

Az adatok ereje napjainkban vitathatatlan. Minden vállalat, legyen az kicsi vagy nagy, hatalmas mennyiségű információt termel és tárol. Ezen adatok puszta tárolása azonban önmagában nem elegendő; a valódi érték az adatok elemzéséből és az azokból levont következtetésekből fakad. Az üzleti intelligencia (BI) és az adatvezérelt döntéshozatal korában kritikus fontosságú, hogy az adatok ne csupán rendelkezésre álljanak, hanem könnyen hozzáférhetőek, érthetőek és elemezhetőek is legyenek. Ebben a kontextusban kap kiemelt szerepet az adatbázis-struktúrák megfelelő megtervezése, különösen az analitikus célokra optimalizált rendszerek esetében. Az egyik legelterjedtebb és leghatékonyabb ilyen struktúra a csillagséma (star schema), amely az adatraktározás (data warehousing) alapköveként szolgál.
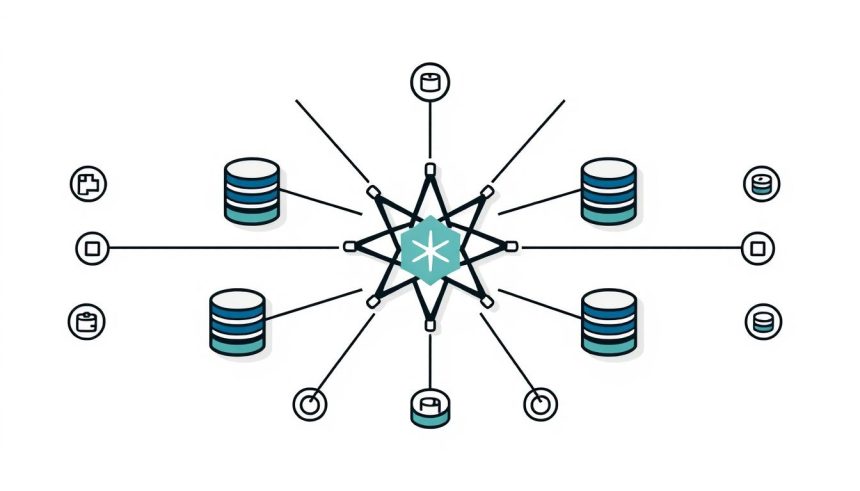
A csillagséma egy dimenzionális modellezési technika, amelyet kifejezetten az üzleti intelligencia és az adatelemzés igényeinek kielégítésére fejlesztettek ki. Nevét a vizuális megjelenéséről kapta: egy központi ténytábla (fact table) található a középpontban, amelyet sugárszerűen vesznek körül a dimenziótáblák (dimension tables), mint egy csillag ágai. Ez az egyszerű, mégis rendkívül erőteljes struktúra optimalizálja a lekérdezési teljesítményt, egyszerűsíti az adatok értelmezését és nagymértékben hozzájárul az üzleti elemzések hatékonyságához.
Mielőtt mélyebbre merülnénk a csillagséma részleteiben, fontos megérteni, miben tér el a hagyományos, tranzakciós adatbázis-struktúráktól, mint amilyen a harmadik normálforma (3NF) szerinti elrendezés. Az OLTP (Online Transaction Processing) rendszerek, amelyek a napi működési tranzakciókat kezelik (pl. egy online vásárlás rögzítése, bankszámla egyenleg frissítése), a redundancia minimalizálására és az adatintegritás maximalizálására törekednek. Ez gyakran sok, apró, normalizált táblát eredményez, amelyek komplex lekérdezéseket igényelnek több tábla összekapcsolásával (joinozással). Ezzel szemben az OLAP (Online Analytical Processing) rendszerek, amelyek az adatelemzést támogatják, a lekérdezési sebességet és az érthetőséget helyezik előtérbe, még akkor is, ha ez némi adatredundanciával jár.
A csillagséma felépítése: ténytáblák és dimenziótáblák
A csillagséma két alapvető típusú táblából áll: a ténytáblákból és a dimenziótáblákból. Ezek együtt alkotják a struktúra gerincét, lehetővé téve az üzleti folyamatok mennyiségi elemzését különböző szempontok szerint.
A ténytáblák: a „mit” és a „mennyit”
A ténytábla a csillagséma középpontjában helyezkedik el, és az üzleti folyamatokban bekövetkező események vagy tranzakciók kvantitatív adatait tárolja. Ezek az adatok általában numerikusak és mérhetőek, például eladások összege, darabszám, kattintások száma, hőmérséklet, költségek, vagy profit. A ténytáblák jellemzően nagyon nagyok, mivel minden egyes üzleti eseményt rögzítenek, gyakran több milliárd sort is tartalmazhatnak.
A ténytáblák két fő típusú oszlopot tartalmaznak:
- Idegen kulcsok (Foreign Keys): Ezek az oszlopok a dimenziótáblák elsődleges kulcsaira (primary keys) hivatkoznak. Ezek a kulcsok teremtik meg a kapcsolatot a tények és a dimenziók között, lehetővé téve az adatok dimenziók szerinti szeletelését és fúrását (slicing and dicing). Például egy eladási ténytábla tartalmazhatja a dátum dimenzió kulcsát, a termék dimenzió kulcsát, az ügyfél dimenzió kulcsát és a bolt dimenzió kulcsát.
