

Az adattó (data lake) egy központi adattár, amely lehetővé teszi, hogy strukturált, félig strukturált és strukturálatlan adatokat tároljunk bármilyen formátumban. Ezzel szemben a hagyományos adattárházak (data warehouse) előre definiált sémát követelnek meg.
Az adattó rugalmassága kulcsfontosságú az analitikában. Lehetővé teszi, hogy az adatokat a betöltéskor ne kelljen átalakítani (schema-on-read), hanem csak akkor, amikor az elemzéshez szükség van rájuk. Ez jelentősen lerövidítheti az adatokhoz való hozzáférés idejét és csökkentheti az adatfeldolgozási költségeket.
Az adattavak lehetővé teszik a szervezetek számára, hogy kihasználják az adatokban rejlő potenciált, még akkor is, ha kezdetben nem tudják, hogyan fogják azokat felhasználni.
Az analitikában az adattó szerepe sokrétű: adatbányászathoz, gépi tanuláshoz, üzleti intelligenciához és valós idejű elemzésekhez is használható. A különböző forrásokból származó adatok egyesítése lehetővé teszi a komplex összefüggések feltárását és a pontosabb előrejelzéseket.
Például egy marketing csapat az adattóban tárolhatja a weboldal látogatottsági adatait, a közösségi média bejegyzéseket, a vásárlási tranzakciókat és a CRM rendszerből származó információkat. Ezeket az adatokat elemezve jobban megérthetik a vásárlói viselkedést és optimalizálhatják a marketing kampányokat.
Az adattavak költséghatékonysága is jelentős előny. A felhőalapú tárolási megoldásoknak köszönhetően az adattavak skálázhatók és csak a felhasznált erőforrásokért kell fizetni. Ez különösen vonzóvá teszi őket a kis- és középvállalkozások számára is.
Az adattó definíciója: Több, mint egy egyszerű adattárház
Az adattó (data lake) egy központi adattár, ami hatalmas mennyiségű strukturált, félig strukturált és strukturálatlan adatot tárol natív formátumában. Ezzel ellentétben az adattárházak (data warehouses) elsősorban strukturált adatokat tárolnak, amelyek már átestek egy bizonyos feldolgozási és tisztítási folyamaton (ETL – Extract, Transform, Load). Az adattó lényege, hogy az adatokat mielőtt még tudnánk, hogyan fogjuk őket felhasználni, egy helyen gyűjtjük össze.
Az adattóban az adatok sémája „olvasáskor” (schema-on-read) kerül definiálásra, szemben az adattárházak „íráskor” (schema-on-write) megközelítésével. Ez azt jelenti, hogy az adatokat nem kell előre definiált sémákhoz igazítani, ami rugalmasságot biztosít az adatok feltárásában és elemzésében. Ez különösen hasznos, amikor új adatforrásokat integrálunk, vagy amikor még nem tudjuk pontosan, milyen kérdésekre keressük a választ az adatok segítségével.
Az adattó alkalmas lehet:
- Nyers adatok tárolására, amelyekből később különböző elemzéseket végezhetünk.
- Gépi tanulási modellek betanítására, mivel nagymennyiségű, változatos adatot biztosít.
- Adatfeltárásra (data discovery), azaz új összefüggések és mintázatok keresésére.
- Valós idejű adatok feldolgozására, például IoT eszközökből származó adatok elemzésére.
Az adattó nem csupán egy nagy adattárház. A különbség abban rejlik, hogy az adattó lehetővé teszi az adatok tárolását a legnyersebb formájukban, anélkül, hogy azokat előre definiált sémákhoz kellene igazítani. Ez a rugalmasság teszi lehetővé a gyorsabb kísérletezést és az új meglátások feltárását.
Például, egy webáruház adattója tartalmazhatja a vásárlók tranzakciós adatait (strukturált adat), a weboldal látogatási adatait (félig strukturált adat, pl. log fájlok) és a vásárlók által írt termékértékeléseket (strukturálatlan adat, pl. szöveg). Ezek az adatok együttesen lehetővé teszik a vásárlói viselkedés mélyebb megértését, a termékkínálat optimalizálását és a személyre szabott ajánlatok kidolgozását.
Bár az adattó nagy előnyöket kínál, fontos a megfelelő irányítás (data governance) és biztonság megteremtése. Az adatok minőségének biztosítása, a hozzáférési jogosultságok kezelése és az adatvédelmi szabályok betartása elengedhetetlen a sikeres adattó implementációhoz.
Az adattavak alapelvei és architektúrája
Az adattavak alapelvei a rugalmasságra és a skálázhatóságra épülnek. Egy adattó lényegében egy központi tárolóhely, ahol strukturált, félig strukturált és strukturálatlan adatokat tárolhatunk natív formátumukban. Ez eltér a hagyományos adattárházaktól, ahol az adatokat előre definiált sémákba kell illeszteni, mielőtt betöltenénk őket.
