

A NUMA (Non-Uniform Memory Access) egy olyan számítógép-architektúra, amelyben a memória-hozzáférési idő függ a memória helyétől a processzorhoz képest. Ez azt jelenti, hogy a processzorok gyorsabban érik el a hozzájuk fizikailag közelebb eső memóriaterületeket, mint a távolabbiakat. Ezzel szemben a UMA (Uniform Memory Access) architektúrában minden processzor egyformán gyorsan éri el a teljes memóriaterületet.
A NUMA architektúrák elterjedése a multiproc esszoros rendszerek teljesítményigényének növekedésével függ össze. Ahogy egyre több processzort építettek egy rendszerbe, az UMA rendszerekben a memória-sávszélesség szűk keresztmetszetté vált. A NUMA ezt a problémát úgy oldja meg, hogy a memóriát elosztja a processzorok között, így minden processzornak van egy saját, lokális memóriája, amihez gyorsan hozzáférhet.
A NUMA lényege, hogy a processzoroknak lehetőségük van a lokális memóriájukhoz gyorsabban hozzáférni, mint a távoli memóriához, ezáltal csökkentve a memória-hozzáférési késleltetést és növelve a rendszer teljesítményét.
Amikor egy processzornak egy távoli memóriaterülethez kell hozzáférnie, azt a rendszer interconnect hálózaton keresztül teszi. Ez a távoli hozzáférés lassabb, mint a lokális, de még mindig hatékonyabb, mint az UMA rendszerekben a központi memória elérésének problémái nagyszámú processzor esetén. A NUMA architektúrák lehetővé teszik a skálázhatóságot, vagyis a rendszer teljesítményének növelését további processzorok és memória hozzáadásával.
A NUMA architektúra definíciója és alapelvei
A NUMA (Non-Uniform Memory Access) egy számítógép-architektúra, amelyben a memóriaelérés ideje a memória helyétől függően változik. Ez azt jelenti, hogy egy processzor gyorsabban éri el a hozzá közelebbi memóriát, mint a távolabbit.
A hagyományos, szimmetrikus multiprocesszoros (SMP) rendszerekben minden processzor egy közös memóriához fér hozzá, ami egységes memóriaelérést (UMA) biztosít. Ezzel szemben a NUMA rendszerekben a memóriát „csomópontokra” (nodes) osztják fel. Minden csomópont tartalmaz egy vagy több processzort, helyi memóriát és I/O eszközöket.
A processzorok a helyi memóriát gyorsabban érik el, mivel az közvetlenül a processzorhoz kapcsolódik. A távoli memória elérése lassabb, mivel az egy másik csomóponton található, és ehhez a csomópontok közötti összeköttetést kell használni.
A NUMA architektúra előnye a skálázhatóság. Az SMP rendszerekkel ellentétben, ahol a processzorok számának növelése a memóriabuszon torlódást okozhat, a NUMA rendszerekben a csomópontok hozzáadásával növelhető a teljesítmény anélkül, hogy a memóriaelérés sebessége jelentősen romlana.
A NUMA célja, hogy a processzorok a lehető legtöbb memóriahozzáférést helyi memóriából végezzék, minimalizálva a távoli memóriahozzáférések számát.
A NUMA rendszerekben a szoftvernek, különösen az operációs rendszernek, optimalizálnia kell a memóriafelhasználást, hogy a processzek a helyi memóriájukat használják. Ez a memóriatervezés (memory affinity) révén érhető el, amely lehetővé teszi, hogy a processzeket és a memóriát ugyanazon a csomóponton helyezzük el.
A NUMA architektúra bonyolultságot is hordoz magában. A szoftverfejlesztőknek figyelembe kell venniük a memóriaelérés eltérő sebességét a programjaik optimalizálásakor. A helytelen memóriakezelés jelentősen ronthatja a teljesítményt.
A NUMA rendszerek elterjedtek a nagy teljesítményű szerverekben és a szuperszámítógépekben, ahol a nagyméretű memória és a sok processzor együttes használata elengedhetetlen.
A NUMA kialakulásának történeti háttere és motivációi
A NUMA architektúra kialakulásának történeti háttere a szimmetrikus multiprocesszoros (SMP) rendszerek korlátaival függ össze. Az SMP rendszerekben több processzor osztozik egyetlen közös memóriaterületen, amit egyetlen sínrendszeren keresztül érnek el. Ez a megoldás kisebb processzorszám esetén jól működik, azonban ahogy a processzorok száma növekszik, a memóriabuszon jelentkező forgalom egyre nagyobb terhelést jelent, ami szűk keresztmetszetet okoz.
Ez a szűk keresztmetszet a memóriahozzáférés latenciájának növekedéséhez vezet, ami jelentősen befolyásolja a rendszer teljesítményét. A processzoroknak ugyanis egyre többet kell várakozniuk az adatokra, ami csökkenti a számítási kapacitás kihasználtságát. A probléma súlyosabbá válik a nagyméretű adatbázisok és a számításigényes alkalmazások esetében, ahol a gyakori memóriahozzáférés kritikus fontosságú.
A NUMA célja éppen az volt, hogy áthidalja ezt a problémát azáltal, hogy a memóriát lokális bankokra osztja, melyek közelebb helyezkednek el a processzorokhoz.