- Mérések (Measures): Ezek a numerikus értékek, amelyek a vizsgált üzleti eseményt írják le. A mérések lehetnek aggregálhatók (pl. összeg, átlag, minimum, maximum), vagy nem aggregálhatók. A mérések aggregálhatóságuk szerint tovább oszthatók:
- Additív mérések: Ezek azok a mérések, amelyek minden dimenzió mentén összegezhetők (pl. eladási érték, mennyiség).
- Szemladditív mérések: Ezek csak bizonyos dimenziók mentén összegezhetők, mások mentén nem (pl. bankszámla egyenleg – időben nem összegezhető, de ügyfél és valuta szerint igen).
- Nem additív mérések: Ezek semmilyen dimenzió mentén nem összegezhetők (pl. átlagos egységár, nyereséghányad). Ezeket gyakran más, additív mérésekből számítják ki a lekérdezés során.
A ténytáblák granularitása kulcsfontosságú. Ez azt jelenti, hogy a ténytábla egy sora milyen szintű részletességgel rögzíti az eseményt. Például egy eladási ténytábla granularitása lehet „egy sor minden egyes eladott termékre egy tranzakción belül”, vagy „egy sor minden egyes tranzakcióra”. A granularitás meghatározza, milyen részletességű elemzéseket lehet végezni, és közvetlenül befolyásolja a tábla méretét is. Általánosságban elmondható, hogy a ténytáblákat a lehető legfinomabb granularitással érdemes megtervezni, mivel a részletesebb adatokból mindig aggregálhatók a magasabb szintű összesítések, de fordítva ez nem lehetséges.
A ténytáblák a „mi történt” és a „mennyi” kérdésekre adnak választ, rögzítve az üzleti események kvantitatív aspektusait.
A dimenziótáblák: a „ki”, „hol”, „mikor”, „mivel” és „hogyan”
A dimenziótáblák a ténytáblák körül helyezkednek el, és az üzleti események kontextuális adatait, attribútumait tartalmazzák. Ezek a táblák írják le azokat a „dimenziókat”, amelyek mentén a tényeket elemezni lehet. Például egy eladási eseményt elemezhetünk dátum (mikor), termék (mivel), ügyfél (ki), és bolt (hol) dimenziók szerint.
Minden dimenziótábla tartalmaz egy egyedi azonosítót, az úgynevezett helyettesítő kulcsot (surrogate key), amely a tábla elsődleges kulcsa. Ez egy mesterségesen generált numerikus azonosító, amelynek nincs üzleti jelentése, de hatékonyan és egyedileg azonosítja a dimenzió minden egyes sorát. A helyettesítő kulcsok használata több előnnyel jár: függetlenséget biztosítanak a forrásrendszer kulcsaitól, kezelik a lassan változó dimenziók problémáját, és jobb teljesítményt nyújtanak a join műveletek során, mint a hosszú, szöveges üzleti kulcsok.
A dimenziótáblák számos leíró attribútumot tartalmaznak, amelyek az adott dimenzió különböző jellemzőit írják le. Például egy „Idő” dimenziótábla tartalmazhatja a nap, hét, hónap, negyedév, év, hét napja, ünnepnap-e attribútumokat. Egy „Termék” dimenziótábla tartalmazhatja a termék nevét, kategóriáját, alkategóriáját, márkáját, színét, méretét stb.
A dimenziótáblák gyakran tartalmaznak hierarchiákat. Például egy földrajzi dimenzióban lehet egy hierarchia: Ország -> Megye/Állam -> Város -> Utca. Ezek a hierarchiák lehetővé teszik a felhasználók számára, hogy az adatokban „lefúrjanak” (drill down) a magasabb aggregációs szintekről a részletesebb szintekre, vagy „felfúrjanak” (drill up) a részletes adatokból az összesített nézetekre. Ez a képesség alapvető az OLAP elemzésekben.
Néhány gyakori dimenziótábla típus:
- Idő dimenzió: Szinte minden adatraktárban elengedhetetlen. Tartalmazza a dátumot, évet, hónapot, napot, napszakot, negyedévet, stb.
- Termék dimenzió: Leírja az eladott termékeket: termék neve, kódja, kategóriája, márkája, színe, mérete.
- Ügyfél dimenzió: Részletezi az ügyfeleket: név, cím, demográfiai adatok, ügyfél típusa.
- Helyszín/Bolt dimenzió: Információk az értékesítési pontokról: bolt neve, címe, régiója, bolt típusa.
- Munkatárs/Sales Rep dimenzió: Leírja az értékesítőket vagy munkatársakat: név, azonosító, részleg, pozíció.
Lassan változó dimenziók (SCD – Slowly Changing Dimensions)
A dimenziótáblák egyik legnagyobb kihívása az adatok változásának kezelése az idő múlásával. Például egy ügyfél címe megváltozhat, vagy egy termék kategóriája átsorolásra kerülhet. Ha egyszerűen frissítenénk az adatot a dimenziótáblában, elveszítenénk a történelmi adatokat, ami hibás elemzésekhez vezetne. Az SCD-k különböző stratégiákat kínálnak ezen problémák kezelésére.
