretnénk a jelenre vagy a jövőre.
Az adatok elemzése során gyakran előfordul, hogy egy adott időpontban vagy ponton hiányzik egy érték, vagy éppen az adatsorunkon kívüli pontra szeretnénk becslést adni. Gondoljunk csak egy vállalat értékesítési adataira: mi van, ha egy hónap adatai elvesztek, vagy ha a következő negyedévre szeretnénk előrejelzést készíteni? Ekkor jön képbe az adatsor kiterjesztése és a hiányzó pontok feltöltése. Az interpoláció és az extrapoláció tehát nem csupán elméleti fogalmak, hanem rendkívül praktikus eszközök, amelyekkel a valós életben felmerülő problémákra adhatunk megalapozott válaszokat. Pontosságuk és megbízhatóságuk azonban nagyban függ az alkalmazott módszertől, az adatok minőségétől és a mögöttes feltételezésektől, ezért elengedhetetlen a mélyreható megértésük.
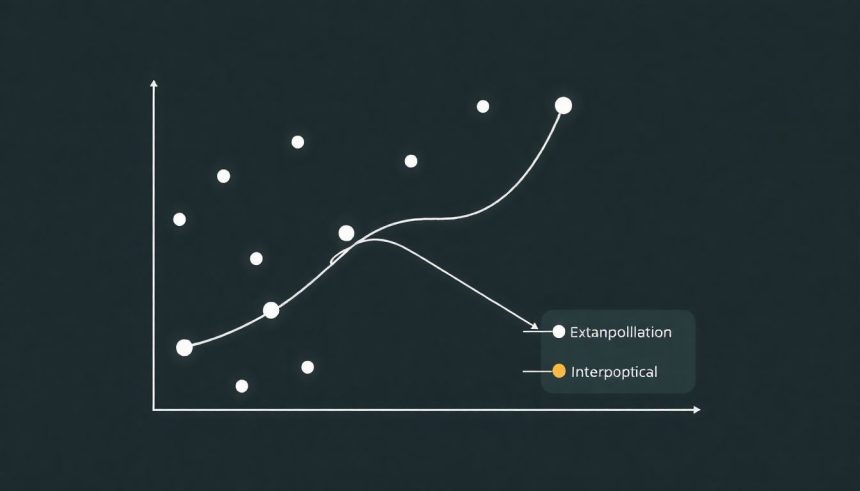
Mi az interpoláció és az extrapoláció? Az alapfogalmak tisztázása
Ahhoz, hogy hatékonyan alkalmazhassuk ezeket a technikákat, első lépésként tisztában kell lennünk az alapfogalmakkal és a köztük lévő alapvető különbségekkel. Mindkét módszer arra szolgál, hogy ismeretlen érték becslése történjen ismert adatok alapján, de a „hol” és „hogyan” kérdésre adott válaszok alapvetően eltérnek.
Az interpoláció szó szerint „köztes kitöltést” jelent. Amikor interpolálunk, egy olyan pontra becsülünk értéket, amely a már ismert adatpontok tartományán belül van. Képzeljünk el egy grafikonon ábrázolt pontsort; az interpoláció során e pontok közé illesztünk be egy új, becsült értéket. Ez a módszer viszonylag megbízható, mivel a becsült érték a már meglévő, „támasztó” adatpontok között helyezkedik el, amelyek segítenek korlátozni a lehetséges hibákat.
Ezzel szemben az extrapoláció azt jelenti, hogy az ismert adatpontok tartományán kívülre, azaz a jövőbe (vagy a múltba) becsülünk értéket. Ez a módszer sokkal nagyobb bizonytalanságot hordoz magában, mivel a becslés alapjául szolgáló trendet kiterjesztjük egy olyan területre, ahol nincs közvetlen adatunk. Képzeljünk el egy egyenes vonallal illesztett adatsort; az extrapoláció azt jelenti, hogy ezt az egyenest meghosszabbítjuk, és megnézzük, hol metszené a tengelyt egy adott ponton kívül. Bár az extrapoláció elengedhetetlen az előrejelzésekhez, a megbízhatósága jelentősen csökken, minél távolabb esik a becsült pont az ismert adatok tartományától.
Az interpoláció a hiányzó darabok pótlása egy meglévő képben, míg az extrapoláció a kép kiterjesztése a vászon határain túlra.
Interpoláció: A meglévő adatok közötti hézagok kitöltése
Az interpoláció célja, hogy a meglévő, diszkrét adatpontok között sima, folytonos átmenetet teremtsen, és ezáltal becsülje meg azokat az értékeket, amelyek közvetlenül nem állnak rendelkezésre. Ez a technika kritikus fontosságú számos tudományágban, ahol a mérések időszakosan történnek, de folytonos adatokra van szükség.
Mikor használjuk az interpolációt?
- Hiányzó adatpontok pótlása: Gyakori eset, hogy egy szenzor meghibásodása, adatátviteli hiba vagy egyszerűen csak a mérések ritkasága miatt hiányoznak adatok egy idősorból. Az interpoláció segít ezen hézagok kitöltésében, biztosítva a folytonos adatsort a további elemzésekhez.
- Adatok simítása és zajszűrés: Bár nem ez az elsődleges funkciója, az interpolációval néha a zajos adatok simítására is sor kerülhet, különösen, ha valamilyen simító interpolációs módszert alkalmazunk.
- Kisebb felbontású adatok nagyításához: Képfeldolgozásban például az interpolációval lehetőség van egy kisebb felbontású kép nagyítására anélkül, hogy a pixelek „kockásnak” tűnnének.
- Funkciók becslése: Ha egy összetett függvényről csak néhány pontban ismerjük az értékét, az interpoláció segíthet a függvény közelítő leírásában ezen pontok között.
Az interpoláció során a legfontosabb szempont a pontosság. Mivel a becsült érték az ismert adatok között helyezkedik el, a modellnek képesnek kell lennie a környező pontok közötti kapcsolat megragadására. A jó interpolációs modell minimális hibával kell, hogy kitöltse a hiányzó részeket, megőrizve az adatsor eredeti mintázatát és trendjét.
Extrapoláció: A jövő és a múlt megjóslása
Az extrapoláció a leggyakrabban az előrejelzés szinonimájaként jelenik meg, hiszen segítségével a jövőbeni eseményekre vagy a múltbeli, nem dokumentált eseményekre vonatkozó becsléseket készíthetünk. Ez a módszer különösen vonzó, mivel lehetővé teszi számunkra, hogy felkészüljünk a jövőre, optimalizáljuk erőforrásainkat, vagy megértsük a múltbeli folyamatokat, amelyekről nincs közvetlen adatunk.