Az adattavak architektúrája többféle komponenst foglal magában. Az adatbefogadás (data ingestion) felelős az adatok különböző forrásokból történő betöltéséért. Ezek a források lehetnek belső rendszerek (CRM, ERP), külső adatbázisok, weboldalak, szenzorok, közösségi média platformok stb. Az adatbefogadás során gyakran alkalmaznak ETL (Extract, Transform, Load) vagy ELT (Extract, Load, Transform) folyamatokat. Az ETL során az adatokat kinyerjük, átalakítjuk és betöltjük az adattóba. Az ELT esetében az adatokat először betöltjük az adattóba, majd ott végezzük el az átalakításokat.
Az adattóban tárolt adatok adatkatalógusba kerülnek, ami egy metaadat-tár. Az adatkatalógus segít az adatok felfedezésében, megértésében és használatában. Tartalmaz információkat az adatok forrásáról, formátumáról, minőségéről és tartalmáról.
Az adatokhoz való hozzáférés különböző módszerekkel történhet. Az adattavak gyakran támogatják a SQL, NoSQL és egyéb lekérdező nyelveket. Az adatok elemzéséhez és vizualizációjához különböző analitikai eszközök használhatók, mint például a Spark, Hadoop, Tableau vagy Power BI.
Az adattavak lehetővé teszik a „schema-on-read” megközelítést, ami azt jelenti, hogy az adatok sémáját csak akkor definiáljuk, amikor olvasunk belőlük. Ez nagyfokú rugalmasságot biztosít, mivel nem kell előre tudnunk, hogyan fogjuk felhasználni az adatokat.
Az adattavak megvalósítása során figyelembe kell venni a biztonsági szempontokat. Az adatokhoz való hozzáférést megfelelően kell szabályozni, és az adatokat titkosítani kell a tárolás és a továbbítás során. A megfelelő adatminőség biztosítása is kritikus fontosságú. Az adattóba betöltött adatoknak tisztának, konzisztensnek és pontosnak kell lenniük.
Az adattavak gyakran felhő alapú platformokon valósulnak meg, mint például az Amazon S3, Azure Data Lake Storage vagy Google Cloud Storage. Ezek a platformok nagyfokú skálázhatóságot, megbízhatóságot és költséghatékonyságot biztosítanak.
Az adattavak előnyei közé tartozik a gyorsabb adatbetöltés, a költséghatékonyság (mivel nem kell előre definiált sémákat használni), a rugalmasság (az adatok bármilyen formátumban tárolhatók), és a skálázhatóság (az adattó könnyen bővíthető a növekvő adatmennyiségek kezelésére).
Az adattavak használatának egyik kihívása az adatkormányzás. Megfelelő irányelveket és eljárásokat kell bevezetni az adatok minőségének, biztonságának és hozzáférhetőségének biztosítása érdekében.
Az adattavak architektúrája általában a következő elemekből áll:
- Adatforrások: Ahol az adatok keletkeznek (pl. adatbázisok, szenzorok, weboldalak).
- Adatbefogadó réteg: Az adatok betöltését végzi az adattóba.
- Tároló réteg: Az adatok tárolására szolgál (pl. Hadoop Distributed File System (HDFS), felhő alapú objektumtárolók).
- Metaadat-katalógus: Az adatok leírását tartalmazza.
- Feldolgozó réteg: Az adatok átalakítását és elemzését végzi (pl. Spark, Hadoop MapReduce).
- Hozzáférési réteg: Lehetővé teszi az adatokhoz való hozzáférést a felhasználók és alkalmazások számára.
Az adattavak jelentősége abban rejlik, hogy egységes képet adnak a vállalati adatokról, lehetővé téve a mélyebb elemzéseket és az üzleti döntések meghozatalát a rendelkezésre álló legfrissebb információk alapján. A jó adattó kialakításához elengedhetetlen a gondos tervezés és a megfelelő technológiák kiválasztása.