SCD Type 0: Retain Original
Ez a legegyszerűbb megközelítés: a dimenzió attribútumai soha nem változnak. Ha egy attribútum megváltozik a forrásrendszerben, az adatraktárban lévő érték változatlan marad. Ez akkor megfelelő, ha a történelmi adatok nyomon követése nem kritikus, vagy ha az attribútum valóban statikusnak tekinthető.
SCD Type 1: Overwrite
Ebben az esetben, ha egy attribútum megváltozik, a régi értéket egyszerűen felülírják az új értékkel. Ez azt jelenti, hogy a dimenzióban mindig az aktuális érték található meg. A hátránya, hogy a történelmi elemzések során a korábbi tények is az új attribútumhoz lesznek rendelve, ami torzíthatja az eredményeket. Például, ha egy ügyfél címe megváltozik, és felülírjuk, akkor az összes korábbi vásárlása is az új címhez fog tartozni.
SCD Type 2: Add New Row
Ez a leggyakrabban használt és legrugalmasabb SCD típus. Amikor egy dimenzió attribútuma megváltozik, egy új sort adnak hozzá a dimenziótáblához az új értékkel. Az eredeti sor változatlan marad, de lezárják (pl. egy „érvényes-től” és „érvényes-ig” dátumoszloppal, vagy egy „aktív” flaggel), jelezve, hogy már nem ez az aktuális állapot. Az új sor pedig az új értékkel és egy új, aktív időszak kezdő dátummal kerül be. Ez a megközelítés teljes történelmi nyomon követést biztosít, de növeli a dimenziótábla méretét.
Például egy ügyfél táblában:
| Ügyfél_SK | Ügyfél_NK | Név | Cím | Érvényes_Kezdet | Érvényes_Vég | Aktív |
|---|---|---|---|---|---|---|
| 101 | ABC001 | Kiss Péter | Budapest, Fő u. 1. | 2020-01-01 | 2022-12-31 | Nem |
| 102 | ABC001 | Kiss Péter | Budapest, Új u. 5. | 2023-01-01 | 9999-12-31 | Igen |
Amikor az ügyfél címe 2023-01-01-én megváltozott, az eredeti sor érvényességi dátumát lezártuk, és egy új sort hoztunk létre az új címmel és egy új érvényességi időszakkal.
SCD Type 3: Add New Column
Ez a típus egy korábbi attribútum értékét egy új oszlopban tárolja, míg az aktuális értéket az eredeti oszlopban tartja. Ez csak egyetlen korábbi érték nyomon követését teszi lehetővé, és nem skálázódik jól, ha több változást kell kezelni. Ritkábban használják, inkább olyan esetekben, ahol csak a „jelenlegi” és az „előző” állapotra van szükség.
SCD Type 4: Add History Table
Ez a megközelítés az aktuális dimenzió attribútumokat az eredeti dimenziótáblában tartja (SCD Type 1-ként viselkedve), de egy külön történeti táblát is fenntart a változások nyomon követésére. A ténytábla az aktuális dimenziótáblára mutat. Ez bonyolultabbá teszi a történelmi lekérdezéseket, mivel két táblát kell joinolni, de tisztán tartja az aktuális dimenziót.
SCD Type 6: Hybrid (SCD Type 1 + 2 + 3)
Ezt a típust gyakran „hibrid” SCD-nek is nevezik, mivel az 1-es, 2-es és 3-as típusok elemeit kombinálja. Tartalmazza az aktuális értéket (Type 1), a történelmi sorokat (Type 2), és gyakran egy „aktuális korábbi” oszlopot (Type 3). Ez a típus rendkívül rugalmas, de bonyolultabb az implementációja és karbantartása.
A csillagséma előnyei
A csillagséma népszerűsége nem véletlen; számos jelentős előnnyel jár az adatraktározás és az üzleti intelligencia terén.
Optimalizált lekérdezési teljesítmény
Ez az egyik legfontosabb előny. A csillagséma struktúrája kevesebb táblát és egyszerűbb joinokat igényel a lekérdezések futtatásához, mint a normalizált OLTP sémák. A ténytábla és a dimenziótáblák közötti közvetlen kapcsolat azt jelenti, hogy a legtöbb elemző lekérdezéshez csak a ténytáblát és néhány dimenziótáblát kell joinolni. Ez drámaian csökkenti a lekérdezési időt, különösen nagy adatmennyiségek esetén. A dimenziótáblák gyakran de-normalizáltak, ami azt jelenti, hogy egy dimenzió összes attribútuma egyetlen táblában található, elkerülve a további joinokat a dimenzión belül.
Egyszerűség és érthetőség
A csillagséma intuitív és könnyen érthető a nem technikai felhasználók számára is. A dimenziók az üzleti fogalmakhoz igazodnak (pl. idő, termék, ügyfél), és a tények egyértelműen azonosíthatók, mint a mérések. Ez megkönnyíti az üzleti felhasználók számára az adatok felfedezését és a lekérdezések megfogalmazását, akár BI eszközök segítségével is. A séma vizuálisan is egyértelmű, ami gyorsabb adaptációt tesz lehetővé.
