Powerful AI that takes care of your daily tasks. Stop manually processing your text, document, and image data. Let AI work its magic, without a single line of code.
Elveszítenéd az adataidat egy meghibásodás miatt? Az "Erasure coding" segít! Képzeld el, hogy az adataidat apró darabokra vágjuk, és elosztjuk több helyre, ráadásul extra "mentőövekkel" látjuk el. Ha egy darab elveszik, a többiekből még helyreállítható az egész. Így biztonságban tudhatod az adataidat, akár egy szerverhiba esetén is!
Az Erasure Coding (EC) egy fejlett adattárolási technika, amely az adatvesztés elleni védelemre összpontosít. Alapelve, hogy az adatokat kisebb darabokra, úgynevezett fragmentekre bontja, majd redundáns adatokat (paritás biteket) hoz létre ezekből a fragmentekből.
A lényeg, hogy még ha bizonyos számú fragment (eredeti adat és redundáns adatok) elveszik is, az eredeti adatok a megmaradt fragmentekből helyreállíthatóak. Ez a módszer jelentősen növeli az adattárolási rendszerek hibatűrő képességét.
Az EC különösen hasznos elosztott tárolási rendszerekben, ahol az adatok több fizikai helyen vannak tárolva. Ilyen rendszerekben a hardverhibák, hálózati problémák vagy akár katasztrófák is okozhatnak adatvesztést.
Az EC lehetővé teszi, hogy a rendszer továbbra is működőképes maradjon és az adatokhoz hozzáférjen, még akkor is, ha a tárolási helyek egy része kiesik.
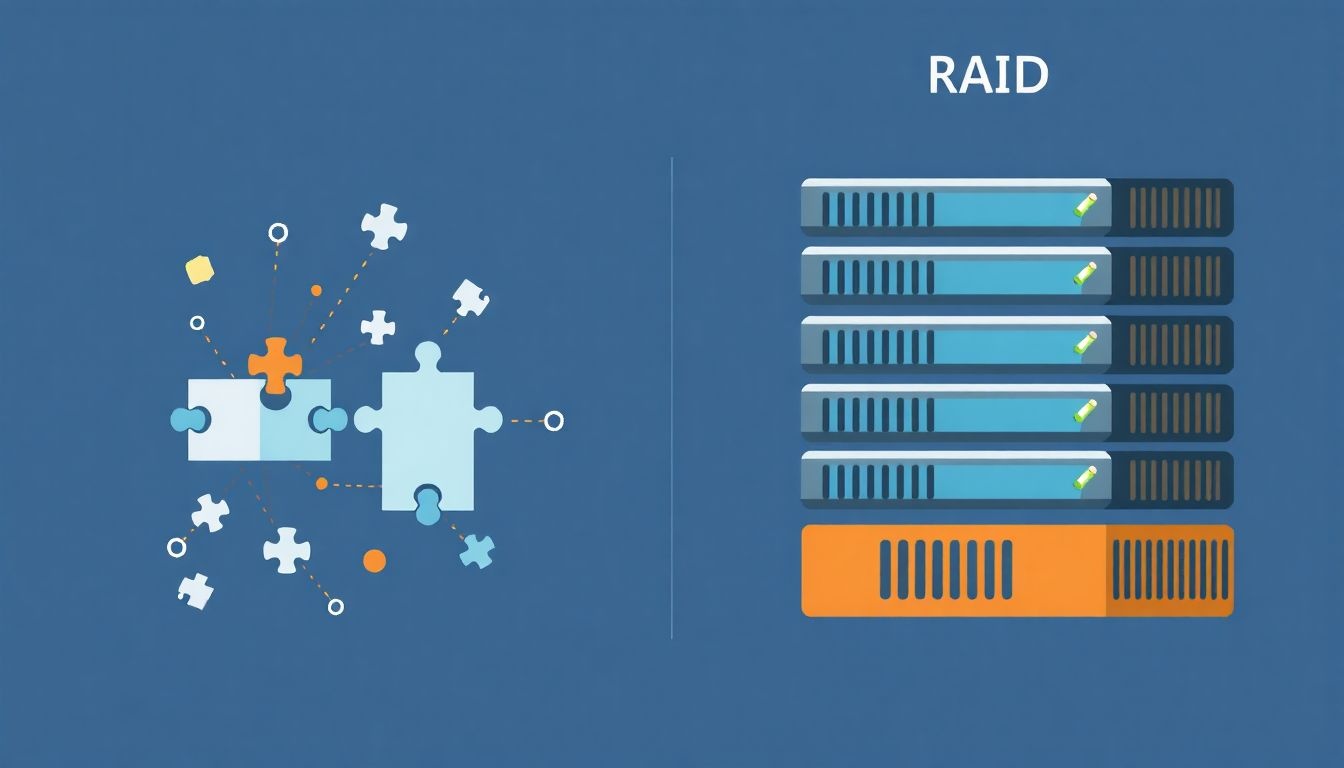
Az EC nem csupán adatmentést biztosít; emellett optimalizálja a tárolási hatékonyságot is. A redundáns adatok mennyisége szabályozható, lehetővé téve a felhasználók számára, hogy egyensúlyt teremtsenek a tárhelykihasználás és a hibatűrés között. Ez azt jelenti, hogy kevesebb redundanciával is elérhető a kívánt szintű adatvédelem, mint például a hagyományos tükrözéses megoldásokkal (RAID).