Adattó vs. Adattárház: A legfontosabb különbségek
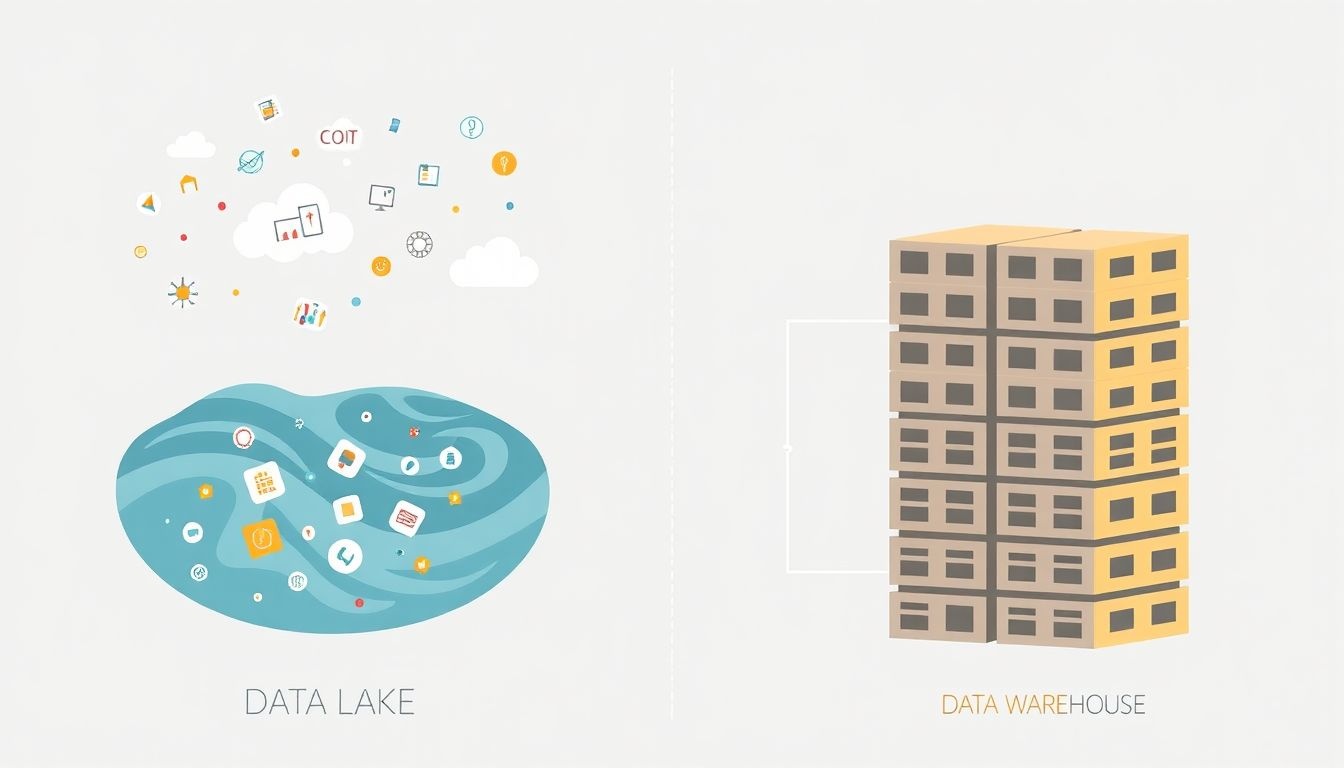
Az adattó és az adattárház két különböző megközelítést képviselnek az adatok tárolására és kezelésére, különösen az analitika területén. Bár mindkettő célja az adatok központosítása, a megvalósításuk és felhasználásuk jelentősen eltér egymástól.
A legfontosabb különbség a tárolt adatok formátumában és a feldolgozás időpontjában rejlik. Az adattárház strukturált, előre meghatározott sémával rendelkező adatokat tárol. Ezzel szemben az adattó nyers, strukturálatlan, félig strukturált és strukturált adatokat egyaránt befogad, eredeti formátumukban.
Az adattárház a „séma olvasáskor” (schema-on-read) elvet követi, míg az adattó a „séma íráskor” (schema-on-write) elvet alkalmazza.
Ez a különbség alapvetően befolyásolja az adatok betöltésének és feldolgozásának folyamatát.
- Adattárház: Az adatok betöltése előtt meg kell határozni a sémát, és az adatokat át kell alakítani (ETL – Extract, Transform, Load) a meghatározott sémának megfelelően. Ez biztosítja az adatok konzisztenciáját és a gyors lekérdezhetőséget, de időigényes és költséges lehet.
- Adattó: Az adatok betöltésekor nem szükséges előre meghatározni a sémát. Az adatok „nyersen” kerülnek betöltésre, és a séma csak akkor kerül alkalmazásra, amikor az adatokra szükség van (ELT – Extract, Load, Transform). Ez gyorsabbá és rugalmasabbá teszi az adatbetöltést, de a lekérdezések bonyolultabbak lehetnek.
Egy másik lényeges különbség a felhasználási területekben mutatkozik meg. Az adattárház elsősorban a BI (Business Intelligence) és a jelentéskészítés támogatására szolgál. A strukturált adatok lehetővé teszik a gyors és egyszerű lekérdezéseket, amelyek alapján üzleti döntéseket lehet hozni.
Az adattó ezzel szemben a fejlett analitika, a gépi tanulás és az adatfeltárás területén nyújt nagyobb értéket. A nyers adatok lehetővé teszik a komplexebb elemzéseket, a rejtett összefüggések feltárását és az új üzleti lehetőségek azonosítását.
Az alábbi táblázat összefoglalja a legfontosabb különbségeket:
| Jellemző | Adattárház | Adattó |
|---|---|---|
| Adatformátum | Strukturált | Strukturált, félig strukturált, strukturálatlan |
| Séma | Előre meghatározott (schema-on-write) | Később alkalmazott (schema-on-read) |
| Adatbetöltés | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
| Felhasználási terület | BI, jelentéskészítés | Fejlett analitika, gépi tanulás, adatfeltárás |
| Skálázhatóság | Korlátozott | Magas |
| Költség | Magasabb | Alacsonyabb (kezdeti költség) |
A skálázhatóság szempontjából az adattavak általában jobban teljesítenek, mivel a felhőalapú tárolási megoldásokkal könnyebben bővíthetők. Az adattárházak skálázása bonyolultabb és költségesebb lehet.
Végül, a költségek tekintetében az adattavak kezdeti költségei általában alacsonyabbak, mivel nem igényelnek előzetes adattranszformációt. Azonban a komplexebb lekérdezések és elemzések fejlesztése magasabb költségeket vonhat maga után.