Skálázhatóság
A csillagsémák kiválóan skálázhatók. Új dimenziók vagy attribútumok hozzáadása viszonylag egyszerűen megoldható, anélkül, hogy a teljes sémát jelentősen meg kellene változtatni. A ténytábla méretének növekedése sem okoz aránytalanul nagy teljesítményromlást, mivel a dimenziók száma általában stabil marad. Ez különösen fontos a növekvő adatmennyiségű környezetekben.
BI eszközök kompatibilitása
A legtöbb modern üzleti intelligencia és adatelemző eszköz (pl. Power BI, Tableau, QlikView, Looker) natívan támogatja és optimalizálva van a csillagsémák kezelésére. Ezek az eszközök gyakran képesek automatikusan felismerni a tény- és dimenziótáblákat, és vizuális felületeket biztosítani a drag-and-drop típusú lekérdezésekhez. Ez jelentősen felgyorsítja az adatelemzési folyamatot és csökkenti a technikai tudás iránti igényt.
Adataggregáció és összesítés
A csillagséma ideális az előzetes aggregációk és összesítések létrehozására. Mivel a tények és dimenziók szétválasztottak, könnyen létrehozhatók aggregált ténytáblák (summary tables vagy aggregate tables), amelyek előre kiszámított összesítéseket tartalmaznak magasabb granularitási szinten. Ez tovább gyorsítja a lekérdezéseket, különösen a gyakran ismétlődő, nagy volumenű jelentések esetében.
A csillagséma hátrányai és kihívásai
Bár a csillagséma számos előnnyel jár, fontos tudatában lenni a potenciális hátrányainak és a vele járó kihívásoknak is.
Adatredundancia
A dimenziótáblák de-normalizálása, bár javítja a lekérdezési teljesítményt, adatredundanciát eredményezhet. Például egy „Termék” dimenziótábla tartalmazhatja a termék kategóriáját, alkategóriáját és márkáját egyetlen sorban, még akkor is, ha ezek az adatok máshol is létezhetnek. Ez növeli a tárolási igényt és potenciálisan adatintegritási problémákhoz vezethet, ha a változásokat nem kezelik megfelelően (pl. SCD Type 1 esetén).
ETL (Extract, Transform, Load) komplexitás
Az adatok betöltése a forrásrendszerekből a csillagsémába bonyolult ETL folyamatokat igényel. A dimenziók helyettesítő kulcsainak generálása, az SCD-k kezelése és a ténytáblák granularitásának biztosítása komplex logikát követel meg. Különösen az SCD Type 2 implementációja jelent jelentős fejlesztési és karbantartási terhet.
Rugalmatlanság komplex adatelemzési igények esetén
Bár a csillagséma kiválóan alkalmas a legtöbb elemzési feladatra, bizonyos összetett forgatókönyvek esetén korlátokba ütközhet. Például, ha egy dimenzió túl sok attribútumot tartalmaz, vagy ha a dimenziók közötti kapcsolatok bonyolultabbak, mint egy egyszerű egy-a-tömbhöz (one-to-many) kapcsolat, a csillagséma kevésbé hatékony lehet. Ilyen esetekben a hópehely séma (snowflake schema) vagy más modellezési megközelítések lehetnek előnyösebbek.
Adatintegritási kihívások
A de-normalizáció és az SCD-k kezelése miatt nagyobb figyelmet kell fordítani az adatintegritásra. A forrásrendszerben bekövetkező változások pontos és időben történő lekövetése elengedhetetlen a konzisztens és megbízható adatok biztosításához. A hibás vagy hiányzó adatok a dimenziótáblákban vagy ténytáblákban súlyosan befolyásolhatják az elemzések pontosságát.