Mikor használjuk az extrapolációt?
- Üzleti előrejelzés: Értékesítési trendek, piaci növekedés, készletigények becslése a jövőre nézve. Ez alapvető a stratégiai tervezésben és a költségvetés-készítésben.
- Tudományos kutatás: Klímamodellek, népességnövekedési előrejelzések, betegségek terjedésének modellezése.
- Mérnöki tervezés: Anyagok élettartamának becslése extrém körülmények között, a rendszerek teljesítményének előrejelzése a tervezett üzemi tartományon kívül.
- Demográfia: A népesség számának és összetételének jövőbeli alakulása, ami alapvető a társadalmi tervezéshez.
Az extrapoláció legnagyobb kihívása a bizonytalanság. Mivel az ismert adatok tartományán kívülre becsülünk, feltételeznünk kell, hogy a megfigyelt trendek és mintázatok a jövőben is érvényesek maradnak. Ez a feltételezés azonban gyakran nem állja meg a helyét, és váratlan események, ún. fekete hattyúk (pl. gazdasági válságok, természeti katasztrófák, technológiai áttörések) drámaian megváltoztathatják a trendeket. Minél távolabb extrapolálunk az ismert adatoktól, annál nagyobb a becslés hibalehetősége, és annál óvatosabban kell kezelni az eredményeket.
A matematikai alapok: Hogyan működnek a becslési módszerek?
Az interpoláció és extrapoláció mögött számos matematikai módszer áll, amelyek bonyolultságukban és pontosságukban is eltérnek. A választás az adatsor jellegétől, a rendelkezésre álló adatok mennyiségétől és a szükséges pontosság mértékétől függ. Nézzünk meg néhány alapvető és fejlettebb technikát.
Lineáris interpoláció és extrapoláció
A leggyakoribb és legegyszerűbb módszer a lineáris interpoláció és extrapoláció. Ez azon a feltételezésen alapul, hogy az ismert adatpontok között, vagy azok tartományán kívül egyenes vonalú kapcsolat áll fenn. Két ismert pont, (x1, y1) és (x2, y2) közötti vagy azokból kiinduló egyenest feltételezünk.
Lineáris interpoláció esetén, ha egy ismeretlen x értékre y értékre van szükségünk, amely x1 és x2 között van, a következő képletet használjuk:
y = y1 + (y2 – y1) * ((x – x1) / (x2 – x1))
Ez a képlet lényegében a két pont közötti egyenesre eső pontot számolja ki, arányosan elosztva a távolságot. Egyik legfőbb előnye az egyszerűsége és a gyors számíthatósága.
Példa lineáris interpolációra:
Tegyük fel, hogy egy cég értékesítési adatai a következők:
- Január (x=1): 100 egység
- Március (x=3): 150 egység
Szeretnénk becsülni a februári (x=2) értékesítést.
x1=1, y1=100
x2=3, y2=150
x=2
y = 100 + (150 – 100) * ((2 – 1) / (3 – 1))
y = 100 + 50 * (1 / 2)
y = 100 + 25 = 125 egység
A becsült februári értékesítés 125 egység.
Lineáris extrapoláció esetén ugyanezt az egyenes egyenletet használjuk, de az x érték az ismert tartományon kívül esik. Például, ha a fenti adatok alapján szeretnénk megbecsülni az áprilisi (x=4) értékesítést:
x1=1, y1=100
x2=3, y2=150
x=4
y = 100 + (150 – 100) * ((4 – 1) / (3 – 1))
y = 100 + 50 * (3 / 2)
y = 100 + 75 = 175 egység
A becsült áprilisi értékesítés 175 egység.
A lineáris módszerek egyszerűségük ellenére korlátozottak. Csak akkor adnak pontos eredményt, ha az adatok valóban lineáris trendet követnek. Nemlineáris adatok esetén jelentős hibákat okozhatnak, és nem képesek megragadni az adatokban rejlő összetettebb mintázatokat.
Polinomiális interpoláció és extrapoláció
Amikor az adatok nem követnek lineáris trendet, a polinomiális interpoláció és extrapoláció pontosabb becsléseket adhat. Ez a módszer egy magasabb fokú polinomot illeszt az adatpontokra, ami lehetővé teszi a görbült trendek modellezését.
Egy n számú adatpontra (xi, yi) egy (n-1)-ed fokú polinom illeszthető, amely pontosan áthalad az összes ponton. A leggyakoribb polinomiális interpolációs módszerek a Lagrange-interpoláció és a Newton-interpoláció.
A Lagrange-interpoláció egy képletet ad meg, amely közvetlenül felírja az interpoláló polinomot. Bár matematikailag elegáns, nagy számú pont esetén számításigényes és numerikusan instabil lehet.
A Newton-interpoláció osztott differenciákat használ, ami lehetővé teszi új pontok hozzáadását anélkül, hogy az egész számítást újra kellene kezdeni. Ez gyakran stabilabb és hatékonyabb, mint a Lagrange-módszer.
A polinomiális interpoláció előnye, hogy képes megragadni az adatokban lévő bonyolultabb görbületeket. Hátránya viszont, hogy magas fokú polinomok esetén hajlamos a túlillesztésre (overfitting). Ez azt jelenti, hogy a polinom túlságosan pontosan illeszkedik a meglévő adatpontokhoz, és „ingadozik” közöttük, ami irreális becslésekhez vezethet az interpolált vagy extrapolált tartományokban. Különösen az extrapoláció esetében a magas fokú polinomok nagyon gyorsan divergens, értelmetlen értékeket produkálhatnak az ismert adatokon kívül.
Spline interpoláció
A spline interpoláció egy olyan kompromisszumos megoldás, amely a lineáris és a magas fokú polinomiális interpoláció előnyeit ötvözi, miközben minimalizálja a hátrányokat. A spline-ok lényegében darabonként definiált polinomok, amelyek az adatpontokat szegmensenként kötik össze alacsony fokú (általában harmadfokú) polinomokkal.
A kulcs a folytonosság és simaság. A spline-ok biztosítják, hogy az egyes polinomdarabok illeszkedési pontjainál (ezeket „csomópontoknak” vagy „knotoknak” nevezzük) a függvényértékek, az első deriváltak és gyakran a második deriváltak is folytonosak legyenek. Ezáltal egy sima, folytonos görbét kapunk, amely nem ingadozik annyira, mint egyetlen magas fokú polinom.
- Előnyök: Nagyobb pontosság, mint a lineáris interpolációnál, de stabilabb és kevésbé hajlamos a túlillesztésre, mint a magas fokú polinomiális interpoláció. Különösen jó választás, ha az adatokban élesebb fordulók vannak.