Az ötlet lényege, hogy minden processzornak vagy processzorcsoportnak (node) saját, helyi memóriája van. A processzorok elsősorban a saját helyi memóriájukat használják, ami gyorsabb hozzáférést biztosít. Amennyiben egy processzornak egy másik node memóriájában tárolt adatra van szüksége, akkor azt a rendszerszintű összeköttetésen keresztül éri el. Ez a távoli memóriahozzáférés lassabb, mint a helyi, de még mindig gyorsabb, mint egyetlen közös memória használata nagyszámú processzor esetén.
A NUMA architektúra tehát a lokalitás elvét használja ki. A processzorok többsége a saját helyi memóriájában tárolt adatokkal dolgozik, így minimalizálva a távoli memóriahozzáférések számát. Ez a megközelítés lehetővé teszi a skálázhatóbb és hatékonyabb rendszerek építését, ahol a teljesítmény nem korlátozódik a közös memória sávszélességére.
A NUMA rendszerek tervezése során kiemelt figyelmet kell fordítani az adatok elhelyezésére és a feladatok ütemezésére, hogy a processzorok minél gyakrabban a saját helyi memóriájukhoz férjenek hozzá. A megfelelő optimalizálással a NUMA rendszerek jelentős teljesítménynövekedést érhetnek el az SMP rendszerekhez képest, különösen nagyméretű, párhuzamos alkalmazások futtatásakor.
A hagyományos SMP (Szimmetrikus Multiprocessing) rendszerek korlátai és a NUMA előnyei
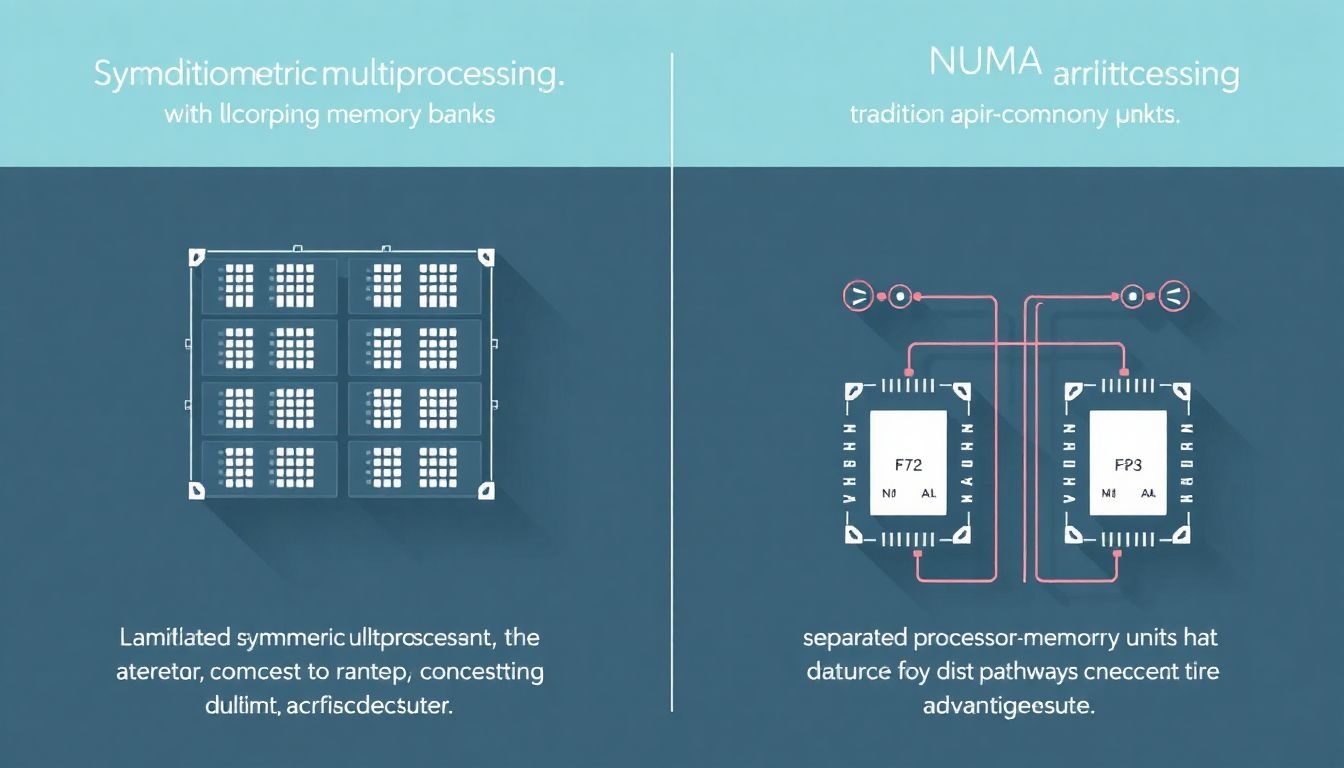
A hagyományos szimmetrikus multiprocesszoros (SMP) rendszerekben minden processzor egy közös memóriaterülethez fér hozzá, azonos késleltetéssel. Ez a megközelítés jól működik kisebb processzorszám esetén, azonban a processzorok számának növekedésével komoly problémák merülnek fel.