Csillagséma vs. hópehely séma: részletes összehasonlítás
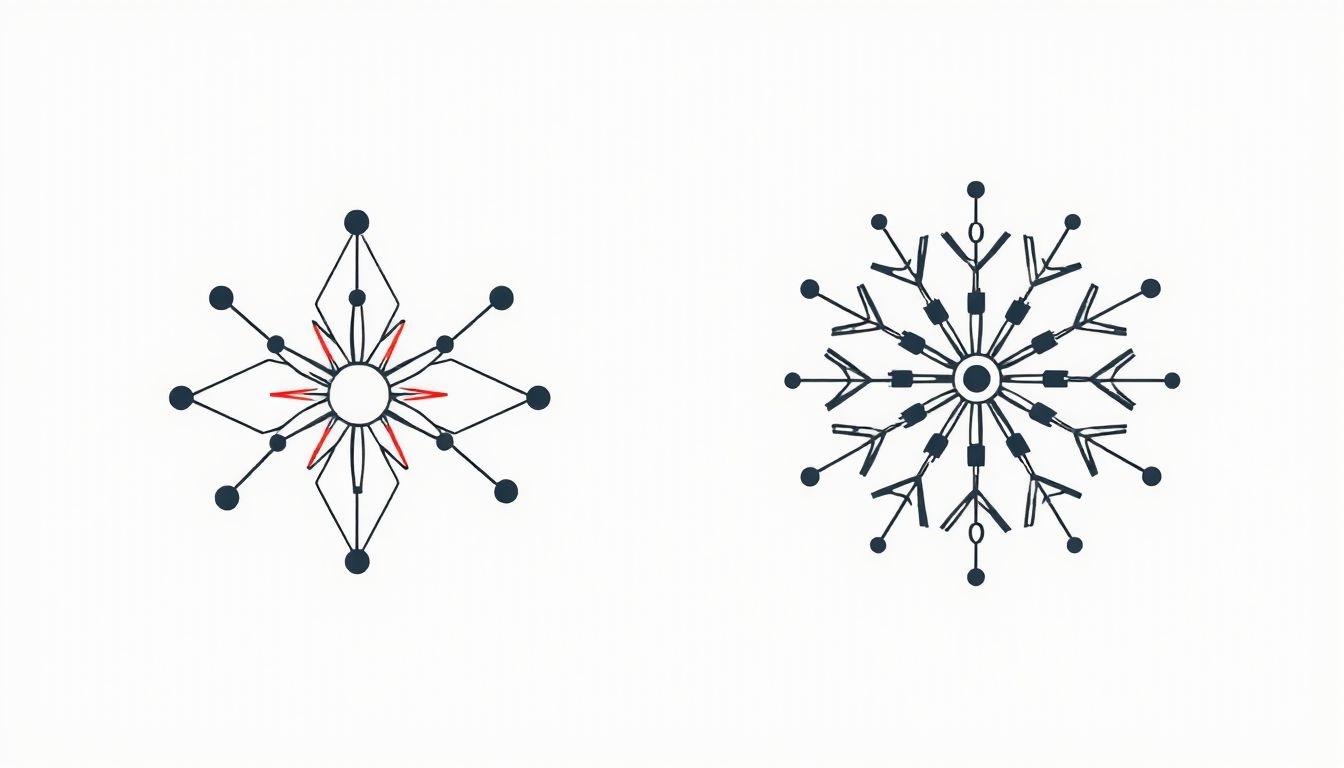
A csillagséma és a hópehely séma a két leggyakoribb dimenzionális modellezési megközelítés az adatraktározásban. Bár mindkettő a ténytábla és dimenziótáblák koncepciójára épül, kulcsfontosságú különbségek vannak a dimenziótáblák normalizálásának szintjében.
Hópehely séma (Snowflake Schema)
A hópehely séma a dimenziótáblákat tovább normalizálja. Ez azt jelenti, hogy a dimenziótáblákból is további al-dimenziótáblákat hoznak létre, ha egy dimenzió attribútumai logikailag további entitásokra bonthatók. Például egy „Termék” dimenziótáblát felbonthatunk egy „Termék Kategória” és egy „Termék Márka” al-dimenziótáblára. Ez a struktúra vizuálisan egy hópehelyre emlékeztet, ahol a ténytábla a középpont, a fő dimenziók az első szintű ágak, és a normalizált al-dimenziók a további elágazások.
Példa hópehely sémára:
Kezdeti Termék dimenzió (csillagséma):
| Termék_SK | Termék_NK | Termék_Név | Kategória_Név | Márka_Név |
|---|---|---|---|---|
| 1 | P001 | Laptop X | Elektronika | TechBrand |
| 2 | P002 | Egér Y | Periféria | TechBrand |
Hópehely séma szerint normalizált Termék dimenzió:
Ténytábla -> Termék_SK -> Termék dimenzió
Termék dimenzió:
| Termék_SK | Termék_NK | Termék_Név | Kategória_SK | Márka_SK |
|---|---|---|---|---|
| 1 | P001 | Laptop X | 10 | 20 |
| 2 | P002 | Egér Y | 11 | 20 |
Kategória dimenzió:
| Kategória_SK | Kategória_Név |
|---|---|
| 10 | Elektronika |
| 11 | Periféria |
Márka dimenzió:
| Márka_SK | Márka_Név |
|---|---|
| 20 | TechBrand |
Összehasonlítás
Előnyök a hópehely séma mellett:
- Kevesebb adatredundancia: Mivel a dimenziókat tovább normalizálják, kevesebb ismétlődő adatot tárolnak, ami csökkenti a tárolási igényt és javítja az adatintegritást.
- Könnyebb karbantartás: A dimenziókban bekövetkező változások kevesebb helyen igényelnek frissítést, ami egyszerűsítheti a karbantartást.
Hátrányok a hópehely séma ellenében:
- Komplexebb lekérdezések: A lekérdezésekhez több tábla összekapcsolására (joinolására) van szükség, ami lassabb lekérdezési teljesítményt eredményezhet, különösen nagy adatmennyiségek esetén.
- Nehezebb érthetőség: A normalizált dimenziók bonyolultabbá teszik a sémát a végfelhasználók és a BI eszközök számára.
- Nagyobb ETL komplexitás: Az adatok betöltése során több táblát kell feltölteni és a kulcsokat megfelelően kezelni.
Mikor melyiket használjuk?