Mindkét megoldásnak megvannak a maga előnyei és hátrányai, és a választás a konkrét üzleti igényektől és céloktól függ. Sok szervezet hibrid megközelítést alkalmaz, amelyben az adattárház a hagyományos BI-hez, az adattó pedig a fejlett analitikához és a gépi tanuláshoz használatos.
Például, egy kiskereskedelmi cég az adattárházat használhatja a napi eladási adatok elemzésére és a készletgazdálkodásra, míg az adattóban tárolhatja a vásárlói viselkedési adatokat, a közösségi média bejegyzéseket és a weboldal látogatottsági adatokat, hogy mélyebb betekintést nyerjen a vásárlói preferenciákba és személyre szabott marketing kampányokat hozhasson létre.
Az adattavak előnyei és hátrányai a vállalati környezetben
Az adattavak, mint központi adattárolók, jelentős előnyökkel járnak a vállalati környezetben, különösen az analitika szempontjából. Az egyik legfontosabb előnyük a rugalmasság. Mivel az adatokat eredeti formátumukban tárolják, anélkül, hogy előre definiált sémákhoz kellene igazítani őket, a vállalatok képesek gyorsan adaptálódni a változó üzleti igényekhez és új analitikai kérdésekhez. Ez a rugalmasság lehetővé teszi a kísérletezést különböző adatforrásokkal és elemzési módszerekkel, ami innovatív megoldásokhoz vezethet.
Egy másik jelentős előny a költséghatékonyság. Az adattavak gyakran olcsóbb tárolási megoldásokat használnak, mint a hagyományos adattárházak. Mivel az adatok feldolgozása csak akkor történik meg, amikor szükség van rá, a vállalatok elkerülhetik a felesleges előfeldolgozási költségeket. Ezenkívül az adattavak képesek kezelni a nagy adatmennyiségeket (Big Data), beleértve a strukturált, félig strukturált és strukturálatlan adatokat is, ami lehetővé teszi a vállalatok számára, hogy átfogó képet kapjanak üzleti tevékenységükről.
Az adattavak emellett támogatják az önkiszolgáló analitikát. A megfelelő eszközökkel és képzéssel a felhasználók közvetlenül hozzáférhetnek az adatokhoz, és saját elemzéseket végezhetnek anélkül, hogy az informatikai részlegre kellene támaszkodniuk. Ez felgyorsítja a döntéshozatalt és lehetővé teszi a vállalatok számára, hogy gyorsabban reagáljanak a piaci változásokra.
Azonban az adattavaknak vannak hátrányai is. Az egyik leggyakoribb kihívás a data governance hiánya. Ha az adatok nincsenek megfelelően kezelve és szabályozva, az adattavak könnyen „adat mocsárrá” válhatnak, ahol nehéz megtalálni és értelmezni az adatokat. Ez a helyzet aláássa az adattó értékét, és növeli az adatminőségi problémák kockázatát.
Egy másik kihívás a biztonság. Az adattavakban tárolt nagy mennyiségű és sokféle adat miatt a biztonsági kockázatok is magasabbak. A vállalatoknak megfelelő biztonsági intézkedéseket kell bevezetniük az adatok védelme érdekében, beleértve a hozzáférés-szabályozást, az adattitkosítást és az adatok auditálását.
A szakértelem hiánya is problémát jelenthet. Az adattavak hatékony kihasználása speciális ismereteket igényel az adatok kezelése, feldolgozása és elemzése terén. A vállalatoknak be kell ruházniuk a munkatársak képzésébe, vagy külső szakértőket kell felvenniük, hogy biztosítsák az adattó sikeres működését.
Az adattavak sikeres bevezetése és használata jelentős tervezést, gondos adatkezelési gyakorlatokat és a megfelelő technológiák kiválasztását igényli.
Végül, a komplexitás is jelentős akadályt jelenthet. Az adattavak integrálása a meglévő informatikai rendszerekbe bonyolult és időigényes feladat lehet. A vállalatoknak alaposan meg kell tervezniük az adattó architektúráját, és gondoskodniuk kell arról, hogy az kompatibilis legyen a meglévő rendszereikkel.
Összességében az adattavak jelentős potenciált kínálnak a vállalatok számára az analitika területén, de a sikeres bevezetés és használat gondos tervezést és megfelelő adatkezelési gyakorlatokat igényel. A vállalatoknak figyelembe kell venniük az előnyöket és hátrányokat, és olyan stratégiát kell kidolgozniuk, amely maximalizálja az adattó értékét, miközben minimalizálja a kockázatokat.
Adattó használati esetei: Valós példák az iparágakból
Az adattavak (data lakes) elterjedése az elmúlt években jelentősen megnőtt, köszönhetően annak, hogy a vállalatok egyre nagyobb mennyiségű és változatosabb adatot gyűjtenek. Az adattavak használati esetei rendkívül sokrétűek, és szinte minden iparágban megtalálhatók, ahol az adatok elemzésével üzleti értéket lehet teremteni.
