

Az adatbázis egy szervezett, strukturált információgyűjtemény, melyet digitálisan tárolunk és érünk el. Lényegében olyan, mint egy hatalmas, elektronikus irattár, ahol az adatokat logikusan rendezzük, hogy könnyen megtalálhassuk és felhasználhassuk őket.
Az adatbázisok alapvető célja, hogy hatékonyan kezeljék az adatokat, lehetővé téve a gyors keresést, lekérdezést, módosítást és törlést. Ez különösen fontos a modern világban, ahol hatalmas mennyiségű adatot kell kezelnünk.
Az adatbázisok nélkülözhetetlenek a legtöbb modern alkalmazás számára, a weboldalaktól kezdve a banki rendszereken át a tudományos kutatásokig.
Alapműködése a következő: az adatokat táblákban tároljuk, ahol minden tábla egy adott témát reprezentál (pl. vásárlók, termékek, rendelések). A táblák sorokból (rekordokból) és oszlopokból (mezőkből) állnak. A sorok egyedi bejegyzéseket tartalmaznak, míg az oszlopok az adott bejegyzés tulajdonságait írják le (pl. vásárló neve, termék ára, rendelés dátuma).
Az adatbázisok lekérdezőnyelveket használnak (pl. SQL), hogy kommunikáljanak az adatbázissal. Ezek a nyelvek lehetővé teszik, hogy meghatározott feltételek alapján keressünk adatokat, módosítsuk a meglévő adatokat, vagy új adatokat adjunk hozzá.
Az adatbázisok nagy előnye, hogy biztonságosak és megbízhatóak. A hozzáférést szabályozhatjuk, így csak az arra jogosultak férhetnek hozzá az adatokhoz. Emellett az adatbázisok gyakran rendelkeznek beépített mechanizmusokkal az adatvesztés elkerülésére, például biztonsági mentések készítésére.
Az adatbázis fogalmának definíciója: strukturált adatok szervezett gyűjteménye
Az adatbázis egy strukturált adatok szervezett gyűjteménye, amelyet úgy terveztek, hogy az adatok hatékonyan tárolhatók, lekérdezhetők, frissíthetők és kezelhetők legyenek. A hagyományos papíralapú rendszerekkel szemben az adatbázisok digitális formában tárolják az információt, ami lehetővé teszi a gyorsabb és pontosabb adatkezelést.
Az adatbázis lényege, hogy az adatokat logikailag összefüggő egységekbe rendezi, ezzel biztosítva az adatok integritását és konzisztenciáját. Ez a szervezett struktúra lehetővé teszi, hogy az adatokat különböző szempontok szerint is lekérdezhessük, így támogatva a döntéshozatalt és az elemzést.
Az adatbázis célja, hogy az adatokat központosítsa és elérhetővé tegye a jogosult felhasználók számára, miközben biztosítja az adatok biztonságát és védelmét.
Az adatbázisok alapvető működése a következő lépésekből áll:
- Adatok tárolása: Az adatokat meghatározott formátumban tároljuk (pl. táblákban, dokumentumokban).
- Adatok lekérdezése: SQL vagy más lekérdező nyelvek segítségével keressük ki a szükséges információkat.
- Adatok frissítése: Az adatok módosítása, hozzáadása vagy törlése.
- Adatok kezelése: Az adatbázis karbantartása, biztonsági mentése és optimalizálása.
Az adatbázisok különböző típusai léteznek, például relációs adatbázisok (pl. MySQL, PostgreSQL) és NoSQL adatbázisok (pl. MongoDB, Cassandra). A relációs adatbázisok táblákban tárolják az adatokat, amelyek között kapcsolatok vannak. A NoSQL adatbázisok pedig rugalmasabb adatszerkezeteket használnak, és nagy mennyiségű adat kezelésére optimalizáltak.
Az adatbázisok nélkülözhetetlenek a modern információs társadalomban. Számos területen használják őket, például a pénzügyekben, a kereskedelemben, az egészségügyben és az oktatásban.
Az adatbázisok története: az első adatbázis-modellektől a modern rendszerekig
Az adatbázisok fejlődése szorosan összefonódik az adatkezelési igények növekedésével. Az első adatbázis-modellek az 1960-as években jelentek meg, válaszul a vállalatok egyre komplexebb adatainak kezelésére. Ezek a korai modellek, mint például a hierarchikus és a hálózati modell, lehetővé tették az adatok szervezett tárolását és visszakeresését, de rugalmatlanságuk és bonyolultságuk korlátozta alkalmazásukat.
A valódi áttörést az 1970-es évek hozták el Edgar F. Codd nevéhez fűződő relációs modell megjelenésével. A relációs modell az adatokat táblákban (relációkban) ábrázolja, amelyek sorokból (rekordokból) és oszlopokból (attribútumokból) állnak. Ez a modell egyszerűbb, rugalmasabb és könnyebben kezelhető volt a korábbi modelleknél, és lehetővé tette a SQL (Structured Query Language) nevű szabványos lekérdezőnyelv használatát. A relációs adatbázisok gyorsan elterjedtek, és a mai napig is a legelterjedtebb adatbázis-típusnak számítanak.