Az egyik legnagyobb korlát a memóriabusz szűk keresztmetszete. Minél több processzor próbál egyidejűleg a memóriához hozzáférni, annál nagyobb lesz a verseny, ami jelentősen lassítja a teljesítményt. Ezt a jelenséget memóriakonfliktusnak nevezzük. A processzorok várakozásra kényszerülnek, amíg a memóriához való hozzáférésük engedélyezésre kerül, ami pazarláshoz vezet.
Egy másik probléma a cache koherencia fenntartása. Az SMP rendszerekben minden processzor rendelkezik saját cache memóriával. Ha egy processzor módosít egy memóriacím tartalmát a saját cache-ében, a többi processzor cache-ében lévő másolatokat is frissíteni kell, hogy az adatok konzisztensek maradjanak. Ez a cache koherencia protokoll bonyolult és erőforrásigényes, és jelentősen növelheti a késleltetést a nagyobb rendszerekben.
A NUMA (Non-Uniform Memory Access) architektúra ezen korlátok leküzdésére lett kifejlesztve. A NUMA rendszerekben a memóriát csomópontokra osztják, amelyek mindegyike tartalmaz egy vagy több processzort és a hozzájuk tartozó helyi memóriát. A processzorok gyorsabban férnek hozzá a saját csomópontjuk memóriájához, mint a többi csomópont memóriájához. Ez a nem egységes memória-hozzáférés elvének alapja.
A NUMA lényege, hogy a processzorok a saját helyi memóriájukhoz gyorsabban férnek hozzá, mint a távoli memóriához, ezáltal csökkentve a memóriakonfliktusokat és javítva a teljesítményt.
A NUMA architektúra előnyei:
- Skálázhatóság: A NUMA rendszerek jobban skálázhatók, mint az SMP rendszerek, mivel a processzorok kevésbé versenyeznek a memóriához való hozzáférésért.
- Teljesítmény: A NUMA rendszerek magasabb teljesítményt nyújtanak, különösen olyan alkalmazások esetén, amelyek nagyméretű adathalmazokkal dolgoznak, és amelyek jól párhuzamosíthatók.
- Hatékonyság: A NUMA rendszerek energiahatékonyabbak lehetnek, mivel a processzorok kevésbé távoli memóriához férnek hozzá, ami kevesebb energiát igényel.
Természetesen a NUMA architektúra sem tökéletes. A programozók számára kihívást jelenthet a programok optimalizálása a NUMA rendszerekhez, hogy a processzorok a lehető legtöbbet használják a helyi memóriát. A távoli memória-hozzáférés továbbra is lassabb, mint a helyi, ezért a programoknak úgy kell működniük, hogy minimalizálják a távoli hozzáférések számát. A megfelelő NUMA-tudatos programozás elengedhetetlen a NUMA rendszerek előnyeinek kihasználásához.
A NUMA architektúra főbb komponensei: csomópontok, memóriavezérlők, összeköttetések
A NUMA (Non-Uniform Memory Access) architektúra lényege, hogy a processzorok különböző sebességgel érik el a rendszermemóriát, attól függően, hogy a memória „közel” vagy „távol” helyezkedik el a processzorhoz képest. Ez a megközelítés lehetővé teszi a nagyméretű, többprocesszoros rendszerek hatékonyabb működését.
A NUMA rendszerek alapvető építőkövei a csomópontok. Egy csomópont tipikusan tartalmaz egy vagy több processzort (CPU-t), a hozzájuk tartozó lokális memóriát és a memóriavezérlőt. A lokális memória elérése sokkal gyorsabb, mint a távoli csomópontokban található memória elérése.
A memóriavezérlők felelősek a memóriaelérések kezeléséért. Egy csomóponton belül a memóriavezérlő kezeli a CPU-k által a lokális memóriához intézett kéréseket. Ezenkívül a memóriavezérlők kommunikálnak más csomópontok memóriavezérlőivel, lehetővé téve a távoli memória elérését. A memóriavezérlők optimalizálják a memóriaeléréseket, például a gyakran használt adatokat a lokális memóriában tartva.
A csomópontok közötti kommunikációt a NUMA összeköttetések biztosítják. Ezek az összeköttetések nagy sebességű adatátvitelt tesznek lehetővé a csomópontok között. Az összeköttetések minősége és sebessége kritikus fontosságú a NUMA rendszer teljesítménye szempontjából. A távoli memória elérése mindig lassabb, mint a lokális memória elérése, de a jó minőségű összeköttetések minimalizálhatják ezt a késleltetést.
A NUMA architektúrák célja, hogy a legtöbb memóriaelérés lokálisan történjen, csökkentve a távoli memóriaelérések számát, és ezáltal javítva a rendszer teljesítményét.
A NUMA architektúrában a processzorok a hozzájuk legközelebb eső memóriához férnek hozzá a leggyorsabban. Ezáltal a rendszer hatékonyabban tudja kihasználni a párhuzamos feldolgozást. Az operációs rendszerek és az alkalmazások is optimalizálhatók a NUMA architektúrára, például azáltal, hogy a szálakat és a hozzájuk tartozó adatokat ugyanazon a csomóponton helyezik el.