Kiskereskedelem: A kiskereskedelemben az adattavak kulcsszerepet játszanak a vásárlói viselkedés elemzésében. A tranzakciós adatok, a weboldal látogatási adatok, a közösségi média bejegyzések és a hűségprogram adatok mind egy adattóban egyesíthetők. Ez lehetővé teszi a vállalatok számára, hogy jobban megértsék a vásárlói preferenciákat, személyre szabott ajánlatokat készítsenek, és optimalizálják a készletgazdálkodást. Például, egy nagy élelmiszerlánc adattó segítségével azonosíthatja azokat a termékeket, amelyek gyakran együtt kerülnek megvásárlásra, és ennek megfelelően helyezheti el a polcokon a termékeket, növelve ezzel az eladásokat.
Pénzügyi szektor: A pénzügyi szektorban az adattavak a csalásfelderítésben, a kockázatkezelésben és az ügyfélélmény javításában játszanak fontos szerepet. A bankok és biztosítótársaságok adattavakban tárolják a tranzakciós adatokat, a hitelkártya adatokat, a biztosítási kötvényeket és az ügyfélprofilokat. Ez lehetővé teszi számukra, hogy komplex elemzéseket végezzenek a csalárd tevékenységek felderítésére, a hitelkockázat felmérésére és a személyre szabott pénzügyi termékek ajánlására.
A csalásfelderítés során az adattóban tárolt adatok segítségével azonosíthatók a szokatlan tranzakciós minták, amelyek csalárd tevékenységre utalhatnak.
Egészségügy: Az egészségügyben az adattavak a betegek ellátásának javításában, a betegségek megelőzésében és a kutatásban játszanak fontos szerepet. A kórházak és klinikák adattavakban tárolják a betegek orvosi leleteit, a laboratóriumi eredményeket, a képalkotó vizsgálatok eredményeit és a gyógyszeres kezeléseket. Ez lehetővé teszi számukra, hogy komplex elemzéseket végezzenek a betegségek kockázati tényezőinek azonosítására, a kezelések hatékonyságának mérésére és a személyre szabott kezelési tervek kidolgozására.
Gyártás: A gyártóiparban az adattavak a termelési folyamatok optimalizálásában, a minőségellenőrzésben és a karbantartás tervezésében játszanak fontos szerepet. A gyárak adattavakban tárolják a gépek szenzoradatait, a termelési adatokat, a minőségellenőrzési adatokat és a karbantartási adatokat. Ez lehetővé teszi számukra, hogy komplex elemzéseket végezzenek a termelési folyamatok hatékonyságának növelésére, a hibák előrejelzésére és a karbantartási költségek csökkentésére. Például, a prediktív karbantartás során az adattóban tárolt adatok segítségével előre jelezhetők a gépek meghibásodásai, így a karbantartás a meghibásodás előtt elvégezhető, elkerülve a termelés leállását.
Telekommunikáció: A telekommunikációs vállalatok adattavakat használnak a hálózati teljesítmény optimalizálására, az ügyfélmegtartásra és az új szolgáltatások fejlesztésére. A hálózati adatok, az ügyfélhívások adatai, a weboldal látogatási adatok és a közösségi média bejegyzések mind egy adattóban egyesíthetők. Ez lehetővé teszi számukra, hogy jobban megértsék a hálózat terhelését, az ügyfelek elégedettségét és az új szolgáltatások iránti igényeket. Például, az ügyfélmegtartás érdekében az adattóban tárolt adatok segítségével azonosíthatók azok az ügyfelek, akik valószínűleg felmondják a szerződésüket, és számukra személyre szabott ajánlatokat lehet kínálni.
Energiaipar: Az energiaiparban az adattavak a termelés optimalizálásában, a hálózat hatékonyabb működtetésében és az energiafogyasztás előrejelzésében játszanak szerepet. Az energia termelők adattavakat használnak a szélturbinák, napelemek, erőművek szenzoradatainak tárolására és elemzésére. Ez lehetővé teszi számukra a termelés optimalizálását, a karbantartási költségek csökkentését. Az energiaszolgáltatók adattavakat használnak az energiafogyasztási adatok elemzésére, ami segít a fogyasztás előrejelzésében és a hálózat hatékonyabb tervezésében.
Médiaszektor: A médiaszektorban az adattavak a tartalomajánlások személyre szabásában, a hirdetések célzásában és a közönség elemzésében játszanak fontos szerepet. A streaming szolgáltatók adattavakban tárolják a felhasználók által megtekintett tartalmakat, a keresési előzményeket és a felhasználói profilokat. Ez lehetővé teszi számukra, hogy személyre szabott tartalomajánlásokat készítsenek, növelve ezzel a felhasználók elégedettségét és a platformon eltöltött időt.
- Adattavak előnyei:
- Rugalmas adatsémák támogatása.
- Nagy mennyiségű adat tárolása költséghatékonyan.
- Különböző elemzési módszerek támogatása.
- Gyors adatfeltárás és prototípus készítés.
A fentiekben bemutatott példák csupán néhány példát jelentenek az adattavak sokrétű felhasználási lehetőségeire. Az adattavak elterjedése várhatóan tovább fog növekedni a jövőben, ahogy a vállalatok egyre inkább felismerik az adatokban rejlő értéket.