Az EC implementációi különböző algoritmusokat használhatnak, mint például a Reed-Solomon kódolást. A választott algoritmus befolyásolja a rendszer teljesítményét, a redundancia mértékét és a helyreállítási időt.
Az Erasure Coding alapelve: Fragmentálás, redundancia és elosztott tárolás
Az Erasure Coding (EC) egy adatvédelmi módszer, amely az adatokat fragmentálással, redundáns adatokkal és elosztott tárolással védi. Ez a megközelítés hatékonyan kezeli az adattárolási rendszerekben előforduló hibákat és adatvesztést. A hagyományos tükrözéssel (RAID) szemben, az EC kevesebb tárolási overhead-del képes hasonló vagy jobb adatbiztonságot nyújtani.
Az EC alapja, hogy az eredeti adatot kisebb darabokra, úgynevezett adatfragmentumokra bontja. Például egy fájlt 10 fragmentumra oszthatunk. Ezt követően, az EC algoritmus redundáns fragmentumokat generál. Ezek a redundáns fragmentumok az eredeti adatfragmentumokból származnak, és lehetővé teszik az adatok helyreállítását akkor is, ha néhány fragmentum elveszik vagy sérül.
A redundáns fragmentumok száma határozza meg, hogy hány fragmentum elvesztése esetén is helyreállítható az eredeti adat. Például, ha 10 adatfragmentumunk van és 4 redundáns fragmentumot generálunk, akkor bármely 4 fragmentum elvesztése esetén is képesek vagyunk az eredeti adat helyreállítására. Ezt (n, k) kódolásnak is nevezik, ahol ‘n’ a teljes fragmentumok száma (adat- és redundáns fragmentumok együtt), és ‘k’ az eredeti adatfragmentumok száma.
Az Erasure Coding lényege, hogy az adatok helyreállíthatók legyenek akkor is, ha az adatok egy része elveszik. Ezt a redundáns fragmentumok biztosítják, amelyek lehetővé teszik az eredeti adatok rekonstrukcióját.
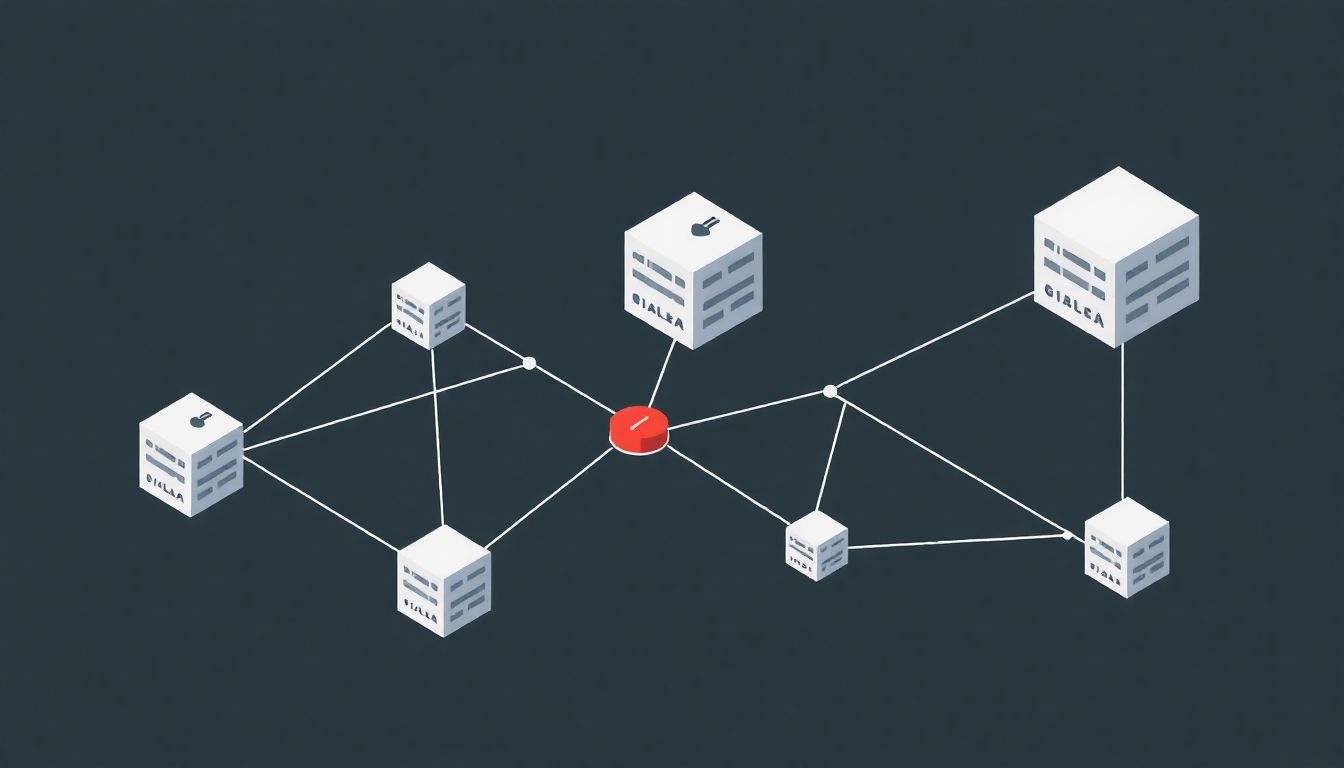
A fragmentumokat ezután elosztottan tárolják a tárolórendszer különböző csomópontjain vagy eszközein. Ez biztosítja, hogy egyetlen meghibásodási pont ne veszélyeztesse az összes adatot. Ha egy csomópont vagy eszköz meghibásodik, a többi csomóponton lévő fragmentumok felhasználásával az elveszett fragmentumok rekonstruálhatók, és az adatok elérhetők maradnak.