A relációs modell a modern adatbázis-kezelés alapkövévé vált, forradalmasítva az adatok tárolását és visszakeresését.
A 20. század végén és a 21. század elején az internet robbanásszerű terjedése és a big data megjelenése új kihívások elé állította az adatbázis-kezelést. A hagyományos relációs adatbázisok nem voltak eléggé skálázhatók és rugalmasak a nagy mennyiségű, változatos és gyorsan változó adatok kezelésére. Ennek eredményeként megjelentek a NoSQL (Not Only SQL) adatbázisok, amelyek különböző adatmodelleket (pl. dokumentumorientált, kulcs-érték, oszloporientált, gráf adatbázisok) használnak, és a relációs adatbázisoknál nagyobb rugalmasságot és skálázhatóságot kínálnak. A NoSQL adatbázisok különösen alkalmasak webes alkalmazások, közösségi média platformok és más nagy adatot kezelő rendszerek számára.
Napjainkban az adatbázisok fejlődése tovább folytatódik, a felhőalapú adatbázisok, az in-memory adatbázisok és a gépi tanulási adatbázisok egyre nagyobb teret hódítanak. Ezek a modern adatbázisok lehetővé teszik az adatok hatékonyabb tárolását, kezelését és elemzését, és új lehetőségeket nyitnak meg a vállalkozások számára az adatok értékének kiaknázásában.
Adatbázis-kezelő rendszerek (DBMS): a szerepük és fontosságuk

Az adatbázisok használatához elengedhetetlenek az adatbázis-kezelő rendszerek (DBMS). Ezek a szoftverek biztosítják a kapcsolatot a felhasználó és az adatbázis között.
A DBMS fő feladata, hogy lehetővé tegye az adatok tárolását, lekérdezését, frissítését és törlését. Ezen felül gondoskodik az adatok biztonságáról, integritásáról és konzisztenciájáról. Képzeljük el, hogy egy könyvtárban a DBMS a könyvtáros, aki segít megtalálni a megfelelő könyvet, gondoskodik arról, hogy a könyvek rendben legyenek, és megakadályozza, hogy valaki ellopja őket.
A DBMS kulcsfontosságú szerepet játszik az adatok hatékony kezelésében, ezáltal lehetővé téve a vállalatok számára, hogy megalapozott döntéseket hozzanak.
A DBMS-ek különböző típusai léteznek, például relációs (RDBMS), NoSQL és objektumorientált adatbázis-kezelők. A relációs adatbázis-kezelők (mint a MySQL, PostgreSQL, Oracle) az adatokat táblákban tárolják, míg a NoSQL adatbázisok (mint a MongoDB, Cassandra) rugalmasabb adatmodelleket kínálnak, amelyek alkalmasak a nagy mennyiségű, strukturálatlan adatok kezelésére.
A DBMS nélkül az adatok kezelése nehézkes és időigényes lenne, ami komoly problémákat okozhat a vállalatok számára. Ezért a DBMS a modern informatikai rendszerek alapvető eleme.
A leggyakoribb adatbázis-modellek: hierarchikus, hálózati, relációs, objektumorientált
Az adatbázis-modellek különböző módokon szervezik és tárolják az adatokat. Négy elterjedt modell létezik:
- Hierarchikus modell: Ebben a modellben az adatok fa struktúrában helyezkednek el, ahol minden elemnek egyetlen szülője lehet, és több gyermeke. Gyors hozzáférést biztosít az adatokhoz, de kevésbé rugalmas a komplex kapcsolatok kezelésére.
- Hálózati modell: A hierarchikus modell továbbfejlesztése, amely lehetővé teszi, hogy egy elemnek több szülője is legyen. Ezáltal komplexebb kapcsolatok ábrázolására alkalmas, de a struktúrája bonyolultabbá teszi a karbantartást.
- Relációs modell: A legelterjedtebb modell, amely táblákban tárolja az adatokat, ahol a sorok rekordokat, az oszlopok pedig attribútumokat jelentenek. A táblák közötti kapcsolatokat kulcsok segítségével definiálják.
Ez a modell nagy rugalmasságot és adatintegritást biztosít, és könnyen lekérdezhető SQL segítségével.
- Objektumorientált modell: Ebben a modellben az adatok objektumokba vannak szervezve, amelyek attribútumokkal és metódusokkal rendelkeznek. Lehetővé teszi komplex adatstruktúrák és kapcsolatok ábrázolását, valamint támogatja az öröklődést és a polimorfizmust.
A hierarchikus és hálózati modellek ma már kevésbé elterjedtek, mivel kevésbé rugalmasak és nehezebben kezelhetők, mint a relációs modell. Az objektumorientált modellek a relációs modellekkel együtt használatosak, különösen komplex alkalmazások esetén.
A relációs modell alapelve a normalizálás, ami az adatok redundanciájának minimalizálását és az adatintegritás megőrzését célozza. A normalizálás során az adatokat több táblába bontják, és a táblák közötti kapcsolatokat kulcsok segítségével definiálják.