Adattó megvalósításának lépései: Tervezés, felépítés és karbantartás
Az adattó megvalósítása egy komplex folyamat, melynek során a nyers, strukturálatlan, félig strukturált és strukturált adatok egy központi tárhelyen kerülnek tárolásra. A sikeres adattó felépítése és működtetése három fő lépésre osztható: tervezés, felépítés és karbantartás.
Tervezés: A tervezési fázis kulcsfontosságú a későbbi sikeres implementáció szempontjából. Itt kerül meghatározásra az adattó célja, a felhasználandó adatok köre, a szükséges infrastruktúra és a biztonsági követelmények. A tervezés során el kell dönteni, hogy milyen üzleti kérdésekre keressük a választ az adattó segítségével. Meghatározásra kerülnek az adatforrások, az adatok betöltésének gyakorisága és módja, valamint az adatok tárolási formátuma. Fontos szempont a skálázhatóság, mivel az adattóban tárolt adatok mennyisége idővel növekedni fog.
A tervezési fázisban elkövetett hibák a későbbiekben jelentős többletköltséget és problémákat okozhatnak.
Felépítés: A felépítési fázis magában foglalja az infrastruktúra kiépítését, az adatok betöltését és a szükséges adattranszformációs folyamatok (ETL/ELT) kialakítását. Az adattó tipikusan felhő alapú platformokon épül ki (pl. AWS S3, Azure Data Lake Storage, Google Cloud Storage), de on-premise megoldások is léteznek. Az adatok betöltése során fontos a megfelelő adatminőség biztosítása. Az ETL/ELT folyamatok célja az adatok tisztítása, transzformálása és a megfelelő formátumba alakítása az elemzésekhez. A felépítés során figyelmet kell fordítani a metaadat-kezelésre, mivel a metaadatok segítségével lehet hatékonyan keresni és felhasználni az adatokat.
Karbantartás: Az adattó karbantartása folyamatos feladat, mely magában foglalja az adatok minőségének ellenőrzését, az infrastruktúra monitorozását, a biztonsági mentések készítését és a teljesítmény optimalizálását. Rendszeresen ellenőrizni kell az adatok frissességét és pontosságát. A biztonsági mentések elengedhetetlenek az adatok védelme érdekében. A teljesítmény optimalizálása érdekében monitorozni kell az adattó terhelését és szükség esetén bővíteni kell az infrastruktúrát. A karbantartás során fontos a változáskezelés, mivel az adattó folyamatosan fejlődik és változik.
A karbantartás során a következő területekre kell kiemelt figyelmet fordítani:
- Adatminőség: Folyamatosan ellenőrizni kell az adatok minőségét és szükség esetén korrigálni kell a hibákat.
- Biztonság: Biztosítani kell az adatok védelmét a jogosulatlan hozzáféréstől.
- Teljesítmény: Optimalizálni kell az adattó teljesítményét a gyors és hatékony elemzések érdekében.
- Skálázhatóság: Biztosítani kell, hogy az adattó képes legyen kezelni a növekvő adatmennyiséget.
Az adattó karbantartása során az alábbi eszközök és technikák használhatók:
- Adatminőség-ellenőrző eszközök: Ezek az eszközök automatikusan ellenőrzik az adatok minőségét és jelzik a problémákat.
- Biztonsági auditok: Rendszeres biztonsági auditokkal fel lehet tárni a potenciális biztonsági réseket.
- Teljesítmény monitorozó eszközök: Ezek az eszközök valós időben monitorozzák az adattó teljesítményét és jelzik a problémákat.
- Automatizált skálázási megoldások: Ezek a megoldások automatikusan bővítik az infrastruktúrát a terhelés növekedésével.
A sikeres adattó megvalósítás kulcsa a gondos tervezés, a hatékony felépítés és a folyamatos karbantartás.
Adattó technológiák és platformok: Hadoop, Spark, felhő alapú megoldások
Az adattavak kiépítése és hatékony használata elképzelhetetlen a megfelelő technológiák és platformok nélkül. Ezek a technológiák biztosítják az adatok tárolását, feldolgozását és elemzését, lehetővé téve a vállalatok számára, hogy értékes betekintést nyerjenek az adataikból. A legelterjedtebb és legfontosabb adattó technológiák közé tartozik a Hadoop, a Spark és a felhő alapú megoldások.
Hadoop: A Hadoop egy nyílt forráskódú, elosztott feldolgozási keretrendszer, amely nagyméretű adathalmazok tárolására és feldolgozására szolgál. Két fő komponense van: a Hadoop Distributed File System (HDFS), amely az adatok tárolását végzi elosztott módon, és a MapReduce, amely az adatok párhuzamos feldolgozását teszi lehetővé. A HDFS lehetővé teszi, hogy az adatokat több gépen tároljuk, így biztosítva a skálázhatóságot és a hibatűrést. A MapReduce pedig lehetővé teszi, hogy az adatokat párhuzamosan feldolgozzuk, ami jelentősen felgyorsítja az elemzéseket. A Hadoop ideális választás nagy mennyiségű, strukturálatlan vagy félig strukturált adat tárolására és feldolgozására, mint például naplófájlok, szenzoradatok vagy közösségi média bejegyzések. A Hadoop ökoszisztémájába számos más eszköz is tartozik, mint például a Hive (SQL-szerű lekérdezésekhez), a Pig (adatfolyam-nyelv) és a HBase (oszloporientált NoSQL adatbázis).