Az EC alkalmazása számos előnnyel jár:
Magasabb adatbiztonság: Több hiba tolerálása, mint a RAID esetében.
Jobb tárolási hatékonyság: Kevesebb overhead a tükrözéshez képest, különösen nagy adathalmazok esetén.
Rugalmasság: Az EC paraméterei (n, k) konfigurálhatók az adatbiztonsági és tárolási hatékonysági igényeknek megfelelően.
Az EC implementációja komplex matematikai algoritmusokat (például Reed-Solomon kódolást) használ, amelyek biztosítják a hatékony adatfragmentálást, redundancia generálást és helyreállítást. A teljesítmény optimalizálása érdekében a modern EC implementációk hardveres gyorsítást és párhuzamos feldolgozást alkalmaznak.
A redundancia szerepe az adatvesztés elleni védelemben
Az Erasure Coding (EC) egy olyan adatvédelmi módszer, amely a redundanciát használja fel az adatvesztés elleni védelemre. Lényege, hogy az adatokat kisebb részekre, úgynevezett fragmentumokra bontja, majd ezekhez redundáns adatokkal kiegészítve tárolja azokat elosztottan.
A redundáns adatok, más néven paritás bitek, matematikai algoritmusok segítségével jönnek létre az eredeti adatfragmentumokból. Ezek a paritás bitek lehetővé teszik az elveszett adatfragmentumok rekonstruálását anélkül, hogy az eredeti adatokhoz hozzá kellene férni. Minél több a redundancia, annál több fragmentum elvesztését képes elviselni a rendszer anélkül, hogy adatvesztés történne.
Az EC lényege, hogy az adatokat nem csak egyszerűen lemásolja (mint a RAID rendszerek), hanem matematikai számítások segítségével redundáns információt hoz létre, ami hatékonyabb tárolást és nagyobb adatbiztonságot eredményez.
Az EC rendszerekben gyakran használt technika az (n,k) séma. Ebben az „n” a tárolt fragmentumok teljes számát jelöli (eredeti adatok + redundáns adatok), a „k” pedig az eredeti adatfragmentumok számát. Tehát, ha egy (10,6) EC sémát használunk, akkor az azt jelenti, hogy az adatokat 6 fragmentumra bontjuk, majd 4 redundáns fragmentumot hozunk létre. Ebben az esetben a rendszer képes helyreállítani az adatokat akkor is, ha legfeljebb 4 fragmentum elveszik.
A redundancia mértéke befolyásolja a rendszer tárolási hatékonyságát. Több redundancia nagyobb adatbiztonságot, de kisebb tárolási hatékonyságot jelent, mivel több helyet foglalnak el a redundáns adatok. Kevesebb redundancia pedig kisebb adatbiztonságot, de nagyobb tárolási hatékonyságot eredményez. A megfelelő redundancia szint kiválasztása a felhasználói igények és a kockázattűrés függvénye.
Az EC alkalmazása különösen előnyös olyan rendszerekben, ahol nagy mennyiségű adatot kell tárolni, és ahol az adatvesztés kockázata jelentős. Ilyenek például a felhőalapú tárolók, az archív rendszerek és a nagyteljesítményű számítástechnikai rendszerek.
Párosszámítás (Parity) alapú EC rendszerek
A párosszámítás alapú EC rendszerek egyszerű hibajavítást tesznek lehetővé, hatékonyan detektálva és korrigálva az adatvesztéseket.
A párosszámítás (parity) alapú Erasure Coding (EC) rendszerek a legyszerűbb és legkorábbi EC implementációk közé tartoznak. Az alapelvük az, hogy az adatokból egy vagy több paritásbitet számítanak ki, amelyek lehetővé teszik az elveszett adatok helyreállítását.
A legegyszerűbb példa a szimpla paritás, ahol az adatokból egyetlen paritásbitet generálunk. Ez a bit azt jelzi, hogy az adatokban lévő 1-esek száma páros vagy páratlan. Ha egy adatblokk elveszik, a paritásbit segítségével megállapítható, hogy az elveszett blokk értéke 0 vagy 1 volt.
A RAID 5 egy elterjedt példa a párosszámítás alapú EC-re. Itt az adatok több lemezen vannak elosztva, és minden csíkhoz (stripe) tartozik egy paritáslemez. Ha egy lemez meghibásodik, a paritásinformáció segítségével a többi lemezen lévő adatokból visszaállítható az elveszett adat.
A párosszámítás fő előnye az egyszerűség és az alacsony számítási igény.
Azonban a párosszámítás alapú EC rendszerek korlátozott hibatűréssel rendelkeznek. A szimpla paritás csak egyetlen hiba javítására alkalmas. A RAID 5 is csak egy lemez meghibásodását képes tolerálni.
A kiterjesztett paritás technikák, mint például a Reed-Solomon kódok, több paritásbitet használnak, így több hiba javítására is képesek. Ezek a rendszerek azonban bonyolultabb számításokat igényelnek.