- Hátrányok: Bonyolultabb a számítása, mint a lineáris interpolációnak, és az extrapolációra kevésbé alkalmas, mivel a szélső pontokon a simasági feltételek korlátozottak.
Más fejlettebb módszerek
A fenti módszereken túl számos más technika is létezik, amelyek specifikus adatsorokhoz és problémákhoz jobban illeszkednek:
- Exponenciális interpoláció/extrapoláció: Alkalmas olyan adatokhoz, amelyek exponenciális növekedést vagy csökkenést mutatnak (pl. népességnövekedés, vírus terjedése).
- Logaritmikus interpoláció/extrapoláció: Olyan jelenségeknél hasznos, ahol a változás üteme a logaritmusos skálán lineáris.
- Fourier-sorok: Periodikus adatok interpolálására és extrapolálására, például időjárási minták vagy hanghullámok elemzésénél.
- Környezeti súlyozott interpoláció (Inverse Distance Weighting – IDW): Térbeli adatok interpolálására, ahol a közeli pontok nagyobb súllyal esnek latba.
- Kriging: Geostatisztikai módszer, amely a térbeli korrelációt is figyelembe veszi, rendkívül pontos térbeli interpolációt tesz lehetővé.
Ezen módszerek kiválasztása mindig az adott probléma kontextusától és az adatok jellegétől függ. A megfelelő módszer kiválasztása kulcsfontosságú a pontos és megbízható becslésekhez.
Adatsorok és trendek elemzése: Az előkészítés fontossága
Mielőtt bármilyen interpolációs vagy extrapolációs módszerhez folyamodnánk, elengedhetetlen az adatsor alapos előkészítése és elemzése. Az „garbage in, garbage out” (szemét be, szemét ki) elv itt különösen igaz: a hibás vagy rosszul értelmezett adatokból sosem kapunk megbízható becsléseket.
Adatgyűjtés és tisztítás
Az első lépés a megbízható és releváns adatok gyűjtése. Fontos, hogy az adatok forrása hiteles legyen, és a mérések konzisztensek legyenek. Az adatok tisztítása magában foglalja a következőket:
- Hiányzó értékek kezelése: Bár az interpoláció célja a hiányzó értékek pótlása, fontos megkülönböztetni azokat a hiányzó értékeket, amelyeket szándékosan hagyunk ki a mérésből, és azokat, amelyek hibából adódnak.
- Kiemelkedő értékek (outlierek) azonosítása és kezelése: Az extrém, a többi adattól jelentősen eltérő pontok torzíthatják a trendeket és a becsléseket. Ezeket vagy el kell távolítani, vagy speciális módon kell kezelni (pl. robusztus statisztikai módszerekkel).
- Adatkonzisztencia ellenőrzése: Ellenőrizni kell az adatok egységességét, a mértékegységek helyességét és az esetleges gépelési hibákat.
A gondos adatgyűjtés és tisztítás alapozza meg a későbbi elemzések sikerét. Egy „tiszta” adatsor sokkal megbízhatóbb alapot nyújt az ismeretlen érték becsléséhez.
Trendek azonosítása
Az adatokban rejlő trendek felismerése kulcsfontosságú a megfelelő modell kiválasztásához. Különböző típusú trendek létezhetnek:
- Lineáris trend: Az adatok nagyjából egy egyenes vonal mentén helyezkednek el.
- Exponenciális trend: Az adatok növekedése vagy csökkenése egyre gyorsuló ütemben történik (pl. kamatos kamat).
- Logaritmikus trend: A növekedés vagy csökkenés üteme fokozatosan lassul.
- Polinomiális trend: Az adatok görbült mintázatot mutatnak, amelyet magasabb fokú polinommal lehet leírni.
- Periodikus vagy szezonális trend: Az adatok ismétlődő mintázatot mutatnak bizonyos időközönként (pl. évszakok, napszakok).
A trendek azonosítása gyakran vizuális ellenőrzéssel kezdődik, de statisztikai tesztekkel is megerősíthető. Egyértelműen lineáris trend esetén a lineáris módszerek megfelelőek lehetnek, míg egy görbült trend esetén a polinomiális vagy spline módszerek indokoltak. A periodikus trendekhez idősor-elemzési technikák (pl. Fourier-elemzés) szükségesek.
Adatvizualizáció: A grafikonok szerepe
Az adatvizualizáció, különösen a grafikonok és diagramok használata, elengedhetetlen az adatok megértéséhez és a megfelelő becslési módszer kiválasztásához. Egy jól megrajzolt szórásdiagram azonnal felfedheti az adatokban rejlő mintázatokat, trendeket, kiugró értékeket és esetleges hibákat.
- Szórásdiagram (Scatter plot): Megmutatja az egyes adatpontokat, és segít vizuálisan azonosítani a kapcsolatot a változók között, valamint a trendek alakját.
- Vonaldiagram (Line plot): Idősoros adatoknál különösen hasznos, mivel egyértelműen ábrázolja a változást az idő függvényében.
- Hisztogram: Az adatok eloszlását mutatja meg, ami segíthet az adatok homogenitásának megértésében.
A vizualizáció nemcsak az adatok előkészítésében segít, hanem az eredmények kommunikálásában is. Egy jól ábrázolt grafikon, amelyen az eredeti adatok és a becsült értékek is szerepelnek, sokkal érthetőbbé teszi a modellezés eredményeit a nem szakértők számára is.
Az interpoláció gyakorlati alkalmazásai különböző területeken

Az interpoláció nem csupán egy elméleti matematikai fogalom, hanem számos iparágban és tudományágban kulcsfontosságú gyakorlati alkalmazása van. Segít a hiányzó információk pótlásában és a folytonos adatábrázolásban.
Pénzügy és gazdaság
A pénzügyi szektorban az interpoláció elengedhetetlen a hiányzó adatok kitöltéséhez és a komplex pénzügyi instrumentumok értékeléséhez.
- Hiányzó részvényárfolyamok vagy kamatlábak becslése: Ha egy adott napra vonatkozó tőzsdei adat hiányzik, vagy egy ritkán kereskedett értékpapír árfolyamára van szükség két ismert időpont között, az interpolációval megbecsülhető az érték.
- Kamatgörbék szerkesztése: A kamatgörbe folytonos ábrázolása létfontosságú a pénzügyi modellezésben. Mivel a piaci kamatlábak csak bizonyos lejáratokra (pl. 3 hónap, 1 év, 5 év) ismertek, az interpolációval lehetőség van a köztes lejáratokra vonatkozó kamatlábak becslésére, így egy folytonos kamatgörbét kapunk.