Egy tipikus NUMA rendszerben a memóriaelérés ideje nem egységes. A lokális memóriaelérés gyors, míg a távoli memóriaelérés lassabb. Ezért fontos, hogy az alkalmazások és az operációs rendszer megfelelően kezeljék a memóriaeléréseket, hogy minimalizálják a távoli memóriaelérések számát.
A NUMA architektúra különösen előnyös olyan alkalmazások számára, amelyek nagy mennyiségű memóriát használnak és erősen párhuzamosak. Ilyen alkalmazások például a database szerverek, a tudományos számítások és a virtualizációs platformok.
A lokális és távoli memória fogalma a NUMA rendszerekben
A NUMA (Non-Uniform Memory Access) architektúrák lényege, hogy a memóriához való hozzáférési idő nem egységes. Ez azt jelenti, hogy egy processzor számára egyes memóriaterületek gyorsabban elérhetőek, mint mások. Ebből a szempontból válik kulcsfontosságúvá a lokális és távoli memória fogalma.
Lokális memória alatt azt a memóriát értjük, amely fizikailag közel helyezkedik el egy adott processzorhoz, jellemzően ugyanazon a csomóponton. A processzor közvetlenül, alacsony késleltetéssel és magas sávszélességgel éri el ezt a memóriát. Ez az ideális állapot a teljesítmény szempontjából, mivel a processzor gyorsan tud adatokat olvasni és írni.
A távoli memória ezzel szemben egy másik processzorhoz (csomóponthoz) tartozó memóriaterület. Ahhoz, hogy egy processzor hozzáférjen a távoli memóriához, kommunikálnia kell a másik processzorral és annak memóriavezérlőjével. Ez a kommunikáció többletköltséget jelent időben, tehát a távoli memória hozzáférése lassabb, nagyobb késleltetéssel és kisebb sávszélességgel történik, mint a lokális memória elérése.
A NUMA rendszerek teljesítményét nagymértékben befolyásolja, hogy az alkalmazások hogyan használják a memóriát. Az optimális működés érdekében törekedni kell arra, hogy a processzorok minél többször a lokális memóriájukat használják, minimalizálva a távoli memória hozzáféréseket.
A NUMA architektúrákban a memória-allokáció stratégia kritikus fontosságú. A modern operációs rendszerek és programozási könyvtárak rendelkeznek olyan mechanizmusokkal, amelyek lehetővé teszik a programozók számára, hogy befolyásolják a memória elhelyezését, így optimalizálva a teljesítményt. Például, egy többszálú alkalmazás esetében a szálakhoz tartozó adatok elhelyezhetők ugyanazon a csomóponton, ahol a szál fut, ezzel csökkentve a távoli memória hozzáférések számát.
A memória-hozzáférési latencia szerepe a teljesítményben
A NUMA architektúrákban a memória-hozzáférési latencia kritikus szerepet játszik a rendszer teljesítményében. Mivel a processzorok különböző távolságra lehetnek a memóriabankoktól, a memória-hozzáférés ideje jelentősen változhat.
Minél távolabb van egy processzor a memóriától, annál nagyobb a latencia, ami lassítja a programok végrehajtását.
Ezért a NUMA-ban futó alkalmazások teljesítménye nagymértékben függ attól, hogy az adatok hol helyezkednek el a memóriában. Az ideális az, ha a processzor a hozzá legközelebb eső memóriaterületen tárolt adatokkal dolgozik, ezt nevezzük lokális memória-hozzáférésnek. A távoli memória-hozzáférés, amikor a processzor más csomópont memóriájából olvas vagy oda ír, jóval lassabb.
A NUMA-tudatos programozás célja minimalizálni a távoli memória-hozzáféréseket, és optimalizálni a lokális hozzáféréseket. Ez gyakran speciális memóriakezelési technikákat igényel, mint például az adatok elhelyezése a megfelelő csomóponton, vagy a szálak affinitásának beállítása, hogy a megfelelő processzorokon fussanak.
A nem megfelelő memóriakezelés jelentős teljesítménycsökkenést eredményezhet NUMA rendszereken, akár többszörösét is az optimális esethez képest. Ezért a NUMA architektúrákban kulcsfontosságú a memória-hozzáférési latencia tudatos kezelése a maximális teljesítmény eléréséhez.