Például, ha *k* adatblokkunk van, akkor *m* paritásblokkot generálhatunk. Ekkor *k+m* blokkból bármely *k* blokk elegendő az eredeti adatok helyreállításához. A paritásblokkok elosztása kritikus fontosságú a rendszer teljesítménye és megbízhatósága szempontjából.
Reed-Solomon kódolás: Matematikai alapok és működési elv
A Reed-Solomon (RS) kódolás egy erős hibajavító kód, amelyet széles körben használnak az adattárolásban és -átvitelben az adatok integritásának biztosítására. Az erasure coding (EC) egyik legnépszerűbb implementációja, melynek lényege az adatok fragmentálása, redundáns adatok generálása, és az adatok elosztott tárolása. Az RS kódolás különösen hatékony abban az esetben, ha az adatok elveszhetnek vagy sérülhetnek, de nem korrumpálódnak.
Az RS kódolás alapja a véges testeken (Galois-mezők) végzett polinomaritmetika. Képzeljünk el egy üzenetet, melyet *k* darab adatblokkra bontunk (például bájtokra). Az RS kódolás célja, hogy ehhez az *k* darab adatblokkhoz *n-k* darab redundáns (paritás) blokkot generáljon, így összesen *n* blokkot kapunk. Ezek az *n* blokkok egy polinom együtthatóit reprezentálják egy véges test felett.
A kódolás során először egy *k*-adfokú polinomot definiálunk, melynek együtthatói az eredeti adatblokkok. Ezt a polinomot *P(x)*-szel jelöljük. Ezután *n* különböző pontban kiértékeljük ezt a polinomot. Ezek a pontok (x1, x2, …, xn) a véges test elemei. A kiértékelések eredményei (P(x1), P(x2), …, P(xn)) adják az *n* darab kódolt blokkot. Az első *k* blokk általában az eredeti adatblokkok, a maradék *n-k* pedig a redundáns blokkok.
Az RS kódolás egyik legnagyobb előnye, hogy az eredeti *k* adatblokk bármely *k* darab kódolt blokkból visszaállítható.
A dekódolás során, ha az *n* darab kódolt blokkból legfeljebb *n-k* darab hiányzik vagy sérült, az eredeti *k*-adfokú polinom egyértelműen rekonstruálható a megmaradt blokkokból. Ez a polinom rekonstrukciója például Lagrange-interpolációval vagy más polinom-interpolációs technikákkal történhet. A polinom rekonstrukciója után az eredeti *k* adatblokk egyszerűen kiolvasható a polinom együtthatóiból.
Az RS kódolás hatékonysága a redundancia mértékétől függ. Minél nagyobb az *n-k* különbség (azaz minél több a redundáns blokk), annál több hibát vagy adatvesztést képes elviselni a rendszer. Ugyanakkor a nagyobb redundancia nagyobb tárolási és számítási igényt is jelent.
A gyakorlatban az RS kódolást gyakran használják RAID rendszerekben, optikai lemezeken (például CD-ken és DVD-ken), valamint a mélyűri kommunikációban. Az RS kódolás lehetővé teszi, hogy ezek a rendszerek ellenállóak legyenek az adatvesztéssel szemben, és biztosítsák az adatok integritását még kedvezőtlen körülmények között is.
Példa: Tegyük fel, hogy k=3 adatblokkunk van, és n=5 kódolt blokkot szeretnénk generálni. Ebben az esetben n-k=2 redundáns blokkot hozunk létre. Ha a 5 blokkból bármelyik 2 elveszik, a maradék 3 blokk segítségével még mindig vissza tudjuk állítani az eredeti 3 adatblokkot.
A Galois-mezők (véges testek) kulcsfontosságúak az RS kódolás szempontjából. Ezek a mezők lehetővé teszik a polinomaritmetika elvégzését véges számú elemmel, ami hatékony implementációt tesz lehetővé. A leggyakrabban használt Galois-mező a GF(28), amely 256 elemet tartalmaz, és kiválóan alkalmas bájtokkal történő munkára.
A Reed-Solomon kódolás előnyei és hátrányai
A Reed-Solomon (RS) kódolás az egyik legelterjedtebb törlésjavító kód (erasure coding) a gyakorlatban. Előnye, hogy optimális, azaz a lehető legkevesebb redundáns adatot generálja ahhoz, hogy a kívánt hibatűrést elérje. Ez azt jelenti, hogy ha *k* adatblokkunk van, és *n* adatblokkot szeretnénk létrehozni (ahol *n > k*), akkor az RS kódolás képes helyreállítani az eredeti *k* blokkot, ha legfeljebb *n – k* blokk elveszik vagy sérül.
Az RS kódolás másik előnye a rugalmassága. A *k* és *n* paraméterek szabadon választhatók, ami lehetővé teszi a rendszer optimális konfigurálását az adott alkalmazás követelményeihez igazodva. Például, egy nagy megbízhatóságot igénylő rendszerben nagyobb *n – k* érték választható, míg egy hatékonyságra törekvő rendszerben kisebb.
Ugyanakkor az RS kódolásnak vannak hátrányai is. Az egyik a számítási komplexitás. A kódolási és dekódolási műveletek CPU-igényesek, különösen nagy méretű adatok esetén. Ez teljesítménybeli szűk keresztmetszetet jelenthet nagy áteresztőképességű rendszerekben.