Az objektumorientált adatbázisok előnyei közé tartozik a komplex adatok kezelése, az adatmodell rugalmassága és a kód újrafelhasználhatósága. Ugyanakkor a relációs adatbázisokhoz képest kevésbé elterjedtek, és a lekérdezési nyelvek is kevésbé kifinomultak.
A választás a különböző modellek között az adott alkalmazás igényeitől függ. A relációs modell továbbra is a leggyakoribb választás a legtöbb alkalmazás számára, de a hierarchikus, hálózati és objektumorientált modellek is hasznosak lehetnek speciális esetekben.
Relációs adatbázisok részletesen: táblák, sorok, oszlopok, kulcsok
A relációs adatbázisok a legelterjedtebb adatbázis-modellek közé tartoznak. Lényegük, hogy az adatokat táblákban tárolják, amelyek sorokból és oszlopokból állnak. Képzeljük el a táblát egy Excel táblázatként.
Tábla: Egy adott entitás (pl. ügyfél, termék, rendelés) adatait tartalmazza. Minden táblának van egy neve, ami egyedivé teszi az adatbázison belül.
Sor (rekord): Egy táblán belül egyetlen entitás egyedi példányát reprezentálja. Például egy ügyfél összes adata (név, cím, telefonszám) egy sorban kerül tárolásra.
Oszlop (mező, attribútum): Egy adott adattípust reprezentál a táblán belül. Minden oszlopnak van egy neve, ami leírja, hogy milyen adatokat tartalmaz (pl. Ügyfél_név, Termék_ár, Rendelés_dátuma). Az oszlopok típusa meghatározza, hogy milyen adatokat tárolhatunk bennük (pl. szöveg, szám, dátum).
A relációs adatbázisok ereje abban rejlik, hogy a táblák közötti kapcsolatok definiálhatók. Ezek a kapcsolatok a kulcsok segítségével valósulnak meg.
Kulcsok: Az adatbázis integritásának és a táblák közötti kapcsolatoknak a biztosítására szolgálnak.
- Elsődleges kulcs (Primary Key): Egy táblán belül egyedileg azonosít egy sort. Nem lehet NULL (üres) értékű, és egy táblának csak egy elsődleges kulcsa lehet. Gyakran egy sorszám (ID) szerepel ebben a mezőben.
- Idegen kulcs (Foreign Key): Egy másik tábla elsődleges kulcsára hivatkozik. Az idegen kulcs biztosítja, hogy a táblák közötti kapcsolat érvényes legyen, és ne lehessen olyan adatokra hivatkozni, amelyek nem léteznek a másik táblában.
Az idegen kulcsok kulcsfontosságúak a relációs adatbázisok integritásának megőrzésében, mivel biztosítják, hogy a táblák közötti kapcsolatok konzisztensek és érvényesek maradjanak.
Például, ha van egy „Ügyfelek” táblánk (elsődleges kulcs: Ügyfél_ID) és egy „Rendelések” táblánk (elsődleges kulcs: Rendelés_ID), akkor a „Rendelések” táblában lehet egy „Ügyfél_ID” oszlop, ami idegen kulcsként hivatkozik az „Ügyfelek” tábla „Ügyfél_ID” oszlopára. Ezáltal tudjuk, hogy melyik rendelést melyik ügyfél adta le.
A kulcsok használata lehetővé teszi az adatok hatékony lekérdezését és manipulálását. Az SQL (Structured Query Language) segítségével bonyolult lekérdezéseket fogalmazhatunk meg, amelyek több táblából származó adatokat kombinálnak.
Például:
- Lekérdezhetjük az összes olyan rendelést, amelyet egy adott ügyfél adott le.
- Megkereshetjük azokat a termékeket, amelyeket a legtöbbször rendeltek.
- Kiszámíthatjuk az egyes ügyfelek által elköltött összeget.
A relációs adatbázisok használata számos előnnyel jár, beleértve az adatok konzisztenciáját, integritását, biztonságát és hatékony lekérdezhetőségét.
SQL: az adatbázisok lekérdezőnyelve – alapvető parancsok és használat
Az SQL (Structured Query Language) az adatbázis-kezelő rendszerek (DBMS) standard lekérdezőnyelve. Lehetővé teszi, hogy adatokat kérdezzünk le, módosítsunk és kezeljünk relációs adatbázisokban.