- Csillagséma: A legtöbb adatraktározási és BI forgatókönyv esetében a csillagséma az ajánlott választás. Kiválóan alkalmas, ha a lekérdezési teljesítmény kritikus, az adatok mennyisége nagy, és az elemzéseket üzleti felhasználók is végzik. Az egyszerűség és a BI eszközökkel való kompatibilitás miatt ez a preferált modell.
- Hópehely séma: Akkor lehet releváns, ha az adatredundancia minimalizálása abszolút prioritás (pl. nagyon korlátozott tárhely), vagy ha a dimenziók rendkívül komplexek és sok ismétlődő attribútumot tartalmaznak. Ritkábban használják tisztán, de hibrid megközelítésként (ahol egyes dimenziók normalizáltak, mások nem) előfordulhat.
A csillagséma az egyszerűségre és a lekérdezési sebességre fókuszál, míg a hópehely séma a normalizációra és a redundancia minimalizálására.
Csillagséma tervezése: lépésről lépésre
A hatékony csillagséma megtervezése alapos tervezést és az üzleti igények mélyreható megértését igényli. A folyamat általában a következő lépésekből áll:
1. Üzleti igények és folyamatok megértése
Ez a legelső és legfontosabb lépés. Beszélgetni kell az üzleti felhasználókkal, megérteni, milyen kérdésekre keresnek választ, milyen elemzéseket szeretnének végezni, és milyen üzleti folyamatokat akarnak mérni. Mi az, ami pénzt termel? Mi az, ami költséget okoz? Milyen teljesítménymutatók (KPI-k) fontosak? Ez határozza meg a tényeket és a dimenziókat.
2. Az üzleti folyamat azonosítása
Válasszon ki egy konkrét üzleti folyamatot, amelyet modellezni szeretne (pl. értékesítés, rendelésfeldolgozás, weboldal látogatások, gyártás). Minden csillagséma egyetlen üzleti folyamatra fókuszál. Egy nagy adatraktár több csillagsémát is tartalmazhat, amelyek egymáshoz kapcsolódhatnak konform dimenziók (conformed dimensions) segítségével.
3. A tények (mérések) meghatározása
Mi az, amit mérni akarunk az üzleti folyamatban? Ezek lesznek a ténytábla numerikus oszlopai. Például az értékesítési folyamatban a mérések lehetnek az eladott mennyiség, az eladási ár, a kedvezmény mértéke, vagy a profit. Fontos, hogy ezek a mérések legyenek kvantitatívak és relevánsak az üzleti kérdések szempontjából.
4. A ténytábla granularitásának meghatározása
Milyen szintű részletességre van szükség? Ez a döntés alapvető, mivel a granularitás határozza meg a ténytábla egy sorának jelentését. Például egy értékesítési ténytábla granularitása lehet „minden egyes eladott termékvonal a tranzakción belül” (legfinomabb), vagy „minden egyes tranzakció” (összesített), vagy akár „napi összes eladás egy adott üzletben”. Általában a legfinomabb granularitás ajánlott, hogy a jövőbeni, előre nem látható elemzéseket is támogassa.
5. A dimenziók azonosítása
Mi az a kontextus, amiben a tényeket elemezni szeretnénk? Ezek lesznek a dimenziók. Például egy értékesítési tényhez kapcsolódhat a dátum, az ügyfél, a termék, a bolt, az értékesítő, vagy a fizetési mód dimenzió. Minden dimenziónak egyedi üzleti entitást kell képviselnie.
6. A dimenziótáblák attribútumainak meghatározása
Milyen leíró jellemzők tartoznak az egyes dimenziókhoz? Például az „Ügyfél” dimenzióhoz tartozhat a név, cím, születési dátum, nem, hűségprogram státusz. Az „Idő” dimenzióhoz tartozhat az év, negyedév, hónap, nap, hét napja, ünnepnap-e. Fontos, hogy az attribútumok relevánsak legyenek az elemzések szempontjából, és ne tartalmazzanak tranzakciós adatokat.
7. Helyettesítő kulcsok generálása
Minden dimenziótáblához hozzon létre egy egyedi, mesterséges helyettesítő kulcsot (integer típusú autoincrement érték a legtöbb esetben). Ez lesz a dimenziótábla elsődleges kulcsa, és a ténytábla idegen kulcsa, amely a dimenzióra hivatkozik.
8. Lassan változó dimenziók (SCD) stratégia kiválasztása
Döntse el, hogyan kezeli az idővel változó dimenzióattribútumokat. A leggyakoribb és legrugalmasabb az SCD Type 2, de az üzleti igényektől függően más típusok is szóba jöhetnek.
9. Séma vizualizálása és dokumentálása
Rajzolja le a sémát, ábrázolva a ténytáblát a középpontban és a dimenziótáblákat körülötte. Jelölje a kulcsokat és a kapcsolatokat. Dokumentálja minden tábla és oszlop célját, definícióját, és a használt SCD típusokat. Ez a dokumentáció elengedhetetlen a séma megértéséhez és karbantartásához.