A Reed-Solomon kódolás dekódolása lényegesen bonyolultabb és erőforrásigényesebb, mint a kódolás.
Egy másik hátrány a korlátozott hibajavító képesség bizonyos esetekben. Az RS kódolás hatékonyan kezeli a törléseket (amikor tudjuk, mely blokkok vesztek el), de kevésbé hatékony a hibák javításában (amikor nem tudjuk pontosan, hol sérült az adat). Bár léteznek RS kódolás variánsok, amelyek képesek hibákat is javítani, ezek még komplexebbek és számításigényesebbek.
Végül, az RS kódolás implementációja összetett lehet, ami növeli a fejlesztési időt és a hibák kockázatát. Bár léteznek kész könyvtárak és implementációk, a hatékony és robusztus RS kódolás megvalósítása alapos ismereteket igényel a kódolási elméletben.
Az EC alkalmazási területei: Felhő tárolás, archiválás és nagyméretű adathalmazok
Az Erasure Coding (EC) technológia az adatvédelem és a tárolási hatékonyság kulcsfontosságú eleme a modern adatközpontokban és felhő alapú szolgáltatásokban. Az EC különösen hasznos az olyan területeken, ahol a nagy mennyiségű adat megbízható és költséghatékony tárolása elengedhetetlen.
A felhő tárolás területén az EC lehetővé teszi a szolgáltatók számára, hogy az adatokat elosztva tárolják több szerveren vagy tárolóegységen. Ez azt jelenti, hogy még ha néhány szerver meghibásodik is, az adatok továbbra is helyreállíthatók a redundáns információk segítségével. Ezáltal a szolgáltatók magasabb rendelkezésre állást és adatbiztonságot tudnak garantálni az ügyfeleik számára, miközben optimalizálják a tárolási költségeket.
Az archiválás egy másik fontos alkalmazási terület. A hosszú távú adattárolás során az adatok sérülése vagy elvesztése komoly problémát jelenthet. Az EC használatával az archivált adatok fragmentálva és redundáns kódokkal kiegészítve kerülnek tárolásra. Ez biztosítja, hogy az adatok még akkor is helyreállíthatók legyenek, ha a tárolóeszközök egy része elavul vagy meghibásodik. Ez a módszer különösen fontos a kritikus fontosságú adatok, például jogi dokumentumok, orvosi feljegyzések vagy pénzügyi adatok esetében.
Az EC lehetővé teszi a nagyméretű adathalmazok hatékony és megbízható tárolását, miközben minimalizálja a tárolási költségeket és maximalizálja az adatbiztonságot.
A nagyméretű adathalmazok, mint például a big data analitikához használt adatok, szintén profitálhatnak az EC előnyeiből. Ezek az adathalmazok gyakran több petabájtos méretűek lehetnek, és a hagyományos RAID megoldások nem feltétlenül skálázhatók hatékonyan ilyen méretekben. Az EC viszont lehetővé teszi az adatok elosztott tárolását, és a redundancia révén biztosítja az adatok integritását még nagyméretű adathalmazok esetében is. Ezenkívül az EC segíthet csökkenteni a tárolási költségeket azáltal, hogy kevesebb redundáns adatot tárol, mint a hagyományos tükrözési módszerek.
Az EC különböző kódolási algoritmusokat használ, például a Reed-Solomon kódolást, amelyek lehetővé teszik az adatok helyreállítását még akkor is, ha az adatok egy jelentős része elveszik. A kódolási séma megválasztása függ az alkalmazás követelményeitől, például a kívánt redundancia szintjétől és a helyreállítási sebességtől.
Erasure Coding vs. RAID: Összehasonlítás és különbségek
Az erasure coding hatékonyabb adatvédelem, mint a RAID, mivel kevesebb redundanciával nagyobb hibajavítást kínál.
Az Erasure Coding (EC) és a RAID egyaránt adatvédelmi megoldások, de jelentősen eltérnek a működési elvükben és a felhasználási területeikben.
A RAID (Redundant Array of Independent Disks) többféle konfigurációban létezik, melyek mindegyike a redundanciát használja az adatok védelmére. Például a RAID 1 tükrözi az adatokat, míg a RAID 5 paritási információkat használ, hogy egy lemez meghibásodása esetén is helyreállíthatók legyenek az adatok. A RAID rendszerek általában egyetlen gépen belül, vagy egyetlen tárolórendszeren belül működnek.
Ezzel szemben az Erasure Coding az adatokat fragmentálja, majd redundáns adatokat (általában paritási blokkokat) generál. Ezeket a fragmentumokat és paritási blokkokat aztán elosztva tárolja több tárolóeszközön vagy akár gépen. Ez a elosztott tárolás teszi lehetővé, hogy az EC rendszerek sokkal jobban tolerálják a hibákat, mint a RAID.
Az Erasure Coding legnagyobb előnye a RAID-del szemben a jelentősen nagyobb hibatűrés és a rugalmasabb elosztás lehetősége.
A RAID rendszerek általában gyorsabb helyreállítást tesznek lehetővé egy lemez meghibásodása után, mert a helyreállítás lokálisan történik. Az EC helyreállítása viszont időigényesebb lehet, mivel több tárolóeszközről kell adatot gyűjteni. Ugyanakkor az EC sokkal hatékonyabban használja ki a tárolókapacitást, különösen nagy rendszerekben. A RAID-nél a redundancia miatt jelentős tárolókapacitás veszik el, míg az EC-nél a redundancia mértéke finomabban szabályozható, így a tárolókapacitás hatékonyabban használható.