Spark: Az Apache Spark egy gyors és általános célú elosztott feldolgozási rendszer. A Hadoophoz hasonlóan a Spark is képes nagyméretű adathalmazok feldolgozására, de a memóriában történő feldolgozásnak köszönhetően sokkal gyorsabb. A Spark támogatja a valós idejű adatfeldolgozást is, ami ideálissá teszi olyan alkalmazásokhoz, mint a streaming analitika és a gépi tanulás. A Spark rendelkezik egy gazdag API-val, amely támogatja a Java, Scala, Python és R nyelveket, így a fejlesztők széles körének kínál lehetőséget az adatok elemzésére. A Spark fő komponensei közé tartozik a Spark Core (az alapvető feldolgozási motor), a Spark SQL (SQL lekérdezésekhez), a Spark Streaming (valós idejű adatfeldolgozáshoz), a MLlib (gépi tanuló könyvtár) és a GraphX (gráf feldolgozó könyvtár).
Felhő alapú megoldások: A felhő alapú adattó megoldások egyre népszerűbbek, mivel rugalmas, skálázható és költséghatékony alternatívát kínálnak a helyszíni infrastruktúrához képest. A nagy felhőszolgáltatók, mint például az Amazon Web Services (AWS), a Microsoft Azure és a Google Cloud Platform (GCP), mind kínálnak adattó szolgáltatásokat. Az AWS S3 (Simple Storage Service) egy objektumtároló szolgáltatás, amely ideális nagy mennyiségű, strukturálatlan adat tárolására. Az AWS Glue egy teljesen menedzselt ETL (Extract, Transform, Load) szolgáltatás, amely megkönnyíti az adatok betöltését és átalakítását az adattóba. Az Azure Data Lake Storage Gen2 a Hadoop kompatibilis fájlrendszer az Azure felhőben, amely ideális nagyméretű adathalmazok tárolására és feldolgozására. A Google Cloud Storage egy másik objektumtároló szolgáltatás, amely integrálva van a Google Cloud Platform egyéb szolgáltatásaival, mint például a BigQuery (adattárház) és a Dataflow (adatfolyam-feldolgozás). A felhő alapú adattó megoldások lehetővé teszik a vállalatok számára, hogy gyorsan és egyszerűen hozzanak létre adattavakat, anélkül, hogy a hardveres infrastruktúrával kellene foglalkozniuk.
A felhőalapú megoldások, mint az AWS S3, Azure Data Lake Storage Gen2, és Google Cloud Storage, lehetőséget kínálnak a vállalatoknak arra, hogy gyorsan és költséghatékonyan skálázható adattavakat hozzanak létre, minimalizálva a helyszíni infrastruktúra karbantartásával járó terheket.
A technológia kiválasztása az adattó kialakításához nagymértékben függ a vállalat specifikus igényeitől és követelményeitől. Ha a vállalatnak nagy mennyiségű, strukturálatlan adatot kell tárolnia és feldolgoznia, akkor a Hadoop jó választás lehet. Ha a vállalatnak gyors és valós idejű adatfeldolgozásra van szüksége, akkor a Spark lehet a legjobb megoldás. Ha a vállalat a rugalmasságot, a skálázhatóságot és a költséghatékonyságot helyezi előtérbe, akkor a felhő alapú megoldások lehetnek a legmegfelelőbbek. Gyakran előfordul, hogy a vállalatok kombinálják ezeket a technológiákat, hogy a lehető legjobban kihasználják az előnyeiket. Például egy vállalat használhatja a Hadoopot az adatok tárolására, a Sparkot az adatok feldolgozására és a felhő alapú szolgáltatásokat az infrastruktúra biztosítására.
Az adattavak kiépítése és üzemeltetése kihívást jelenthet, különösen a nagyvállalatok számára. A sikeres adattó projektekhez elengedhetetlen a megfelelő szakértelem, a jól megtervezett architektúra és a hatékony adatkezelési gyakorlatok. A vállalatoknak gondoskodniuk kell az adatok minőségéről, biztonságáról és szabályozásáról is. A megfelelő technológiák és platformok kiválasztása és alkalmazása kulcsfontosságú az adattavak sikeréhez.
Adatbiztonság és adatvédelem az adattavakban
Az adattavak, amelyek hatalmas mennyiségű strukturált, félig strukturált és strukturálatlan adatot tárolnak natív formátumukban, különleges kihívásokat jelentenek az adatbiztonság és adatvédelem szempontjából. Mivel az adatok különböző forrásokból származnak és eltérő érzékenységi szintekkel rendelkeznek, a megfelelő biztonsági intézkedések bevezetése elengedhetetlen.