- Derivált termékek árazása: Egyes derivált termékek, például opciók árazása során szükség lehet a volatilitás vagy más paraméterek interpolálására, ha azok csak diszkrét pontokban ismertek.
Mérnöki tudományok
A mérnöki területeken az interpoláció segíti az adatok feldolgozását és a rendszerek viselkedésének modellezését.
- Szenzoradatok hiányzó értékei: Egy mérőrendszerben előfordulhat, hogy egyes szenzorok átmenetileg hibásan működnek, vagy nem rögzítenek adatot. Az interpolációval a hiányzó hőmérséklet-, nyomás- vagy rezgésadatok pótolhatók, biztosítva a folyamatos monitorozást.
- Anyagjellemzők becslése: Anyagvizsgálatok során az anyagok tulajdonságait (pl. szilárdság, rugalmasság) gyakran csak bizonyos hőmérsékleteken vagy terheléseknél mérik. Az interpolációval megbecsülhetők a köztes értékek, így egy folytonos anyagtulajdonság-görbe hozható létre.
- Térbeli adatok: A geológiában vagy a hidrológiában a talajösszetétel, vízminták vagy domborzati adatok gyakran csak bizonyos pontokon állnak rendelkezésre. Az interpolációval egy folytonos térbeli eloszlás hozható létre ezekből a diszkrét pontokból.
Környezettudomány
A környezettudományban az interpoláció kulcsfontosságú a környezeti változók térbeli és időbeli elemzéséhez.
- Hőmérséklet- és csapadékadatok kitöltése: Időjárás-állomásokon gyűjtött adatok hiányosságai esetén az interpolációval pótolhatók a hiányzó értékek. Térbeli interpolációval pedig a pontszerű mérésekből (pl. különböző városokban mért hőmérséklet) folytonos hőmérsékleti térképek hozhatók létre.
- Légszennyezettségi szintek becslése: A légszennyezettség mérőállomásai csak bizonyos pontokon találhatók. Az interpolációval megbecsülhető a szennyezettségi szint az állomások közötti területeken, így részletesebb térképek készíthetők.
- Vízminőségi adatok elemzése: Folyók vagy tavak vízminőségi paramétereit (pl. pH, oldott oxigén) csak bizonyos mintavételi pontokon mérik. Az interpolációval a köztes területeken is becsülhetők ezek az értékek.
Képfeldolgozás és grafika
A digitális képfeldolgozásban az interpoláció alapvető szerepet játszik a képek méretezésében és manipulációjában.
- Képek nagyítása (upscaling): Amikor egy kisebb felbontású képet nagyobb méretűvé alakítunk, az interpolációval új pixelértékek hozhatók létre a meglévő pixelek között, így a kép kevésbé tűnik „kockásnak”. A leggyakoribb módszerek a legközelebbi szomszéd (nearest neighbor), a bilineáris és a bikubikus interpoláció.
- Rotáció és torzítás: Képek elforgatásánál vagy torzításánál a pixelek új koordinátákra kerülnek. Az interpolációval megbecsülhetők az új pixelértékek, amelyek a transzformáció után keletkeznek, biztosítva a sima átmeneteket.
Orvostudomány és biológia
Az orvostudományban és biológiában az interpoláció segíti az adatok elemzését a diagnosztikában és a kutatásban.
- Gyógyszerkoncentrációk becslése: Egy gyógyszer farmakokinetikájának vizsgálatakor a vérplazma-koncentrációt csak bizonyos időpontokban mérik. Az interpolációval megbecsülhető a koncentráció a mérések közötti időpontokban, így egy folytonos időbeli profilt kapunk.
- Betegadatok hiányosságai: Klinikai vizsgálatok során előfordulhat, hogy egyes betegadatok hiányoznak (pl. vérnyomás, vércukorszint egy adott napon). Az interpolációval ezek az adatok pótolhatók, lehetővé téve a teljes adatsor elemzését.
- Genomikai adatok elemzése: A génexpressziós adatok vagy a DNS-szekvenciák elemzése során is felmerülhet interpolációs igény a hiányzó vagy ritka adatok kezelésére.
Az extrapoláció gyakorlati alkalmazásai különböző területeken
Míg az interpoláció a hiányzó adatok kitöltésére szolgál az ismert tartományon belül, addig az extrapoláció a jövőbeni trendek előrejelzésére vagy a múltbeli, nem dokumentált események becslésére fókuszál. Ez a képesség rendkívül értékes a stratégiai tervezésben és a döntéshozatalban, annak ellenére, hogy nagyobb kockázattal jár.
Üzleti előrejelzés
Az üzleti világban az extrapoláció az egyik legfontosabb eszköz a jövőbeli teljesítmény becslésére és a stratégiai tervezésre.
- Értékesítési trendek előrejelzése: A múltbeli értékesítési adatok alapján extrapolálható a jövőbeni értékesítés. Ez segít a termelés tervezésében, a készletszintek optimalizálásában és a marketingkampányok ütemezésében.
- Piaci növekedés becslése: Egy új termék vagy szolgáltatás bevezetésekor a múltbeli piaci adatokból extrapolálható a várható piaci részesedés és a növekedési ütem.
- Költségvetés-tervezés: A múltbeli kiadási és bevételi adatok extrapolációjával pontosabb költségvetés készíthető a következő pénzügyi időszakra.
- Kereslet-előrejelzés: A termékek vagy szolgáltatások iránti jövőbeli kereslet becslése alapvető a gyártási kapacitás, az ellátási lánc és a humánerőforrás tervezéséhez.
Demográfia
A demográfia az extrapolációt használja a népesség szerkezetének és dinamikájának jövőbeli alakulásának becslésére.
- Népességnövekedés: A múltbeli születési, halálozási és migrációs adatok alapján extrapolálható a jövőbeni népességszám. Ez kritikus a nyugdíjrendszerek, az egészségügyi ellátás és az oktatás tervezésében.
- Korfa alakulása: A népesség kor szerinti megoszlásának előrejelzése segíti a társadalmi szolgáltatások és a munkaerőpiac tervezését.
- Városfejlesztés: A városok népességének növekedési trendjeinek extrapolálásával a városvezetések tervezhetik az infrastruktúra (út, közlekedés, lakhatás) fejlesztését.
Klímamodellezés és környezettudomány
A klímamodellezés az extrapolációt használja a Föld éghajlatának jövőbeni változásainak előrejelzésére.
- Jövőbeli hőmérséklet-emelkedés: A múltbeli hőmérsékleti adatok és a szén-dioxid-koncentráció trendjeinek extrapolálásával becsülhetők a jövőbeni felmelegedési forgatókönyvek.