Összefoglalva, a RAID ideális lehet kisebb, gyors helyreállítást igénylő rendszerekhez, míg az Erasure Coding a nagy, elosztott, hibatűrő tárolórendszerekben nyújt kiváló megoldást.
Az EC teljesítményének befolyásoló tényezői: Kódolási és dekódolási sebesség
Az Erasure Coding (EC) teljesítménye nagymértékben függ a kódolási és dekódolási folyamatok sebességétől. Ezek a folyamatok határozzák meg, hogy milyen gyorsan tudunk adatokat tárolni és helyreállítani, ami kritikus fontosságú a nagy teljesítményű tárolórendszerekben.
A kódolási sebesség azt mutatja meg, hogy mennyi időbe telik az eredeti adatokból a redundáns adatok létrehozása és az adatok fragmentálása. Minél gyorsabb a kódolás, annál kisebb a terhelés a rendszeren, és annál gyorsabban kerülhetnek az adatok tárolásra. Ezt számos tényező befolyásolja, többek között:
A választott EC séma komplexitása.
A hardver erőforrások (CPU, memória) rendelkezésre állása.
A szoftveres implementáció hatékonysága.
A dekódolási sebesség pedig azt mutatja meg, hogy mennyi időbe telik a sérült vagy hiányzó adatok helyreállítása a megmaradt fragmentek és a redundáns adatok segítségével. A gyors dekódolás elengedhetetlen ahhoz, hogy az adatokhoz való hozzáférés ne szenvedjen jelentős késleltetést adatvesztés esetén. A dekódolási sebességet befolyásolja:
A sérült vagy hiányzó fragmentek száma.
A választott EC séma dekódolási komplexitása.
A dekódolást végző hardver teljesítménye.
A kódolási és dekódolási sebesség optimalizálása kulcsfontosságú a hatékony és megbízható EC implementációhoz.
A különböző EC sémák (pl. Reed-Solomon, Cauchy Reed-Solomon) eltérő kódolási és dekódolási komplexitással rendelkeznek. A Reed-Solomon széles körben elterjedt, de számításigényes lehet. A Cauchy Reed-Solomon pedig gyorsabb kódolást és dekódolást kínálhat bizonyos hardvereken. A megfelelő EC séma kiválasztása az adott alkalmazás követelményeitől és a rendelkezésre álló erőforrásoktól függ.
Emellett a hardveres gyorsítás, például FPGA-k vagy speciális ASIC-ek használata jelentősen javíthatja a kódolási és dekódolási sebességet. A szoftveres optimalizációk, mint például a párhuzamosítás és a hatékony algoritmusok alkalmazása szintén fontos szerepet játszanak a teljesítmény növelésében.
Hálózati sávszélesség és az EC hatékonysága
Az Erasure Coding (EC) hatékonysága szorosan összefügg a hálózati sávszélességgel. Míg az EC jelentős mértékben képes csökkenteni a tárolási overhead-et a replikációhoz képest, a helyreállítási folyamat nagymértékben függ a hálózati teljesítménytől.
Amikor egy adat fragmentum elveszik, a rendszernek le kell töltenie a megmaradt fragmentumokat a tárolási csomópontokról, hogy újra tudja generálni az elveszett adatot. Ez jelentős hálózati forgalmat generálhat, különösen akkor, ha nagyméretű adatblokkokat kell helyreállítani.
A megfelelő EC séma kiválasztása kulcsfontosságú. Az (n, k) kódolás azt jelenti, hogy n számú fragmentumra osztunk egy adatot, amiből k számú elegendő az eredeti adat helyreállításához. Minél kisebb a k érték (azaz kevesebb fragmentum szükséges a helyreállításhoz), annál kevésbé terheli a hálózatot a helyreállítás.
A hálózati sávszélesség korlátai befolyásolják az EC alkalmazhatóságát. Gyenge hálózati kapcsolat esetén a helyreállítás lassú és megbízhatatlan lehet, ami veszélyezteti az adatok elérhetőségét. Ezért a hálózati infrastruktúrát figyelembe kell venni az EC paramétereinek beállításakor. Például, egy nagy sávszélességű hálózat lehetővé teszi a magasabb redundancia használatát (nagyobb n érték), ami javítja az adatvédelmet, míg egy korlátozott sávszélességű hálózat alacsonyabb redundanciát igényel a gyorsabb helyreállítás érdekében.
A geografikusan elosztott tárolási rendszerekben, ahol a csomópontok nagy távolságra vannak egymástól, a hálózati késleltetés tovább bonyolítja a helyzetet. Ebben az esetben a lokalitás optimalizálása, azaz a helyreállításhoz szükséges fragmentumok minél közelebbi elhelyezése, kritikus fontosságú a hálózati terhelés csökkentése érdekében.
Tárolási költségek optimalizálása az EC segítségével
Az Erasure Coding (EC) egy olyan adatvédelmi módszer, amely töredezi az adatokat, redundáns információkat hoz létre, és azokat elosztva tárolja. Ez a megközelítés jelentősen csökkentheti a tárolási költségeket a hagyományos replikációs módszerekhez képest. A replikáció esetén minden adatot többször lemásolunk, míg az EC esetében csak a szükséges redundáns adatmennyiséget tároljuk.