A NUMA rendszerek különböző típusai: CC-NUMA, NC-NUMA
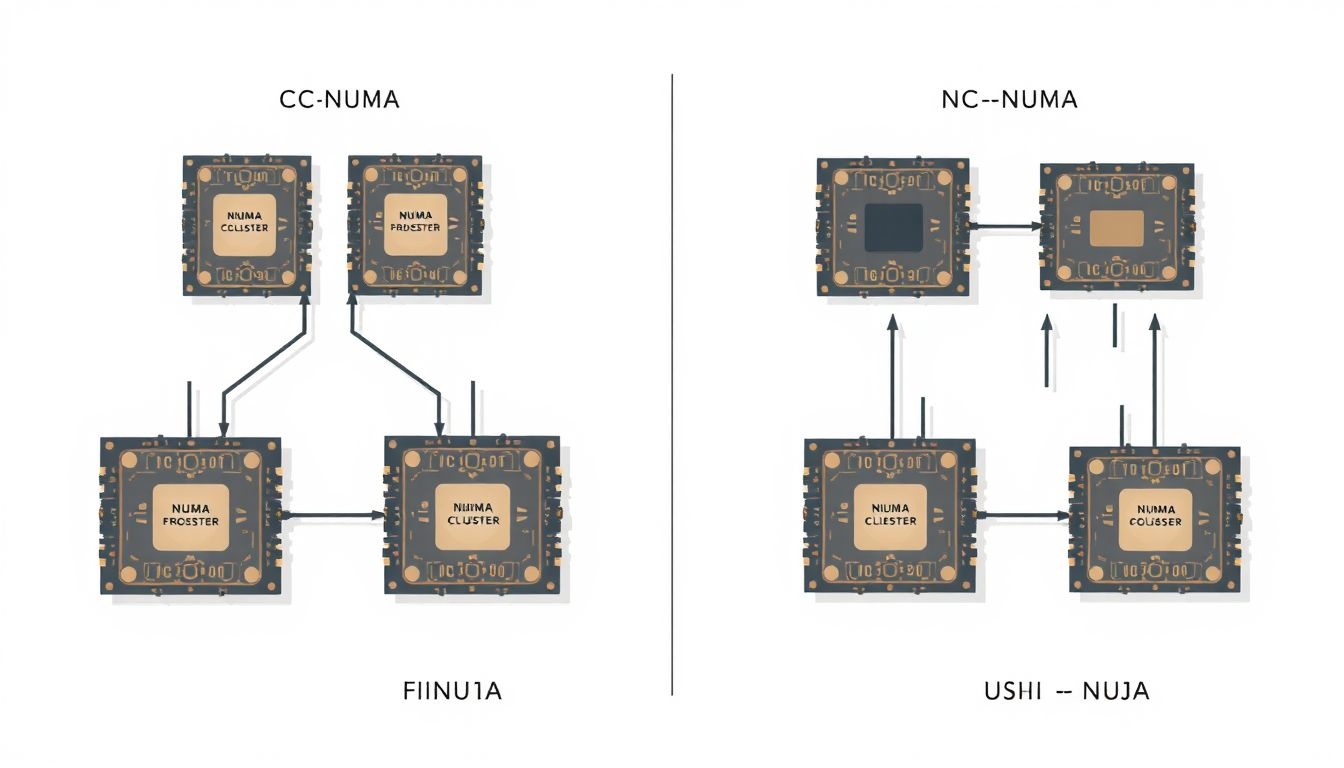
A NUMA architektúrák különböző implementációi léteznek, melyek közül a két legelterjedtebb a CC-NUMA (Cache Coherent NUMA) és az NC-NUMA (Non-Cache Coherent NUMA).
A CC-NUMA rendszerekben a processzorok a globális memóriaterülethez férnek hozzá, és a cache-koherencia biztosítja, hogy minden processzor a memóriában tárolt adatok legfrissebb verziójával dolgozzon. Ez azt jelenti, hogy ha egy processzor módosít egy memóriacímet, a többi processzor, amelynek cache-ében megtalálható az adott adat, értesítést kap, és a cache-ét frissíti vagy érvényteleníti.
A CC-NUMA előnye, hogy a programozók számára egy egységes memóriaterületet kínál, ami leegyszerűsíti a párhuzamos programok fejlesztését.
Ezzel szemben az NC-NUMA rendszerekben a cache-koherencia nem biztosított. Ez azt jelenti, hogy a processzoroknak explicit módon kell kezelniük a memóriában tárolt adatok frissességét, ami bonyolultabbá teszi a programozást. Az NC-NUMA rendszerek általában olcsóbbak, mint a CC-NUMA rendszerek, és bizonyos alkalmazásokban, ahol a memória-hozzáférés mintázata jól meghatározott, hatékonyabbak lehetnek.
A gyakorlatban a CC-NUMA elterjedtebb a szerverpiacon, mivel a cache-koherencia automatikus kezelése jelentősen csökkenti a szoftverfejlesztési erőfeszítéseket. Az NC-NUMA architektúrák ritkábbak, és speciális, nagy teljesítményű számítási feladatokra vannak optimalizálva, ahol a programozók képesek kézben tartani a memória-hozzáférést és a szinkronizációt.
A CC-NUMA (Cache Coherent NUMA) architektúra részletes leírása
A CC-NUMA (Cache Coherent Non-Uniform Memory Access) egy olyan számítógépes architektúra, amelyben a memória-hozzáférési idők nem egységesek. Ez azt jelenti, hogy a processzorok különböző idő alatt érik el a különböző memóriaterületeket. A „CC” a cache koherenciára utal, ami elengedhetetlen a hatékony működéshez.
A CC-NUMA rendszerek több csomópontból állnak. Minden csomópont tartalmaz egy vagy több processzort, valamint a hozzájuk tartozó helyi memóriát. A processzorok a helyi memóriát gyorsabban érik el, mint a távoli csomópontok memóriáját. Ez az eltérés a nem egységes memória-hozzáférés lényege.