Az egyik legfontosabb szempont az adatokhoz való hozzáférés szabályozása. Ez azt jelenti, hogy csak azok a felhasználók és alkalmazások férhetnek hozzá az adatokhoz, akiknek erre jogosultságuk van. A hozzáférés-szabályozás megvalósítható szerepkör-alapú hozzáférés-vezérléssel (RBAC), amely lehetővé teszi a rendszergazdák számára, hogy a felhasználókat szerepkörökhöz rendeljék, és ezek a szerepkörök határozzák meg az adatokhoz való hozzáférési jogosultságokat.
A titkosítás egy másik kritikus fontosságú biztonsági intézkedés. Az adatok titkosítása nyugalmi állapotban (at rest) és mozgásban (in transit) egyaránt fontos. A nyugalmi állapotban lévő adatok titkosítása megakadályozza, hogy illetéktelen személyek hozzáférjenek az adatokhoz, ha például a tárolóeszközt ellopják vagy feltörik. A mozgásban lévő adatok titkosítása pedig biztosítja, hogy az adatok ne legyenek lehallgathatók, miközben a hálózaton keresztül továbbítják őket.
Az adattavakban tárolt adatok auditálása szintén elengedhetetlen az adatbiztonság szempontjából. Az auditálás lehetővé teszi a szervezetek számára, hogy nyomon kövessék, ki fér hozzá az adatokhoz, mikor, és milyen műveleteket végez velük. Ez segíthet az adatvédelmi incidensek felderítésében és a szabályozási követelményeknek való megfelelésben.
Az adatvédelmi szabályozások (például a GDPR) betartása kulcsfontosságú az adattavak esetében.
A maszkolás és anonimizálás technikák alkalmazása segíthet az érzékeny adatok védelmében. A maszkolás az adatokat úgy módosítja, hogy azok ne legyenek azonosíthatók, míg az anonimizálás az adatokat teljesen eltávolítja, így azok már nem köthetők egy adott személyhez.
A sebezhetőség-kezelés folyamatos monitorozása és javítása is kritikus. Az adattavakban használt szoftverek és infrastruktúra sebezhetőségeinek felderítése és javítása segít megelőzni a kibertámadásokat.
Az incidensre való reagálás tervezése és gyakorlása szintén fontos. Egy jól definiált incidensre való reagálási terv segíthet a szervezeteknek abban, hogy gyorsan és hatékonyan reagáljanak az adatvédelmi incidensekre, minimalizálva a károkat.
A megfelelő adatbiztonsági és adatvédelmi intézkedések bevezetése elengedhetetlen az adattavak sikeres és biztonságos használatához. Ezek az intézkedések segítenek megvédeni az érzékeny adatokat, megfelelni a szabályozási követelményeknek, és fenntartani a bizalmat az adattavak iránt.
A jövő adattavai: Trendek és fejlesztési irányok
Az adattavak jövője szorosan összefügg az analitikai képességek fejlődésével és a big data technológiák terjedésével. A korábbi, főként tárolási megoldásként tekintett adattavak egyre inkább intelligens platformokká válnak, amelyek képesek az adatok automatikus katalogizálására, minőségének javítására és biztonságos kezelésére.
A metaadat-kezelés kulcsfontosságú területté válik. A jövő adattavainak képesnek kell lenniük az adatok származásának, típusának és kontextusának automatikus feltárására és dokumentálására. Ez lehetővé teszi a felhasználók számára, hogy könnyebben megtalálják a releváns adatokat, és biztosítsák azok megbízhatóságát az analitikai folyamatok során.
Az adattavak egyre inkább a mesterséges intelligencia (MI) és a gépi tanulás (ML) központjaivá válnak, ahol az algoritmusok közvetlenül az adatokon futtathatók.
A felhő alapú megoldások terjedése tovább erősíti az adattavak szerepét. A felhő rugalmassága és skálázhatósága lehetővé teszi a szervezetek számára, hogy gyorsan és költséghatékonyan építsenek ki adattavakat, és hozzáférjenek a legújabb analitikai eszközökhöz.
A valós idejű adatfeldolgozás egyre fontosabbá válik az adattavakban. A jövő adattavainak képesnek kell lenniük a streaming adatok fogadására, tárolására és elemzésére, lehetővé téve a szervezetek számára, hogy azonnal reagáljanak a változó piaci körülményekre.
- Adatvirtualizáció: Lehetővé teszi, hogy az adatokhoz anélkül férjünk hozzá, hogy fizikailag mozgatnánk őket.
- Adatminőség-menedzsment: Automatikus eszközökkel biztosítjuk az adatok pontosságát és konzisztenciáját.
- Biztonság és megfelelőség: Fejlett hozzáférés-kezelés és auditálási mechanizmusok védik az adatokat.
A kiberbiztonság kiemelt figyelmet kap. Az adattavaknak képesnek kell lenniük a érzékeny adatok védelmére, a jogosulatlan hozzáférés megakadályozására, és a megfelelőségi követelmények betartására. Ez magában foglalja az adatok titkosítását, a hozzáférési jogosultságok szigorú kezelését és a biztonsági incidensek gyors és hatékony kezelését.
A no-code/low-code platformok elterjedése democratizálja az adathozzáférést és az analitikát. A jövő adattavainak olyan felhasználóbarát interfészeket kell kínálniuk, amelyek lehetővé teszik a nem technikai felhasználók számára is az adatok felfedezését, elemzését és vizualizálását.