10. ETL folyamat tervezése
Tervezze meg, hogyan kerülnek az adatok a forrásrendszerekből a csillagsémába. Ez magában foglalja az adatok kinyerését, tisztítását, átalakítását és betöltését. Az ETL folyamatnak kezelnie kell a helyettesítő kulcsok generálását, az SCD-k frissítését és a ténytáblák feltöltését a megfelelő granularitással.
Fejlett csillagséma koncepciók
A fentebb tárgyalt alapvető elemeken túl számos fejlett koncepció létezik, amelyek tovább finomíthatják és optimalizálhatják a csillagsémákat a komplexebb üzleti igények kielégítésére.
Konform dimenziók (Conformed Dimensions)
Egy nagyvállalati adatraktár gyakran több ténytáblát és több csillagsémát tartalmaz, amelyek különböző üzleti folyamatokat modelleznek (pl. értékesítés, marketing, logisztika). A konform dimenziók olyan dimenziótáblák, amelyeket több ténytábla is használ, és amelyek konzisztens módon vannak definiálva és karbantartva az összes sémában. Például egy „Idő” dimenzió, egy „Termék” dimenzió vagy egy „Ügyfél” dimenzió lehet konform. Ennek előnye, hogy lehetővé teszi a különböző üzleti területek adatainak egységes elemzését és összehasonlítását, mivel ugyanazt a dimenziót használják. Ez elengedhetetlen a „single source of truth” (egyetlen igazságforrás) elvének megvalósításához az adatraktárban.
Degenerált dimenziók (Degenerate Dimensions)
A degenerált dimenziók olyan attribútumok, amelyek a ténytáblában tárolódnak, de valójában dimenziószerű adatokat képviselnek, amelyek nem kapcsolódnak önálló dimenziótáblához. Gyakran tranzakciós azonosítók (pl. rendelésazonosító, számlaszám) vagy egyéb egyedi azonosítók, amelyeknek nincs sok leíró attribútuma, de hasznosak lehetnek a lekérdezések szeleteléséhez. Mivel nincs szükségük külön dimenziótáblára, közvetlenül a ténytáblában tárolódnak, mint egyedi értékek.
Junk dimenziók (Junk Dimensions)
A junk dimenziók olyan dimenziótáblák, amelyek egy ténytáblához kapcsolódó, alacsony kardinalitású és/vagy egymással nem összefüggő flag-eket (jelzőket) és attribútumokat csoportosítanak. Például egy tranzakcióhoz tartozhat „visszaküldött-e” (igen/nem), „online rendelés-e” (igen/nem), „szállított-e” (igen/nem) flag. Ahelyett, hogy minden ilyen flagnek külön dimenziót hoznánk létre, vagy közvetlenül a ténytáblában tárolnánk, egy junk dimenzióban kombináljuk őket. Ez csökkenti a ténytábla oszlopainak számát és a dimenziótáblák szétaprózódását.
Szerepjátszó dimenziók (Role-Playing Dimensions)
Egy dimenziótábla több szerepet is betölthet egyetlen ténytáblában. Például egy „Dátum” dimenzió lehet a „Rendelés Dátuma”, a „Szállítás Dátuma” és a „Fizetés Dátuma” is egy rendelési ténytáblában. Ahelyett, hogy három különálló dátum dimenziót hoznánk létre, ugyanazt a „Dátum” dimenziót használjuk, de különböző idegen kulcsnevekkel a ténytáblában. Ez megkönnyíti a karbantartást és konzisztenciát biztosít.
Híd táblák (Bridge Tables)
Bizonyos esetekben egy tény és egy dimenzió között sok-a-sokhoz (many-to-many) kapcsolat áll fenn. Például egy betegnek több diagnózisa is lehet, és egy diagnózis több beteghez is kapcsolódhat. Egy ilyen kapcsolatot nem lehet közvetlenül kezelni a csillagsémában. Ilyenkor egy híd táblát használnak, amely a ténytábla és a dimenziótábla közé ékelődik. A híd tábla két oszlopot tartalmaz: az egyik a ténytábla kulcsára, a másik a dimenziótábla kulcsára hivatkozik, és minden kapcsolódó párosra egy sort tartalmaz. Ez a megoldás lehetővé teszi a sok-a-sokhoz kapcsolatok modellezését a dimenzionális modell keretein belül.
Ténytelen ténytáblák (Factless Fact Tables)
Néha szükség van egy ténytáblára, amely nem tartalmaz numerikus méréseket, hanem egyszerűen csak a dimenziók közötti események vagy kapcsolatok előfordulását rögzíti. Például egy „Részvétel” ténytelen ténytábla rögzítheti, hogy melyik diák melyik kurzuson vett részt, anélkül, hogy bármilyen mennyiségi adatot (pl. jegy, óraszám) tárolna. Ezek a táblák hasznosak lehetnek a jelenlét, lefedettség vagy események nyomon követésére, amelyeknek nincs közvetlen mérhető értéke.
A csillagséma alkalmazása különböző iparágakban
A csillagséma rendkívül sokoldalú, és széles körben alkalmazzák a legkülönfélébb iparágakban az üzleti intelligencia és adatelemzés céljára.