A cache koherencia biztosítja, hogy a processzorok mindig a memória legfrissebb adataival dolgozzanak, még akkor is, ha az adatok több csomóponton is megtalálhatók a cache-ekben. A koherencia fenntartása komplex protokollok segítségével történik, amelyek figyelik a cache-ek állapotát és szinkronizálják azokat.
A CC-NUMA architektúra célja, hogy skálázható, nagy teljesítményű rendszereket hozzon létre úgy, hogy a processzorok a lehető legtöbb ideig a helyi memóriájukkal dolgozzanak, minimalizálva a távoli memória-hozzáférések számát.
A CC-NUMA rendszerekben a memória felosztása kulcsfontosságú a teljesítmény szempontjából. Az operációs rendszer és az alkalmazások igyekeznek az adatokat olyan helyre helyezni, ahol a hozzájuk leggyakrabban hozzáférő processzorok számára a lehető legközelebb legyenek.
A CC-NUMA architektúra előnyei közé tartozik a nagy skálázhatóság, a magas teljesítmény és a hatékony erőforrás-kihasználás. Hátrányai közé tartozik a komplex programozás és a helytelen memória-felosztásból adódó teljesítménycsökkenés.
A gyakorlati alkalmazások széles körűek, ideértve a nagy teljesítményű szervereket, a tudományos számításokat és a nagy adatbázis-rendszereket.
A cache koherencia protokollok szerepe a CC-NUMA rendszerekben
A CC-NUMA (Cache Coherent NUMA) rendszerek hatékony működésének kulcsa a cache koherencia protokollok megléte. Ezek a protokollok biztosítják, hogy a különböző processzorok gyorsítótáraiban tárolt adatok konzisztensek maradjanak, még akkor is, ha ugyanazt a memóriacímet használják.
A NUMA architektúrában a processzorokhoz közeli (lokális) memória-hozzáférés gyorsabb, mint a távoli memória elérése. Emiatt a processzorok igyekeznek a lokális memóriában tárolt adatokkal dolgozni. Ha egy processzor módosít egy adatot, ami egy másik processzor gyorsítótárában is megtalálható, a cache koherencia protokoll gondoskodik arról, hogy a többi processzor gyorsítótárában lévő másolat érvénytelenné váljon, vagy frissüljön.
A legelterjedtebb cache koherencia protokollok közé tartozik a snooping protokoll és a directory-based protokoll. A snooping protokollban minden gyorsítótár figyeli a memóriabusz forgalmát, és ha egy módosított adatot lát, akkor frissíti vagy érvényteleníti a saját másolatát. A directory-based protokollokban egy központi könyvtár tárolja az információt arról, hogy melyik gyorsítótárban található meg egy adott memóriablokk másolata. Amikor egy processzor módosítani akar egy adatot, a könyvtár értesíti a többi gyorsítótárat, hogy frissítsék vagy érvénytelenítsék a másolatukat.
A cache koherencia protokollok elengedhetetlenek a CC-NUMA rendszerek teljesítményének maximalizálásához, mivel lehetővé teszik a processzorok számára, hogy hatékonyan osszák meg az adatokat anélkül, hogy adatvesztés vagy inkonszisztencia lépne fel.
A protokollok összetettsége miatt a CC-NUMA rendszerek tervezése komoly kihívásokat jelent. A helytelenül implementált cache koherencia protokollok teljesítménycsökkenést és hibákat okozhatnak. A megfelelő protokoll kiválasztása és konfigurálása a rendszer specifikus igényeitől függ.
A szoftveres NUMA támogatás: operációs rendszerek és alkalmazások
A NUMA architektúra hatékony kihasználásához elengedhetetlen a szoftveres támogatás. Az operációs rendszerek és az alkalmazások feladata, hogy a NUMA topológiát felismerjék és optimalizálják a memóriakezelést és a szálütemezést.
Az operációs rendszerek NUMA támogatása általában a következőket foglalja magában:
- Memória-lokalitás: Az operációs rendszer igyekszik a szálak által használt memóriát ugyanabban a NUMA csomópontban allokálni, ahol a szál fut. Ez minimalizálja a távoli memória-hozzáférések számát.
- Szálütemezés: Az operációs rendszer úgy ütemezi a szálakat, hogy azok lehetőleg ugyanazon a NUMA csomóponton fussanak, ahol a memóriájuk található.
- NUMA-tudatos API-k: Az operációs rendszer olyan API-kat biztosít, amelyek lehetővé teszik az alkalmazások számára, hogy lekérdezzék a NUMA topológiát és optimalizálják a memóriakezelést.
A NUMA-tudatos alkalmazások képesek kihasználni a NUMA architektúra által kínált előnyöket, például a csökkentett memória-latenciát és a megnövelt sávszélességet.
Az alkalmazások szintjén a NUMA támogatás a következőket jelentheti:
- Adatstruktúrák elhelyezése: Az alkalmazás a kritikus adatstruktúrákat a megfelelő NUMA csomóponton helyezi el, ahol a hozzáférések gyakoriak.
- Szálak rögzítése: Az alkalmazás a szálakat meghatározott NUMA csomópontokhoz rögzíti, hogy a memória-lokalitás maximalizálva legyen.