Az EC lényege, hogy az adatokat kisebb darabokra bontjuk, majd ezekből további, úgynevezett paritásos (redundáns) darabokat generálunk. Ezek a paritásos darabok lehetővé teszik az eredeti adatok helyreállítását abban az esetben, ha néhány adattöredék elveszik.
Az EC használatával kevesebb tárhelyre van szükség ugyanazon szintű adatvédelem eléréséhez, mint a replikációval.
Például, egy EC séma lehet 6+3, ami azt jelenti, hogy 6 adattöredékből 3 paritásos töredéket generálunk. Ebben az esetben az adatok akkor is helyreállíthatók, ha bármelyik 3 töredék (adattöredék vagy paritásos töredék) elveszik. Ez jóval hatékonyabb helykihasználást eredményez, mint a háromszoros replikáció, ahol az adatok háromszoros mennyiségét kell tárolni.
Az EC alkalmazásával a szervezetek jelentős költségmegtakarítást érhetnek el, különösen nagyméretű adattárolási rendszerek esetén. Ráadásul, az adatok elosztott tárolása növeli a rendszer hibatűrő képességét is.
Az EC implementáció kihívásai: Komplexitás és erőforrásigény
Az EC implementációja során a komplexitás és magas erőforrásigény jelentős kihívást jelent a hatékony működéshez.
Az EC implementációja komoly kihívásokat tartogat, főként a számítási komplexitás és az erőforrásigény miatt. A fragmentálás és a redundáns adatok létrehozása CPU-igényes feladat, különösen nagyméretű adathalmazok esetén. A helyreállítási folyamat, amikor elveszett adatokat kell rekonstruálni, még nagyobb terhet ró a rendszerre.
A kódolási és dekódolási algoritmusok optimalizálása kulcsfontosságú a teljesítmény javítása érdekében. A választott EC séma jelentősen befolyásolja a szükséges számítási kapacitást. Például a Reed-Solomon kódok erőteljesek, de komplexebb számításokat igényelnek, mint a egyszerűbb XOR-alapú megoldások.
Az EC hatékony implementációja jelentős beruházást igényelhet a megfelelő hardveres infrastruktúrába és szoftveres optimalizációba.
Az elosztott tárolási környezetben a hálózati sávszélesség és a késleltetés szintén kritikus tényezők. Az adatok fragmentálása és terjesztése a hálózaton keresztül jelentős hálózati forgalmat generál, ami befolyásolhatja a rendszer általános teljesítményét. A helyreállítási folyamat során az elveszett fragmentumok rekonstruálása további hálózati terhelést okoz.
A tárolási költségek is figyelembe veendők. Bár az EC általában hatékonyabban használja ki a tárolókapacitást, mint a replikáció, a redundáns adatok tárolása további tárhelyet igényel. A redundancia mértékének (azaz a kódolási aránynak) a megfelelő beállítása elengedhetetlen a költségek és a hibatűrés közötti egyensúly megteremtéséhez.
Az EC biztonsági szempontjai: Adatvédelem és integritás
Az Erasure Coding (EC) jelentős előnyöket kínál az adatvédelem terén. A fragmentálás, a redundáns adatok létrehozása, és az elosztott tárolás kombinációja révén az EC hatékonyan védi az adatokat a meghibásodásoktól és az illetéktelen hozzáféréstől.
A fragmentálás során az adatokat kisebb darabokra bontjuk, ami megnehezíti a teljes adat rekonstruálását, ha nem áll rendelkezésre elegendő fragmentum. A redundáns adatok, vagyis a paritás bitek, lehetővé teszik az elveszett fragmentumok helyreállítását.
Az EC egyik legfontosabb biztonsági előnye, hogy még akkor is hozzáférhető marad az adat, ha bizonyos tárolócsomópontok meghibásodnak vagy kompromittálódnak.
Az elosztott tárolás tovább növeli a biztonságot, mivel az adatok több fizikai helyszínen vannak elhelyezve. Ez megakadályozza, hogy egyetlen ponton történő támadás veszélyeztesse az egész adathalmazt. Emellett, ha egy támadó hozzáfér néhány fragmentumhoz, a teljes adat rekonstruálásához a többi fragmentumhoz is hozzá kell férnie, ami jelentősen növeli a támadás komplexitását.
Azonban fontos megjegyezni, hogy az EC nem helyettesíti a titkosítást. Bár az EC megnehezíti az adatokhoz való hozzáférést, a titkosítás továbbra is elengedhetetlen az adatok bizalmasságának megőrzéséhez. A titkosítás és az EC együttes alkalmazása a legbiztonságosabb megoldás az adatok védelmére.
Az EC és az adattitkosítás kapcsolata
Az EC önmagában nem adattitkosítás, de jelentősen növeli az adatbiztonságot és az adattitkosítás hatékonyságát. Az adatok fragmentálása és elosztása révén az EC megnehezíti az illetéktelen hozzáférést. Egy támadónak sokkal több helyről kell adatokat gyűjtenie ahhoz, hogy rekonstruálni tudja az eredeti fájlt.