Az SQL alapvető parancsai közé tartoznak:
- SELECT: Adatok lekérdezésére szolgál egy vagy több táblából. Például:
SELECT * FROM Felhasználók; - INSERT: Új adatok beszúrása egy táblába. Például:
INSERT INTO Termékek (nev, ar) VALUES ('Laptop', 120000); - UPDATE: Meglévő adatok módosítása egy táblában. Például:
UPDATE Felhasználók SET email = 'új@email.hu' WHERE id = 1; - DELETE: Adatok törlése egy táblából. Például:
DELETE FROM Termékek WHERE id = 5;
Az SQL nem csak az adatokkal való manipulációra használható, hanem adatbázis-struktúrák létrehozására és kezelésére is. Ehhez a következő parancsok állnak rendelkezésre:
- CREATE TABLE: Új tábla létrehozása. Például:
CREATE TABLE Rendelések (id INT PRIMARY KEY, felhasználó_id INT, dátum DATE); - ALTER TABLE: Egy meglévő tábla szerkezetének módosítása (pl. oszlop hozzáadása vagy törlése). Például:
ALTER TABLE Felhasználók ADD COLUMN jelszo VARCHAR(255); - DROP TABLE: Egy tábla törlése. Például:
DROP TABLE Rendelések;
A SELECT parancs rendkívül sokoldalú. Használható szűrésre a WHERE záradékkal:
SELECT nev, ar FROM Termékek WHERE ar > 100000; (Ez a parancs lekérdezi a termékek nevét és árát, de csak azokat, amelyek ára nagyobb, mint 100000.)
Továbbá, az ORDER BY záradékkal rendezhetjük az eredményeket:
SELECT * FROM Felhasználók ORDER BY vezeteknev ASC, keresztnev DESC; (Ez a parancs lekérdezi az összes felhasználót, rendezi őket vezetéknevük szerint növekvő sorrendben, majd az azonos vezetéknevűeket keresztnevük szerint csökkenő sorrendben.)
Az SQL lehetővé teszi több tábla összekapcsolását is a JOIN művelettel. Ez különösen hasznos, ha az adatok több táblában vannak tárolva, és összefüggések vannak közöttük.
A JOIN művelet lehetővé teszi, hogy két vagy több táblából származó adatokat kombináljunk egyetlen eredményhalmazba, egy közös oszlop alapján.
Például, ha van egy „Felhasználók” táblánk és egy „Rendelések” táblánk, akkor a következőképpen kérdezhetjük le az összes felhasználó nevét és a hozzájuk tartozó rendelések számát:
SELECT Felhasználók.nev, COUNT(Rendelések.id) AS rendelesek_szama FROM Felhasználók INNER JOIN Rendelések ON Felhasználók.id = Rendelések.felhasználó_id GROUP BY Felhasználók.nev;
Az SQL aggregáló függvényeket is tartalmaz, mint például COUNT, SUM, AVG, MIN és MAX, amelyek lehetővé teszik, hogy statisztikai adatokat számoljunk ki az adatokból. A GROUP BY záradékkal kombinálva ezek a függvények nagyon hatékonyak az adatok elemzésére.
Az SQL egy deklaratív nyelv, ami azt jelenti, hogy meg kell adnunk, *mit* szeretnénk lekérdezni vagy módosítani, ahelyett, hogy megadnánk, *hogyan* kell azt megtenni. Az adatbázis-kezelő rendszer optimalizálja a lekérdezést, hogy a lehető leggyorsabban adja vissza az eredményt.
Adatbázis tervezés: normalizálás, ER-diagramok, adatmodellezés
Az adatbázis tervezés kulcsfontosságú része az adatbázis-kezelésnek, amely biztosítja, hogy az adatok hatékonyan, konzisztensen és megbízhatóan legyenek tárolva és kezelve. Három alapvető koncepciót foglal magában: a normalizálást, az ER-diagramokat és az adatmodellezést.
A normalizálás egy olyan folyamat, amely során az adatbázis tábláit úgy strukturáljuk, hogy minimalizáljuk az adatok redundanciáját (ismétlődését) és javítsuk az adatok integritását. Ez azt jelenti, hogy az adatokat logikus csoportokba rendezzük, és meghatározzuk a táblák közötti kapcsolatokat. A normalizálásnak több szintje van (pl. 1NF, 2NF, 3NF, BCNF), amelyek mindegyike szigorúbb szabályokat követ az adatok szerkezetére vonatkozóan. A cél a függőségek megszüntetése, ami azt jelenti, hogy egy táblában lévő nem-kulcs attribútum nem függhet egy másik nem-kulcs attribútumtól, hanem csak a kulcstól.
A normalizálás célja az adatok redundanciájának minimalizálása és az adatok integritásának javítása.
Az ER-diagramok (Entity-Relationship diagramok) vizuális eszközök az adatbázis sémájának tervezéséhez. Az ER-diagramok segítségével ábrázolhatjuk az entitásokat (azokat a dolgokat, amiket az adatbázisban tárolunk, pl. ügyfelek, termékek, rendelések) és a köztük lévő kapcsolatokat (pl. egy ügyfél rendeléseket ad le, egy termék szerepel egy rendelésben). Az ER-diagramok elemei: entitások (téglalapok), attribútumok (ellipszisek) és kapcsolatok (rombuszok). A kapcsolatoknak lehet kardinalitása is (pl. egy-egy, egy-több, több-több), ami meghatározza, hogy egy entitás hány másik entitással állhat kapcsolatban.
Az adatmodellezés az a folyamat, amely során meghatározzuk az adatbázis szerkezetét és szabályait. Az adatmodellezés során különböző modelleket használhatunk, például:
- Konceptuális adatmodell: Ez a legmagasabb szintű modell, amely az üzleti követelményeket tükrözi. Nem foglalkozik a fizikai implementációval.