- Tengerszint-emelkedés: A gleccserek olvadásának és a tengeri hőtágulásnak a múltbeli adatai alapján extrapolálható a jövőbeni tengerszint-emelkedés.
- Fajok kihalási rátája: A múltbeli fajok kihalási ütemének extrapolálásával becsülhető a jövőbeni biodiverzitás-vesztés.
Technológiai fejlesztés
A technológiai szektorban az extrapoláció segít a jövőbeli fejlődés ütemének és a technológiák adoptációjának becslésében.
- Moore-törvény: Bár nem szigorúan matematikai extrapoláció, a Moore-törvény (a tranzisztorok számának megduplázódása 18-24 havonta) egy híres példája egy technológiai trend extrapolálásának, amely hosszú ideig pontosnak bizonyult.
- Technológiai adoptáció: Egy új technológia terjedésének múltbeli adatai alapján extrapolálható a jövőbeni piaci penetráció, ami fontos a befektetési és fejlesztési döntésekhez.
- Adattárolási kapacitás növekedése: Az adattárolók kapacitásának exponenciális növekedési trendjeinek extrapolálásával becsülhető a jövőbeni tárolási igény.
Kutatás és fejlesztés
A kutatás és fejlesztés területén az extrapolációval a kísérleti eredmények kiterjesztése és a hosszú távú hatások becslése történik.
- Kísérleti eredmények kiterjesztése: Laboratóriumi körülmények között kapott eredmények extrapolálhatók valós környezeti viszonyokra vagy nagyobb méretű rendszerekre.
- Gyógyszerhatások: Egy gyógyszer hosszú távú hatásait vagy mellékhatásait gyakran rövid távú klinikai vizsgálatokból extrapolálják.
- Anyagok élettartama: Rövid távú stressztesztek eredményei alapján extrapolálható az anyagok várható élettartama hosszú távú terhelés alatt.
Az extrapoláció, bár kockázatos, elengedhetetlen eszköz a jövővel kapcsolatos megalapozott feltételezések és döntések meghozatalához. Fontos azonban mindig tudatában lenni a mögöttes feltételezéseknek és a bizonytalanságnak.
Kockázatok és buktatók: Mikor tévedhetünk?
Bár az interpoláció és az extrapoláció rendkívül hasznos eszközök, nem tévedhetetlenek. Számos kockázatot és buktatót rejtenek magukban, amelyek figyelmen kívül hagyása félrevezető vagy akár káros következtetésekhez is vezethet.
Az extrapoláció inherent kockázatai: A jövő bizonytalansága
Az extrapoláció alapvető feltételezése, hogy a múltbeli trendek és mintázatok a jövőben is folytatódnak. Ez azonban ritkán igaz teljes mértékben.
- Trendtörés: Gazdasági válságok, technológiai áttörések, szabályozási változások vagy természeti katasztrófák drámaian megváltoztathatják a trendeket, érvénytelenné téve a múltbeli adatokból származó előrejelzéseket. Ezeket a hirtelen, váratlan eseményeket gyakran „fekete hattyúknak” nevezzük.
- Modellhibák: Ha a kiválasztott modell (pl. lineáris, exponenciális) nem írja le pontosan az adatok mögötti valós folyamatot, az extrapoláció súlyos hibákat eredményezhet. Például, egy exponenciális növekedést lineárisan extrapolálva alábecsüljük a jövőbeni értékeket, míg egy lineáris trendet exponenciálisan extrapolálva túlbecsüljük.
- A bizonytalanság növekedése: Minél távolabbra extrapolálunk az ismert adatok tartományától, annál nagyobb a becslés bizonytalansága. Az előrejelzési intervallumok (konfidencia intervallumok) exponenciálisan növekedhetnek a távolsággal, jelezve, hogy az előrejelzés egyre kevésbé megbízható.
Az extrapoláció olyan, mint a vezetés a visszapillantó tükör segítségével: hasznos a közvetlen múlt megértéséhez, de veszélyes, ha csak arra támaszkodunk a jövő megítélésében.
Az interpoláció pontossága: Adatminőség, modellválasztás
Bár az interpoláció általában megbízhatóbb, mint az extrapoláció, mégis rejthet kockázatokat:
- Rossz adatminőség: Ha az alapul szolgáló adatok hibásak, zajosak vagy hiányosak, az interpoláció torzított eredményeket adhat. A kiugró értékek különösen nagyban befolyásolhatják a becslést.
- Helytelen modellválasztás: Ha egy lineáris interpolációt alkalmazunk egy erősen nemlineáris adatsorban, a becsült értékek eltérhetnek a valóságtól. Például, egy hullámzó adatsor lineáris interpolációja figyelmen kívül hagyja a csúcsokat és völgyeket.
- Az adatok ritkasága: Ha az ismert adatpontok túl távol vannak egymástól, az interpoláció kevésbé pontos lesz, mivel kevesebb információ áll rendelkezésre a köztes értékek becsléséhez.
Túlillesztés (overfitting) és alulillesztés (underfitting)
Ez a két jelenség különösen a polinomiális módszereknél jelentkezik, de más modelleknél is előfordulhat:
- Túlillesztés (overfitting): Akkor következik be, ha a modell túlságosan pontosan illeszkedik a tréning adatokhoz, beleértve a zajt és a véletlenszerű ingadozásokat is. Az interpolált vagy extrapolált értékek ilyenkor irreálisak lehetnek, mert a modell nem a mögöttes trendet, hanem az adatok egyedi „hibáit” ragadta meg. Ezt gyakran a túlságosan bonyolult modellek (pl. magas fokú polinomok) használata okozza viszonylag kevés adatpont esetén.
- Alulillesztés (underfitting): Akkor következik be, ha a modell túl egyszerű ahhoz, hogy megragadja az adatokban rejlő alapvető mintázatokat. Például, egy lineáris modell alkalmazása egy erősen görbült adatsorhoz alulillesztést eredményez. Ilyenkor mind az interpolált, mind az extrapolált értékek pontatlanok lesznek, mert a modell nem képes leírni az adatok valódi viselkedését.
A megfelelő modell kiválasztása a pontosság és az általánosíthatóság közötti egyensúly megtalálásáról szól. Egy jó modell képes megragadni az adatok lényegét anélkül, hogy túlságosan érzékeny lenne a zajra.