- NUMA-tudatos algoritmusok: Az alkalmazás olyan algoritmusokat használ, amelyek figyelembe veszik a NUMA topológiát és minimalizálják a távoli memória-hozzáféréseket.
Például, egy adatbázis-kezelő rendszer (DBMS) a táblákat és indexeket a megfelelő NUMA csomópontokon tárolhatja, attól függően, hogy mely processzorok férnek hozzá leggyakrabban az adatokhoz. Egy másik példa lehet egy tudományos számítási alkalmazás, amely a nagy tömböket a NUMA csomópontok között osztja el, és a számításokat a megfelelő processzorokon végzi.
A modern programozási nyelvek és keretrendszerek gyakran biztosítanak eszközöket a NUMA támogatáshoz, megkönnyítve a fejlesztők számára a NUMA-tudatos alkalmazások írását. A megfelelő szoftveres támogatás kulcsfontosságú a NUMA architektúra teljes potenciáljának kiaknázásához.
A NUMA-tudatos programozás kihívásai és lehetőségei
A NUMA-tudatos programozás komoly kihívásokat tartogat, de jelentős teljesítménynövekedést is eredményezhet. A legfőbb probléma a memória-lokalitás kezelése. Ha egy szál olyan memóriához fér hozzá, amely egy távoli NUMA csomóponton helyezkedik el, az lényegesen lassabb, mintha a helyi memóriát használná.
Ezért a programozóknak tudatosan kell ügyelniük arra, hogy a szálak által használt adatok a lehető legközelebb legyenek a szálat futtató processzorhoz. Ez magában foglalhatja az adatok explicit elhelyezését a megfelelő memóriaterületen, vagy a szálak ütemezését úgy, hogy azok a megfelelő csomóponton futhassanak.
A kihívások ellenére a NUMA-tudatos programozás komoly előnyökkel járhat. A helyi memória használatával jelentősen csökkenthető a memória-hozzáférési késleltetés, ami a teljesítmény javulásához vezet. Ezenkívül a NUMA architektúrák lehetővé teszik a nagyobb memória-kapacitás kihasználását is, ami különösen fontos a nagyméretű adathalmazokkal dolgozó alkalmazások számára.
A NUMA-tudatos programozás kulcsa az adatok és a szálak közötti kapcsolat optimalizálása.
A NUMA-tudatos programozáshoz rendelkezésre állnak különböző eszközök és technikák. Operációs rendszerek és programozási nyelvek gyakran kínálnak API-kat, amelyek lehetővé teszik a memória-elhelyezés és a szálak ütemezésének finomhangolását. A profilozó eszközök segíthetnek azonosítani a teljesítmény szűk keresztmetszeteit, és meghatározni, hogy hol van szükség optimalizálásra. A megfelelő algoritmusok és adatszerkezetek kiválasztása szintén kritikus fontosságú lehet a NUMA-környezetekben.
A NUMA architektúra hatása az alkalmazások teljesítményére
A NUMA (Non-Uniform Memory Access) architektúra jelentős hatással van az alkalmazások teljesítményére, különösen a multiprocesszoros rendszerekben. A hagyományos SMP (Symmetric Multiprocessing) architektúrákkal szemben, ahol minden processzor egy közös memóriához egyenlő sebességgel fér hozzá, a NUMA rendszerekben a memória el van osztva, és minden processzornak van egy helyi memóriája, amihez gyorsabban fér hozzá, mint a távoli memóriához. Ez a különbség a hozzáférési időben alapvetően befolyásolja az alkalmazások viselkedését.
Az alkalmazások teljesítménye akkor a legjobb, ha a processzor a helyi memóriájából olvassa és írja az adatokat. Ha egy processzornak a távoli memóriához kell hozzáférnie, az jelentős teljesítménycsökkenést okozhat. Ezt a jelenséget „memóriatávoli hozzáférésnek” nevezzük. A memória távoli elérése lassabb, mivel az adatoknak a processzorok közötti összeköttetéseken kell áthaladniuk.
A NUMA architektúra hatékony kihasználása optimalizált alkalmazásokat igényel, amelyek minimalizálják a távoli memória-hozzáféréseket.
Ahhoz, hogy egy alkalmazás jól teljesítsen egy NUMA rendszeren, a fejlesztőknek figyelembe kell venniük a memória elrendezését. A következő stratégiák alkalmazhatók:
- Adatok lokalizálása: A leggyakrabban használt adatokat a processzorhoz legközelebbi memóriában kell tárolni, amely azokat feldolgozza.
- Szálak affinitása: A szálakat a megfelelő processzorokhoz kell rendelni, hogy minimalizálják a távoli memória-hozzáféréseket. Az operációs rendszerek gyakran biztosítanak eszközöket a szálak affinitásának beállításához.
- Memória allokáció optimalizálása: A memória allokációját a NUMA topológiához kell igazítani. A processzorokhoz közeli memóriaterületeket kell használni az adatok tárolására.
A nem megfelelően optimalizált alkalmazások esetében a NUMA architektúra akár negatív hatással is lehet a teljesítményre. Ha az alkalmazás sok távoli memória-hozzáférést generál, a kommunikációs többletterhelés jelentősen lelassíthatja a rendszert. Ezért a NUMA-tudatos programozás kulcsfontosságú a multiprocesszoros rendszerek maximális kihasználásához.