- Logikai adatmodell: Ez a modell meghatározza az entitásokat, attribútumokat és kapcsolatokat, de független a konkrét adatbázis-kezelő rendszertől.
- Fizikai adatmodell: Ez a modell a konkrét adatbázis-kezelő rendszerhez igazodik, és meghatározza a táblák szerkezetét, az adattípusokat, az indexeket és a korlátozásokat.
Az adatmodellezés során figyelembe kell venni a követelményeket, az adatok jellegét és a teljesítményt. A jó adatmodell biztosítja, hogy az adatok pontosak, konzisztensek és könnyen lekérdezhetőek legyenek.
A normalizálás, az ER-diagramok és az adatmodellezés szorosan összefüggenek. Az ER-diagramok segítenek a logikai adatmodell megtervezésében, a normalizálás pedig biztosítja, hogy az adatok redundanciája minimalizálva legyen a fizikai adatmodellben. A helyes adatbázis tervezés elengedhetetlen a hatékony és megbízható adatkezeléshez.
Adatbázis biztonság: hozzáférés-szabályozás, titkosítás, auditálás
Az adatbázisok biztonsága kiemelten fontos aspektus, hiszen ezek a rendszerek érzékeny adatokat tárolnak, melyek illetéktelen kezekbe kerülve komoly károkat okozhatnak. A biztonság megteremtése több lépcsős folyamat, melynek alapjai a hozzáférés-szabályozás, a titkosítás és az auditálás.
A hozzáférés-szabályozás célja, hogy csak az arra jogosult felhasználók férhessenek hozzá az adatbázis tartalmához. Ezt többféle módon lehet megvalósítani. Az egyik legelterjedtebb módszer a szerepkör alapú hozzáférés-szabályozás (RBAC), ahol a felhasználók nem közvetlenül kapnak jogosultságokat, hanem szerepkörökhöz vannak rendelve, és a szerepkörök rendelkeznek a megfelelő jogosultságokkal. Így a felhasználók kezelése egyszerűbbé válik, és a jogosultságok következetesebbé tehetők.
A titkosítás az adatok védelmének egy másik fontos eszköze. Az adatokat titkosítva tároljuk, így ha valaki illetéktelenül hozzáfér is az adatbázishoz, nem fogja tudni elolvasni a titkosított adatokat. A titkosítás történhet nyugalmi állapotban (adatbázisban tárolt adatok titkosítása) és mozgásban (adatok hálózaton keresztüli továbbításának titkosítása) is. A titkosításhoz különböző algoritmusokat használnak, melyek közül a legelterjedtebbek az AES és az RSA.
Az adatbázis biztonságának kulcsa a többrétegű védelem kialakítása, ahol a különböző biztonsági mechanizmusok egymást erősítik.
Az auditálás az adatbázisban végzett tevékenységek naplózását jelenti. Az auditnaplók rögzítik, hogy ki, mikor, mit csinált az adatbázisban. Ez lehetővé teszi a biztonsági incidensek felderítését, a felelősség megállapítását és a biztonsági rések azonosítását. Az auditnaplókat rendszeresen ellenőrizni kell, és gondoskodni kell azok védelméről, hogy ne lehessen őket manipulálni.
A megfelelő adatbázis biztonsági stratégia kialakítása folyamatos feladat, melyhez rendszeres felülvizsgálatokra, frissítésekre és tesztelésekre van szükség. A biztonsági megoldásoknak illeszkedniük kell az adatbázis egyedi igényeihez és a szervezet biztonsági politikájához.
Adatbázis teljesítmény: indexelés, optimalizálás, tuning
Az adatbázisok teljesítménye kritikus fontosságú a modern alkalmazások szempontjából. Egy lassan működő adatbázis komoly problémákat okozhat, ezért elengedhetetlen a teljesítmény optimalizálása. Ennek kulcselemei az indexelés, az optimalizálás és a tuning.
Az indexelés lényege, hogy bizonyos oszlopokra indexeket hozunk létre. Ezáltal az adatbázis gyorsabban tudja megtalálni a keresett adatokat, hiszen nem kell a teljes táblát végigpásztáznia. Az indexek olyanok, mint egy könyv tartalomjegyzéke: segítenek gyorsan eljutni a megfelelő oldalra. A túlzott indexelés azonban lassíthatja az adatbázist, mivel minden módosításkor az indexeket is frissíteni kell. Ezért fontos a megfelelő indexek kiválasztása.
Az optimalizálás magában foglalja a lekérdezések (query-k) finomhangolását. Gyakran előfordul, hogy egy lekérdezést többféleképpen is meg lehet írni, de a különböző megközelítések jelentősen eltérő teljesítményt eredményezhetnek. Az adatbázisok rendelkeznek lekérdezés-optimalizálóval, ami megpróbálja a leggyorsabb végrehajtási tervet kiválasztani. Azonban a fejlesztők is sokat tehetnek a lekérdezések optimalizálásáért, például a nem használt oszlopok lekérdezésének elkerülésével, vagy a WHERE feltételek hatékony megfogalmazásával.