Feltételezések és azok érvényessége
Minden interpolációs és extrapolációs módszer mögött bizonyos feltételezések állnak (pl. linearitás, folytonosság, trendek stabilitása). Ha ezek a feltételezések nem érvényesek az adott adatsorra vagy a becslési tartományra, akkor az eredmények megbízhatatlanok lesznek. Kritikus fontosságú, hogy mindig ellenőrizzük ezeket a feltételezéseket, és mérlegeljük, hogy mennyire reálisak az adott kontextusban.
Külső tényezők hatása
Az adatok gyakran külső tényezők komplex kölcsönhatásainak eredményei. Az extrapoláció során ezeket a külső tényezőket is figyelembe kell venni. Például, egy demográfiai előrejelzésnél figyelembe kell venni a migrációs trendeket, a társadalmi változásokat és a gazdasági körülményeket is, amelyek mind befolyásolhatják a születési és halálozási rátákat. Ha ezek a tényezők változnak, a múltbeli trendek extrapolációja téves eredményekhez vezethet.
Összességében, az interpoláció és az extrapoláció alkalmazása során mindig kritikus szemléletre van szükség. Soha ne fogadjuk el vakon az eredményeket, hanem mindig vizsgáljuk meg a mögöttes feltételezéseket, az adatok minőségét és a modell korlátait. A bizonytalanság jelzése, például konfidencia intervallumok formájában, elengedhetetlen a felelős adatelemzéshez.
Esettanulmányok: Valós példák a sikeres és sikertelen alkalmazásokra
Az elméleti alapok és a kockázatok megértése mellett hasznos, ha konkrét példákon keresztül látjuk, hogyan működnek ezek a módszerek a valóságban. Az alábbi esettanulmányok bemutatják az interpoláció és extrapoláció sikeres és kevésbé sikeres alkalmazásait.
Sikeres interpoláció: GPS navigáció és térképezés
A modern GPS navigációs rendszerek és digitális térképek működése nagymértékben támaszkodik az interpolációra. A GPS készülékek folyamatosan fogadják a műholdaktól érkező jeleket, amelyek alapján meghatározzák a pozíciójukat. Azonban a műholdak jelei nem mindig érkeznek tökéletes folytonossággal, és a készüléknek néha hiányzó adatpontokkal kell dolgoznia, vagy finomítania kell a nyers pozícióadatokon.
- Hiányzó GPS pontok pótlása: Ha egy rövid időre megszakad a műholdas jel (pl. alagútban, sűrű beépítésű városi környezetben), a navigációs rendszer a korábbi mozgásirány és sebesség adatai alapján interpolálja a hiányzó pozíciókat. Ezzel biztosítja a folytonos útvonalat a térképen.
- Térképi adatok finomítása: A digitális térképek domborzati adatait vagy más környezeti jellemzőket gyakran diszkrét mérési pontokból gyűjtik. Az interpolációval ezekből a pontokból egy folytonos felületet hoznak létre, amelyen a magasság, a hőmérséklet vagy a talajminőség minden pontban becsülhető. A Kriging vagy IDW (Inverse Distance Weighting) módszereket gyakran alkalmazzák a geostatisztikában a pontos térbeli interpolációhoz.
Ezek az alkalmazások mutatják, hogy a megfelelő interpolációs módszerrel a hiányos vagy diszkrét adatokból is rendkívül pontos és felhasználható információ nyerhető.
Sikeres extrapoláció: Népességi előrejelzések (óvatosan)
A népességi előrejelzések a demográfia egyik alapvető feladata, és szinte mindig extrapolációra épülnek. Bár a jövő sosem pontosan megjósolható, a demográfusok kifinomult modelleket használnak a születési ráták, halálozási ráták és migrációs mintázatok extrapolálására.
- Hosszú távú tervezés: A kormányok és nemzetközi szervezetek a népességi előrejelzéseket használják a nyugdíjrendszerek, az egészségügy, az oktatás és a városfejlesztés hosszú távú tervezéséhez. Például, ha egy országban a születési ráta folyamatosan csökken, az extrapoláció előre jelezheti a munkaerőpiaci és szociális ellátórendszer jövőbeni kihívásait.
- Modell alapú megközelítés: A demográfiai extrapoláció nem csupán egy egyszerű trendvonal kiterjesztése. Komplex modelleket alkalmaznak, amelyek figyelembe veszik az életkori struktúrát, a termékenységi hajlandóságot, a várható élettartamot és a migrációs forgatókönyveket. Ezek a modellek általában több lehetséges forgatókönyvet is felvázolnak (optimista, pesszimista, reális), jelezve az előrejelzés bizonytalanságát.
Bár a demográfiai előrejelzések sosem 100%-osan pontosak (pl. váratlan események, mint háborúk vagy világjárványok befolyásolhatják őket), a gondos modellválasztás és a bizonytalanság jelzése révén értékes iránymutatást adnak a jövő tervezéséhez.
Sikertelen extrapoláció: A Dot-com buborék és az olajár-előrejelzések
Az extrapoláció korlátainak és veszélyeinek megértéséhez érdemes megnézni néhány olyan esetet, ahol a túlzott optimizmus vagy a trendtörések figyelmen kívül hagyása súlyos hibákhoz vezetett.
- A Dot-com buborék (1990-es évek vége): A technológiai cégek részvényárfolyamai a ’90-es évek végén exponenciálisan növekedtek. Sok befektető és elemző egyszerűen extrapolálta ezt a növekedési trendet a jövőbe, feltételezve, hogy a „new economy” törvényei felülírják a hagyományos gazdasági elveket. Ez a túlzott extrapoláció rendkívül magas, fenntarthatatlan cégértékelésekhez vezetett. Amikor a valóság utolérte az irreális várakozásokat, a buborék kipukkadt, és sok befektető súlyos veszteségeket szenvedett el. Ez a példa jól mutatja, hogy az exponenciális extrapoláció rendkívül veszélyes lehet, ha nincsenek reális korlátok és alapvető gazdasági tényezők, amelyek alátámasztják.
- Olajár-előrejelzések: Az olajár a történelem során rendkívül volatilis volt. Gyakran előfordul, hogy egy tartósan magas vagy alacsony árszintet látva az elemzők egyszerűen extrapolálják ezt a trendet a jövőbe. Például, a 2008-as pénzügyi válság előtt az olajár meredeken emelkedett, és sokan „végtelen” növekedést extrapoláltak. A válság azonban hirtelen és drámaian lefelé törte a trendet. Hasonlóképpen, alacsony árak idején a túl optimista extrapolációk alábecsülhetik a visszapattanás lehetőségét. Az olajpiacot számos geopolitikai, gazdasági és technológiai tényező befolyásolja, amelyek hirtelen változhatnak, és érvénytelenné tehetik az egyszerű trendextrapolációkat.