Az EC és az adattitkosítás kombinációja egy erős védelmi vonalat hoz létre. Az adattitkosítás biztosítja, hogy az egyes fragmentumok értelmezhetetlenek legyenek, míg az EC garantálja az adatok elérhetőségét és integritását még akkor is, ha néhány fragmentum elveszik vagy sérül.
Az EC nem helyettesíti az adattitkosítást, hanem kiegészíti azt, növelve az adatok biztonságát és ellenálló képességét a támadásokkal szemben.
Képzeljük el, hogy egy titkosított fájlt EC-vel felosztunk. Még ha egy támadó meg is szerez néhány fragmentumot, azok hasznavehetetlenek maradnak a titkosítás miatt. Ráadásul, a teljes fájl rekonstrukciójához szükséges fragmentumok összegyűjtése rendkívül nehéz és időigényes feladat.
Az EC használata során elengedhetetlen a megfelelő fragmentálási és redundancia stratégia kiválasztása. A túl kevés redundancia csökkenti a hibatűrést, míg a túl sok redundancia növeli a tárolási költségeket. A titkosítás kulcsainak megfelelő kezelése szintén kritikus fontosságú az adatok biztonságának megőrzéséhez.
Példák népszerű EC implementációkra: Ceph, GlusterFS, HDFS
Számos elosztott tárolórendszer alkalmazza az Erasure Coding-ot (EC) az adatvédelem javítására. Nézzünk meg néhány népszerű implementációt!
A Ceph, egy szoftveresen definiált tárolórendszer, széles körben használja az EC-t az objektumtároló (RADOS) rétegben. A Ceph lehetővé teszi a felhasználók számára, hogy testre szabják az EC kódolási paramétereit, mint például az adat- és paritáscsíkok számát, optimalizálva a tárolási hatékonyságot és a hibatűrést. A Ceph EC implementációja jelentősen csökkentheti a tárolási költségeket a replikációhoz képest, különösen nagy méretű adathalmazok esetén.
A GlusterFS, egy elosztott fájlrendszer, szintén támogatja az EC-t. A GlusterFS EC implementációja lehetővé teszi a felhasználók számára, hogy konfigurálják az EC-t kötet szinten. A GlusterFS az EC-t használva biztosítja az adatok integritását és elérhetőségét, még akkor is, ha a tárolókiszolgálók meghibásodnak. A GlusterFS EC támogatása különösen előnyös a nagy teljesítményű számítási (HPC) környezetekben és más olyan alkalmazásokban, ahol a megbízhatóság kritikus fontosságú.
Az Erasure Coding a Ceph és a GlusterFS rendszerekben lehetővé teszi a magasabb adattűrőképességet alacsonyabb tárolási költségek mellett, mint a hagyományos replikációs módszerek.
A Hadoop Distributed File System (HDFS), a Hadoop ökoszisztéma alapvető eleme, szintén rendelkezik EC implementációval. Az HDFS EC célja, hogy javítsa a tárolási hatékonyságot a háromszoros replikációhoz képest, ami az HDFS alapértelmezett adatvédelmi mechanizmusa volt korábban. Az HDFS EC implementációja különféle kódolási sémákat támogat, és integrálható a meglévő HDFS ökoszisztémával. Az HDFS EC használatával a szervezetek jelentős mennyiségű tárolókapacitást takaríthatnak meg, miközben megőrzik az adatok megbízhatóságát és elérhetőségét.
Ezek az implementációk különböző kódolási sémákat és konfigurációs lehetőségeket kínálnak, lehetővé téve a felhasználók számára, hogy a rendszerüket az egyedi igényeikhez igazítsák. A kódolási séma megválasztása befolyásolja a szükséges redundanciát és a helyreállítási teljesítményt. A Reed-Solomon kódolás egy gyakran használt módszer, melynek segítségével a rendszerek képesek megbirkózni a meghibásodásokkal anélkül, hogy az adatokhoz való hozzáférés leállna.
A jövőbeli trendek az Erasure Coding területén
Az Erasure Coding jövője a mesterséges intelligencia integrációjával még hatékonyabb adathelyreállítást ígér elosztott rendszerekben.
Az Erasure Coding (EC) terén a jövőbeli trendek a teljesítmény növelésére és a komplexitás csökkentésére irányulnak. A gyorsabb kódolási és dekódolási algoritmusok fejlesztése kiemelt fontosságú, különösen a nagy adatmennyiségek kezelésekor. Az új hardveres gyorsítási technikák, mint például a GPU-k és FPGA-k használata, lehetővé teszik az EC műveletek jelentős felgyorsítását.
Egyre nagyobb hangsúlyt fektetnek az EC integrációjára a szoftveresen definiált tárolási (SDS) megoldásokba. Ez lehetővé teszi a rugalmasabb és költséghatékonyabb adatvédelmet a különböző tárolási környezetekben.
A gépi tanulás (ML) alkalmazása az EC paramétereinek optimalizálására egy feltörekvő terület. Az ML modellek képesek dinamikusan beállítani a redundancia szintjét a tárolt adatok jellemzői és a rendszer terhelése alapján, ezáltal maximalizálva a teljesítményt és minimalizálva a költségeket.
A titkosítás és az EC kombinációja is egyre népszerűbb, mivel ez a megközelítés erősebb adatvédelmet biztosít a jogosulatlan hozzáférés és az adatszivárgás ellen. A kvantum-rezisztens EC algoritmusok fejlesztése is elengedhetetlen a jövőbeni adatbiztonság szempontjából.