A teljesítménytuning az adatbázis szerver konfigurációjának finomhangolását jelenti.
Ez magában foglalhatja például a memória-beállítások optimalizálását, a puffer méretek növelését, vagy a párhuzamos végrehajtás engedélyezését. A tuning során figyelembe kell venni a hardveres korlátokat és az alkalmazás specifikus igényeit. A tuning egy iteratív folyamat, melynek során folyamatosan monitorozzuk a teljesítményt és finomhangoljuk a beállításokat.
NoSQL adatbázisok: típusok, előnyök, hátrányok
A NoSQL adatbázisok, ellentétben a relációs adatbázisokkal (SQL), nem támaszkodnak a táblázatos, sor-oszlop alapú struktúrára. Ehelyett különböző adatszerkezeteket használnak, amelyek jobban illeszkednek a modern alkalmazások igényeihez.
Típusai:
- Kulcs-érték tárolók: Egyszerűen kulcsokhoz rendelnek értékeket. Példa: Redis, Memcached.
- Dokumentum adatbázisok: Dokumentumokat (pl. JSON, XML) tárolnak. Példa: MongoDB, Couchbase.
- Oszloporientált adatbázisok: Az adatokat oszlopokban tárolják, nem sorokban. Példa: Cassandra, HBase.
- Gráf adatbázisok: Kapcsolatok tárolására optimalizáltak, csomópontok és élek segítségével. Példa: Neo4j.
Előnyök:
- Rugalmasság: A sémák kevésbé szigorúak, így könnyebb az adatmodell változtatása.
- Skálázhatóság: Könnyebben skálázhatók horizontálisan, elosztott rendszerekben.
- Teljesítmény: Bizonyos használati esetekben gyorsabb lekérdezéseket tesznek lehetővé.
- Fejlesztői agilitás: Gyorsabb prototípus fejlesztést és iterációt tesznek lehetővé.
Hátrányok:
- Adatkonzisztencia: Nem minden NoSQL adatbázis garantálja az azonnali konzisztenciát (ACID).
- Komplex lekérdezések: A relációs adatbázisokhoz képest nehezebb komplex lekérdezéseket végrehajtani.
- Érettség: A relációs adatbázisokhoz képest kevésbé érettek, kevesebb a tapasztalat és a rendelkezésre álló eszköz.
- Tranzakciókezelés: Korlátozottabbak a tranzakciókezelési lehetőségek.
A NoSQL adatbázisok kiválasztása mindig az adott alkalmazás egyedi igényeitől függ.
Az adatmodell kiválasztása kulcsfontosságú. Például, ha egy alkalmazásban sok a kapcsolat az adatok között, akkor egy gráf adatbázis lehet a legjobb választás. Ha viszont a rugalmasság és a gyors iteráció a fontos, akkor egy dokumentum adatbázis lehet a megfelelőbb.
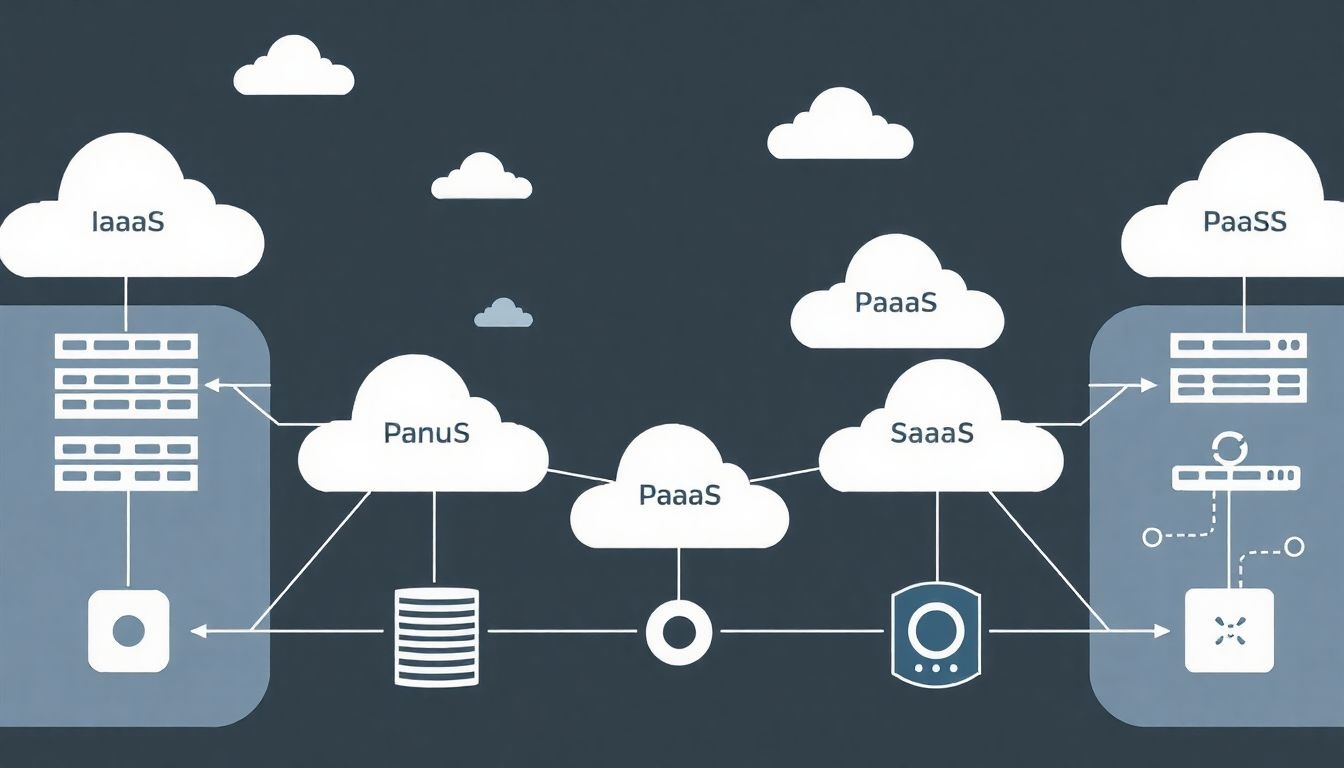
Felhő alapú adatbázisok: szolgáltatásmodellek (IaaS, PaaS, SaaS), előnyök és kihívások
A felhő alapú adatbázisok az adatbázis-kezelés modern megközelítését képviselik, ahol az adatbázisok nem a helyi szervereken, hanem a felhőben futnak. Ez a modell számos előnnyel jár, de kihívásokkal is szembe kell nézni.
A felhő alapú adatbázisok különböző szolgáltatásmodellekben érhetők el:
- IaaS (Infrastructure as a Service): Ebben a modellben a felhasználó a teljes infrastruktúrát bérli, beleértve a szervereket, a hálózatot és a tárolást. Az adatbázis szoftvert a felhasználónak kell telepítenie és karbantartania. Ez a modell maximális kontrollt biztosít, de magasabb technikai szakértelmet igényel.
- PaaS (Platform as a Service): A felhasználó itt egy kész platformot kap az adatbázis futtatásához. A felhőszolgáltató gondoskodik az operációs rendszerről, az adatbázis szoftverről és a frissítésekről. A felhasználónak csak az adatbázis sémájára és az adatokra kell koncentrálnia.
- SaaS (Software as a Service): Ez a leginkább felhasználóbarát modell, ahol a felhasználó egy kész alkalmazást használ, amelynek része az adatbázis. A felhőszolgáltató mindenről gondoskodik, a felhasználónak nincs beleszólása az adatbázis konfigurációjába.
A felhő alapú adatbázisok egyik legfőbb előnye a skálázhatóság, ami lehetővé teszi az erőforrások dinamikus növelését vagy csökkentését a terhelés függvényében.
A felhő alapú adatbázisok további előnyei:
- Költségcsökkentés: Nincs szükség a helyi infrastruktúra kiépítésére és karbantartására, ami jelentős költségmegtakarítást eredményezhet.
- Rugalmasság: Az erőforrások igény szerint skálázhatók, ami lehetővé teszi a gyors reagálást a változó üzleti igényekre.
- Magas rendelkezésre állás: A felhőszolgáltatók redundáns infrastruktúrát biztosítanak, ami minimalizálja az állásidőt.
A kihívások közé tartozik:
- Biztonság: Az adatok a felhőben tárolódnak, ami biztonsági kockázatokat vet fel. A felhasználónak meg kell győződnie arról, hogy a felhőszolgáltató megfelelő biztonsági intézkedéseket alkalmaz.
- Adatvédelem: A felhőben tárolt adatokra vonatkozó adatvédelmi szabályozások betartása komplex feladat lehet.
- Vendor lock-in: Az egyik felhőszolgáltatótól a másikhoz való migráció költséges és időigényes lehet.
A megfelelő szolgáltatásmodell kiválasztása az adott üzleti igényektől és a rendelkezésre álló technikai szakértelemtől függ. Gondos tervezéssel és a kockázatok kezelésével a felhő alapú adatbázisok jelentős előnyöket kínálhatnak.
Adatbázis replikáció és magas rendelkezésre állás
Az adatbázisok magas rendelkezésre állásának biztosítása kritikus fontosságú a modern üzleti alkalmazások számára. Ennek egyik kulcsfontosságú eleme az adatbázis replikáció.
A replikáció lényege, hogy az adatbázis tartalmát több szerveren is tároljuk. Ezáltal, ha az egyik szerver meghibásodik, egy másik szerver azonnal átveszi a feladatát, minimalizálva a kiesést. Két fő típusa létezik: az aszinkron és a szinkron replikáció.
Az aszinkron replikáció esetén az adatok másolása nem azonnal történik meg minden szerveren. Ez gyorsabb, de fennáll az adatok elvesztésének kockázata egy szerverhiba esetén. Ezzel szemben a szinkron replikáció garantálja, hogy minden szerveren azonos adatok legyenek, de ez lassabb működést eredményez.