Kereskedelem és kiskereskedelem
Az egyik leggyakoribb alkalmazási terület. A ténytábla lehet az értékesítés, a dimenziók pedig a termék, az ügyfél, a bolt, a dátum, vagy a promóció. Lehetővé teszi az eladások elemzését termék kategória, régió, időszak, vagy ügyfél szegmens szerint. Segít azonosítani a legkelendőbb termékeket, a legsikeresebb promóciókat, vagy a legjövedelmezőbb ügyfélcsoportokat.
Pénzügy és banki szektor
Pénzügyi tranzakciók, számlamozgások, hitelfelvétel vagy befektetések elemzése. A ténytábla lehet a tranzakció értéke, a dimenziók pedig a számla, az ügyfél, a tranzakció típusa, a dátum, vagy a fiók. Segít a kockázatkezelésben, a csalások felderítésében, a termékportfólió elemzésében és az ügyfélviselkedés megértésében.
Egészségügy
Betegadatok, kezelések, diagnózisok, gyógyszerfelhasználás elemzése. A ténytábla lehet a vizit száma, a kezelés költsége, a gyógyszer adagja, a dimenziók pedig a beteg, az orvos, a kórház, a diagnózis, a gyógyszer, a dátum. Támogatja a betegellátás minőségének javítását, a költségek optimalizálását és a járványügyi elemzéseket.
Telekommunikáció
Hívásadatok, adatforgalom, ügyfélhasználat elemzése. A ténytábla lehet a hívás időtartama, az adatmennyiség, a díj, a dimenziók pedig az ügyfél, a hívott fél, a hívás típusa, a dátum, a bázisállomás. Segít a hálózat optimalizálásában, az ügyfélmegtartásban és az új szolgáltatások bevezetésében.
Webanalitika
Weboldal látogatások, kattintások, konverziók elemzése. A ténytábla lehet a lapletöltések száma, a kattintások száma, a konverziók értéke, a dimenziók pedig a felhasználó, a munkamenet, a weboldal, az eszköz, a földrajzi hely, a forrás (pl. Google, Facebook). Kulcsfontosságú a felhasználói élmény optimalizálásához, a marketing kampányok hatékonyságának méréséhez és az üzleti célok eléréséhez.
Legjobb gyakorlatok a csillagséma használatához
A hatékony és karbantartható csillagséma létrehozásához számos legjobb gyakorlatot érdemes figyelembe venni.
- A granularitás konzisztenciája: Győződjön meg róla, hogy a ténytábla minden sora ugyanazt a granularitási szintet képviseli. Ez elengedhetetlen a pontos aggregációkhoz és elemzésekhez.
- Helyettesítő kulcsok használata: Mindig használjon helyettesítő kulcsokat a dimenziótáblákban. Ezek stabilak, függetlenek a forrásrendszer változásaitól, és jobb teljesítményt biztosítanak.
- Konzisztens elnevezési konvenciók: Használjon világos és konzisztens elnevezési konvenciókat a táblák és oszlopok számára. Ez javítja az érthetőséget és megkönnyíti a karbantartást.
- Dimenziók de-normalizálása: A dimenziótáblákat de-normalizálja, amennyire csak lehetséges, hogy elkerülje a szükségtelen joinokat. Csak akkor normalizáljon tovább (hópehely séma), ha az adatredundancia vagy a karbantartás kritikus tényező.
- Idő dimenzió: Szinte minden adatraktárban elengedhetetlen egy jól megtervezett idő dimenzió. Győződjön meg róla, hogy minden releváns idő attribútumot tartalmaz, mint például év, negyedév, hónap, nap, hét napja, ünnepnap-e, stb.
- Aggregált táblák: Fontolja meg aggregált ténytáblák létrehozását a gyakran kért, magas szintű összesítésekhez. Ezek előre kiszámított értékeket tartalmaznak, és drámaian felgyorsíthatják a jelentéseket.
- Adatminőség: Az ETL folyamat során kiemelt figyelmet kell fordítani az adatminőségre. A rossz minőségű adatok torzítják az elemzéseket és aláássák az adatvezérelt döntéshozatalba vetett bizalmat.
- Indexelés: Optimalizálja a tény- és dimenziótáblákat megfelelő indexekkel a lekérdezési teljesítmény további javítása érdekében. Különösen a ténytábla idegen kulcsai és a dimenziótáblák elsődleges kulcsai legyenek indexelve.
- Dokumentáció: Tartson fenn részletes dokumentációt a sémáról, az üzleti definíciókról, az ETL folyamatokról és az SCD stratégiákról.
A csillagséma az adatraktározás és az üzleti intelligencia világának egyik legfontosabb és leggyakrabban alkalmazott architekturális mintája. Egyszerűsége, rugalmassága és a lekérdezési teljesítményre gyakorolt pozitív hatása miatt továbbra is a választott megoldás marad számos vállalat számára, akik adatvezérelt döntéseket szeretnének hozni. A megfelelő tervezéssel és a legjobb gyakorlatok betartásával a csillagséma robusztus alapot biztosít a mélyreható üzleti elemzésekhez és a stratégiai betekintésekhez, amelyek végül versenyelőnyt biztosítanak a dinamikusan változó piaci környezetben.