Ezek az esettanulmányok rávilágítanak arra, hogy az extrapolációt mindig kritikus gondolkodással és a bizonytalanság tudatával kell alkalmazni. Különösen fontos figyelembe venni a külső tényezőket és a lehetséges trendtöréseket, amelyek érvényteleníthetik a múltbeli mintázatok folytatódására vonatkozó feltételezéseket.
Az adatok vizualizációja és a modellválasztás
Az adatok vizuális megjelenítése és a megfelelő modell kiválasztása szorosan összefügg, és mindkettő elengedhetetlen a pontos ismeretlen érték becsléséhez. A vizualizáció segít megérteni az adatok szerkezetét, míg a modellválasztás biztosítja, hogy a becslés alapjául szolgáló matematikai leírás a lehető legpontosabb legyen.
Grafikonok és diagramok szerepe a megértésben
Ahogy korábban említettük, a vizualizáció az első és legfontosabb lépés az adatok elemzésében. Mielőtt bármilyen matematikai modellt alkalmaznánk, érdemes megnézni az adatokat grafikonon. Egy szórásdiagram vagy vonaldiagram azonnal felfedheti:
- Trendek: Az adatok lineárisan, exponenciálisan, logaritmikusan vagy görbülten viselkednek-e?
- Periodicitás: Vannak-e ismétlődő mintázatok az adatokban (pl. szezonális ingadozások)?
- Kiugró értékek (outlierek): Vannak-e olyan adatpontok, amelyek jelentősen eltérnek a többitől?
- Adatpontok sűrűsége: Mennyire sűrűek az adatpontok, vannak-e nagy hézagok, amelyeket interpolálni kell?
A vizualizáció nemcsak a trendek azonosításában segít, hanem a modell illeszkedésének ellenőrzésében is. Miután illesztettünk egy modellt (pl. egy egyenest vagy görbét) az adatokra, érdemes ezt is megjeleníteni a grafikonon, hogy vizuálisan ellenőrizzük, mennyire írja le jól a modell az adatokat.
Különböző modellek összehasonlítása
Nincs „egy mindenre jó” modell az interpolációra és extrapolációra. A megfelelő modell kiválasztása kritikus, és gyakran több modell összehasonlítását igényli. A modellválasztás szempontjai a következők:
- Adatok jellege: Lineáris, exponenciális, periodikus, stb.
- Pontosság: Milyen mértékű pontosságra van szükség?
- Komplexitás: Az egyszerűbb modellek (pl. lineáris) kevésbé hajlamosak a túlillesztésre, de kevésbé pontosak lehetnek komplex adatoknál. A bonyolultabb modellek (pl. magas fokú polinomok, spline-ok) pontosabbak lehetnek, de nagyobb a túlillesztés kockázata.
- Extrapoláció esetén: Milyen messzire extrapolálunk? Minél távolabb, annál óvatosabban kell bánni a komplex modellekkel.
A modellek összehasonlítására statisztikai mérőszámokat is használhatunk, mint például az átlagos négyzetes hiba (Mean Squared Error, MSE), a gyökér átlagos négyzetes hiba (Root Mean Squared Error, RMSE) vagy az R-négyzet (R-squared), amelyek számszerűsítik a modell illeszkedésének jóságát. Fontos azonban megjegyezni, hogy ezek a mérőszámok elsősorban az interpolációs tartományban érvényesek, az extrapoláció megbízhatóságát nehezebb számszerűsíteni.
A modell paramétereinek finomhangolása
Sok modellnek vannak paraméterei, amelyeket finomhangolni kell a legjobb illeszkedés eléréséhez. Például, egy mozgóátlagos modellnél a „mozgóátlag” időszakának hossza befolyásolja az eredményt. A spline interpoláció esetén a „csomópontok” száma és elhelyezkedése kulcsfontosságú. A paraméterek optimális beállítását gyakran iteratív módon, próbálgatással vagy optimalizációs algoritmusokkal végzik.
A finomhangolás célja, hogy megtaláljuk azt az egyensúlyt, ahol a modell kellően pontos az ismert adatok leírásában, de nem illeszkedik túl szorosan a zajra, így jól általánosítható az ismeretlen értékek becslésére.
Szoftveres eszközök és programozási nyelvek
Az interpoláció és extrapoláció manuális számítása bonyolult és időigényes feladat, különösen nagyobb adatsorok esetén. Szerencsére számos szoftveres eszköz és programozási nyelv áll rendelkezésre, amelyek automatizálják és egyszerűsítik ezeket a folyamatokat, lehetővé téve a hatékony adatsor kiterjesztést és ismeretlen érték becslését.
Excel, Google Sheets
Az irodai szoftverek, mint az Excel és a Google Sheets, alapvető funkciókat kínálnak az adatok elemzéséhez és egyszerű becslésekhez:
- Trendvonalak: Diagramokhoz illeszthető trendvonalak (lineáris, exponenciális, logaritmikus, polinomiális) és azok egyenletei. Ezekkel egyszerű extrapoláció végezhető.
- ELŐREJELZÉS függvények: Az Excelben például a FORECAST.LINEAR, FORECAST.ETS (Exponenciális Simítás) függvények segítenek az idősoros adatok előrejelzésében.
- Adattáblák és diagramok: Könnyen létrehozhatók adattáblák és vizuális ábrázolások.
Ezek az eszközök kiválóak gyors és egyszerű becslésekhez, de korlátozottak a komplexebb modellek és a nagy adatsorok kezelésében. A vizuális illesztés és a beépített függvények segítségével azonban sok alapvető feladat elvégezhető.
Python (NumPy, SciPy, Pandas)
A Python az egyik legnépszerűbb programozási nyelv az adatelemzéshez és gépi tanuláshoz, köszönhetően gazdag könyvtári ökoszisztémájának:
- NumPy: Alapvető numerikus számításokhoz, tömbök kezeléséhez.
- SciPy: Tudományos számításokhoz, beleértve az interpolációs függvényeket (pl.
scipy.interpolate.interp1dlineáris, kubikus, stb. interpolációhoz,scipy.interpolate.splrepésscipy.interpolate.splevspline interpolációhoz). - Pandas: Adatmanipulációhoz és idősorok kezeléséhez. A DataFrame objektumok
interpolate()metódusa számos interpolációs módszert támogat. - Matplotlib/Seaborn: Adatvizualizációhoz, grafikonok és diagramok készítéséhez.
A Python ereje a rugalmasságában és a skálázhatóságában rejlik, lehetővé téve egyedi modellek építését és nagy adathalmazok hatékony kezelését.