A megfelelő replikációs stratégia kiválasztása az alkalmazás igényeitől függ.
A magas rendelkezésre állás érdekében gyakran használnak failover mechanizmusokat is. Ez azt jelenti, hogy ha az elsődleges adatbázis szerver meghibásodik, a rendszer automatikusan átkapcsol egy készenléti (standby) szerverre. Ez az átkapcsolás szinte észrevehetetlen a felhasználók számára, biztosítva a folyamatos működést.
A replikáció és a failover kombinációja biztosítja, hogy az adatbázisunk mindig elérhető legyen, minimalizálva a kiesési időt és a potenciális adatvesztést.
Big Data és adatbázisok: Hadoop, Spark, adat tavak
A Big Data korszakában az adatbázisok szerepe jelentősen átalakult. A hagyományos relációs adatbázisok már nem mindig elegendőek a hatalmas mennyiségű, változatos (strukturált, strukturálatlan és félig strukturált) adatok kezelésére. Ezért jöttek létre olyan technológiák, mint a Hadoop, a Spark és az adat tavak.
A Hadoop egy elosztott fájlrendszer (HDFS) és egy programozási modell (MapReduce), amely lehetővé teszi a nagyméretű adathalmazok párhuzamos feldolgozását. Nem egy hagyományos adatbázis, hanem inkább egy platform, amely lehetővé teszi az adatok tárolását és feldolgozását elosztott módon.
A Spark egy gyors, általános célú klaszter számítási rendszer. A Hadoophoz hasonlóan elosztott környezetben működik, de a memóriában tartja az adatokat, ami jelentősen felgyorsítja a feldolgozást. A Spark ideális az iteratív algoritmusokhoz és az interaktív adatelemzéshez.
Az adat tavak központi adattárak, amelyekben nagy mennyiségű nyers, strukturálatlan vagy félig strukturált adatot tárolnak.
Az adat tavak lehetővé teszik az adatok tárolását eredeti formátumukban, anélkül, hogy előre definiált sémához kellene igazodniuk. Ez nagy rugalmasságot biztosít az adatok elemzéséhez és felhasználásához. Az adat tavak gyakran használják a Hadoop és a Spark technológiákkal együtt, hogy kihasználják azok elosztott feldolgozási képességeit.
Ezek a technológiák kiegészítik a hagyományos adatbázisokat, lehetővé téve a szervezetek számára, hogy hatékonyabban kezeljék és elemezzék a Big Data-t.
Adatbázisok a gyakorlatban: példák különböző iparágakban
Az adatbázisok a modern üzleti élet alapkövei, szinte minden iparágban megtalálhatók. Lényegük, hogy strukturáltan tárolják az adatokat, lehetővé téve a hatékony lekérdezést és manipulációt.
A kereskedelemben az adatbázisok a vásárlói adatok, a termékkatalógusok, a rendelések és a készletkezelés központjai. Egy webáruház például adatbázisban tárolja a felhasználók adatait, a termékek leírását, árát, elérhetőségét. Amikor egy felhasználó keres egy terméket, az adatbázisban történik a keresés, és az eredmények megjelennek a weboldalon.
A pénzügyi szektorban, például a bankoknál, az adatbázisok elengedhetetlenek a tranzakciók rögzítéséhez, az ügyfélprofilok kezeléséhez és a kockázatkezeléshez. A bankok hatalmas mennyiségű adatot kezelnek naponta, és az adatbázisok biztosítják, hogy ezek az adatok biztonságosan és hatékonyan legyenek tárolva és feldolgozva.
Az egészségügyben az adatbázisok a betegek kórtörténetét, a kezeléseket és a laboreredményeket tárolják. Ez lehetővé teszi az orvosok számára, hogy gyorsan hozzáférjenek a páciens információihoz, ami elengedhetetlen a pontos diagnózishoz és a hatékony kezeléshez. Az adatbázisok segítenek a kutatásban is, lehetővé téve a nagy adathalmazok elemzését.
A gyártásban az adatbázisok a termelési folyamatok, a készletek és a beszállítók adatait kezelik. A vállalatok nyomon követhetik a termelési folyamatot, optimalizálhatják a készleteket és javíthatják a hatékonyságot.
Az adatbázisok tehát nem csupán adatok tárolására szolgálnak, hanem az üzleti döntések meghozatalának alapját is képezik.
A közigazgatásban az adatbázisok a lakossági nyilvántartások, az adóügyek és a közszolgáltatások kezeléséhez használatosak. Ezek az adatbázisok biztosítják, hogy az állampolgárok adatai biztonságosan és hatékonyan legyenek kezelve.
Az oktatásban az adatbázisok a diákok adatait, a tanterveket és az osztályzatokat tárolják. Az adatbázisok segítségével az oktatási intézmények hatékonyan kezelhetik a diákok adatait, nyomon követhetik a tanulmányi előmenetelt és javíthatják az oktatási folyamatokat.