R
Az R egy statisztikai programozási nyelv, amelyet kifejezetten adatelemzésre és statisztikai modellezésre terveztek:
- Beépített függvények: Az R számos beépített interpolációs és extrapolációs funkcióval rendelkezik (pl.
approx(),spline()). - Csomagok (packages): Számos csomag létezik fejlettebb módszerekhez, például idősor-elemzéshez (
forecastcsomag) vagy térbeli interpolációhoz (sp,gstatcsomagok Kriginghez). - Grafikus képességek: Az R kiváló grafikus képességekkel rendelkezik (
ggplot2), amelyek segítenek az adatok és a modell illesztésének vizualizálásában.
Az R különösen népszerű az akadémiai és kutatói körökben, valamint a statisztikai modellezést igénylő területeken.
MATLAB
A MATLAB egy numerikus számítási környezet és programozási nyelv, amelyet mérnöki és tudományos alkalmazásokhoz használnak:
- Beépített interpolációs és extrapolációs függvények: A MATLAB számos függvényt kínál (pl.
interp1,interp2,interp31D, 2D és 3D interpolációhoz, különböző módszerekkel). - Toolboxok: Különböző toolboxok, mint például a Curve Fitting Toolbox, fejlett eszközöket biztosítanak a görbék illesztéséhez és az adatok modellezéséhez.
- Szimuláció: A MATLAB kiválóan alkalmas szimulációk futtatására és komplex rendszerek modellezésére.
A MATLAB erős numerikus képességei miatt ideális választás a mérnöki és fizikai tudományokban, ahol a pontos matematikai modellezés kulcsfontosságú.
Speciális statisztikai szoftverek
Vannak olyan szoftverek is, amelyeket kifejezetten statisztikai elemzésekre és prediktív modellezésre fejlesztettek ki:
- SAS, SPSS, Stata: Ezek a szoftverek széles körű statisztikai elemzési és modellezési képességeket kínálnak, beleértve az idősor-elemzést és a hiányzó adatok kezelését.
- Tableau, Power BI: Bár elsősorban adatvizualizációs eszközök, alapvető trendelemzési és előrejelzési funkciókat is tartalmazhatnak.
A megfelelő eszköz kiválasztása az egyéni preferenciáktól, a projekt méretétől és a szükséges komplexitás szintjétől függ. A lényeg, hogy az eszköz támogassa a választott módszert, és segítse az adatok hatékony elemzését és a megbízható becslések elkészítését.
Etikai megfontolások és felelősség
Az adatelemzés, különösen az ismeretlen érték becslése, nem csupán technikai, hanem etikai kérdéseket is felvet. Mivel az interpoláció és az extrapoláció nagyban befolyásolhatja a döntéshozatalt és a jövőbeni stratégiákat, elengedhetetlen a felelős és etikus megközelítés.
Az eredmények helyes kommunikációja
Az adatelemzők és szövegírók feladata nem csupán az eredmények előállítása, hanem azok világos és pontos kommunikációja is. Fontos, hogy a hallgatóság vagy olvasók megértsék:
- Mi az interpoláció/extrapoláció? Tisztázzuk, hogy a bemutatott értékek becslések, nem pedig tények.
- Milyen feltételezésekre épült a modell? Magyarázzuk el a modell mögötti alapvető feltételezéseket (pl. lineáris trend folytatódása), és hogy ezek mennyire reálisak.
- Melyek a modell korlátai? Világosan mutassuk be a modell gyengeségeit, az adatok minőségéből adódó bizonytalanságokat és az esetleges trendtörések kockázatát.
A túlzottan magabiztos vagy félrevezető kommunikáció súlyos következményekkel járhat, különösen, ha az extrapoláció a jövőre vonatkozó előrejelzéseket tartalmaz, amelyek alapján pénzügyi vagy stratégiai döntéseket hoznak.
A bizonytalanság jelzése
Az egyik legfontosabb etikai kötelezettség a becslésekhez kapcsolódó bizonytalanság jelzése. Soha ne adjunk meg egyetlen „pontos” előrejelzést anélkül, hogy ne jeleznénk a hibahatárt vagy a konfidencia intervallumot. Ez különösen igaz az extrapolációra, ahol a bizonytalanság exponenciálisan növekszik az ismert adatoktól való távolsággal.
- Konfidencia intervallumok: Mutassuk be azokat a tartományokat, amelyeken belül a becsült érték várhatóan elhelyezkedik egy bizonyos valószínűséggel (pl. 95%-os konfidencia intervallum).
- Szcenárió alapú elemzés: Extrapoláció esetén érdemes több lehetséges forgatókönyvet is bemutatni (optimista, pesszimista, reális), amelyek különböző feltételezésekre épülnek, így átfogóbb képet adnak a jövőbeni lehetőségekről.
A bizonytalanság őszinte kommunikációja növeli az elemzés hitelességét és segít a döntéshozóknak reálisabb elvárásokat támasztani az előrejelzésekkel szemben.
Manipuláció elkerülése
Az adatelemzők és szövegírók felelőssége, hogy objektíven és semlegesen mutassák be az eredményeket. El kell kerülni minden olyan kísérletet, amely az adatokat vagy a modelleket manipulálja egy előre meghatározott narratíva vagy kívánt eredmény alátámasztására. Ez magában foglalhatja:
- Szelektív adatválasztás: Csak azoknak az adatoknak a felhasználása, amelyek egy bizonyos trendet támasztanak alá, figyelmen kívül hagyva a többit.
- Modelltorzítás: Egy olyan modell kiválasztása, amely mesterségesen „szépíti” az eredményeket, még ha az nem is a legmegfelelőbb az adatokhoz.
- Az eredmények félreértelmezése: A konklúziók levonása, amelyek nem következnek logikusan a modellből, vagy túlértékelik annak pontosságát.
Az etikus adatelemzés alapja az átláthatóság, a függetlenség és az objektivitás. Az ismeretlen érték becslése során mindig arra kell törekedni, hogy a lehető legpontosabb és legmegbízhatóbb képet mutassuk be, még akkor is, ha az eredmények nem egyeznek meg a kívántakkal.
Az interpoláció és az extrapoláció tehát rendkívül erőteljes eszközök, amelyekkel a hiányzó információkat pótolhatjuk és a jövőbeni trendeket előre jelezhetjük. Azonban erejükkel együtt nagy felelősség is jár. A módszerek mélyreható ismerete, az adatok kritikus szemlélete, a bizonytalanság jelzése és az etikus kommunikáció alapvető fontosságú ahhoz, hogy ezeket az eszközöket valóban a döntéshozatal támogatására és a tudás bővítésére használjuk.