Ezenkívül, a NUMA rendszerekben a memória-sávszélesség is fontos szempont. A helyi memóriához való hozzáférés általában nagyobb sávszélességet biztosít, mint a távoli memóriához való hozzáférés. Ezért a sávszélesség-igényes alkalmazásoknak különösen előnyös lehet a helyi memória használata.
A NUMA rendszerek konfigurálása és optimalizálása
A NUMA rendszerek konfigurálása és optimalizálása kulcsfontosságú a teljesítmény maximalizálásához. A lényeg, hogy a memória-hozzáférést a processzorokhoz lokalizáljuk, elkerülve a távoli memória elérésének többletköltségeit.
A konfiguráció során figyelembe kell venni a processzorok és memóriamodulok elhelyezkedését. Ideális esetben a számítási feladatok úgy vannak ütemezve, hogy az adott processzorhoz legközelebb eső memóriát használják. Ezt a „local memory” elvnek nevezzük.
Az operációs rendszerek általában NUMA-tudatos ütemezőkkel rendelkeznek, amelyek igyekeznek a processzeket a megfelelő NUMA nóduszhoz rendelni. A felhasználó is befolyásolhatja ezt a folyamatot, például a numactl parancs segítségével Linux rendszereken.
A helytelen konfiguráció jelentős teljesítménycsökkenést eredményezhet, mivel a processzorok többet várakoznak a távoli memória elérésére.
Az optimalizálás során a következőket érdemes figyelembe venni:
- Adatlokalitás: A programokat úgy kell megírni, hogy az adatok hozzáférése lokalizált legyen az adott nóduszhoz.
- Processz affinitás: A processzeket a megfelelő NUMA nóduszhoz kell kötni.
- Memória affinitás: Az adatokat a megfelelő NUMA nódusz memóriájába kell allokálni.
Ezenkívül a VMware ESXi és más virtualizációs platformok is támogatják a NUMA-t. A virtuális gépeket úgy kell konfigurálni, hogy kihasználják a NUMA architektúra előnyeit. Például, egy nagyméretű virtuális gépet érdemes úgy elhelyezni, hogy egyetlen NUMA nóduszon belül maradjon, elkerülve a nóduszok közötti kommunikáció többletköltségét.
A profiling is fontos szerepet játszik az optimalizálásban. A megfelelő eszközökkel felmérhető, hogy mely processzek és adatok generálnak távoli memória-hozzáférést, és ez alapján lehet finomhangolni a konfigurációt és a kódot.
A processzor affinitás és a memória allokáció szerepe a NUMA optimalizálásban
A NUMA architektúrában a processzor affinitás kritikus szerepet játszik a teljesítmény optimalizálásában. A processzor affinitás azt jelenti, hogy egy adott processzort vagy processzorcsoportot preferálunk egy szál futtatására. Mivel a NUMA rendszerekben a processzorokhoz tartozó helyi memória gyorsabban elérhető, mint a távoli, a szálak helyi processzoron való futtatása csökkenti a memória-hozzáférési késleltetést.
A memória allokáció szintén kulcsfontosságú. Ha egy szál egy processzoron fut, ideális esetben a szál által használt memóriát is ugyanannak a processzornak a helyi memóriájában kell allokálni. Ez minimalizálja a távoli memória-hozzáféréseket. A modern operációs rendszerek és programozási nyelvek általában kínálnak eszközöket és API-kat a NUMA-tudatos memória allokációhoz.
A nem megfelelő processzor affinitás és memória allokáció súlyos teljesítményromláshoz vezethet NUMA rendszerekben, mivel a távoli memória-hozzáférések lassabbak, mint a helyiek.
Az optimalizáláshoz figyelembe kell venni a következőket:
- Processzor affinitás beállítása: Az operációs rendszer lehetővé teszi a szálak és folyamatok kötését adott processzorokhoz.
- NUMA-tudatos memória allokátorok használata: Ezek az allokátorok a memória helyi allokálására törekednek a futó szál processzorához.
- Adatok lokalizálása: Az adatok átrendezése, hogy azok a hozzájuk leggyakrabban hozzáférő processzorok közelében legyenek tárolva.
A hatékony NUMA optimalizálás a processzor affinitás és a memória allokáció együttes figyelembevételét igényli. A cél az, hogy a szálak a lehető legtöbb műveletet a helyi memóriájukkal végezzék el, minimalizálva a távoli memória-hozzáférések számát.
A teljesítmény monitorozása elengedhetetlen a NUMA optimalizálás hatékonyságának felméréséhez. A memória-hozzáférési minták elemzése segíthet azonosítani a szűk keresztmetszeteket és finomhangolni a processzor affinitást és a memória allokációt.
A NUMA rendszerek monitorozása és hibaelhárítása
A NUMA rendszerek monitorozása kritikus fontosságú a teljesítmény optimalizálása és a potenciális problémák feltárása szempontjából. A leggyakoribb probléma a memória-lokalitás figyelmen kívül hagyása, ami feleslegesen magas késleltetést eredményezhet, amikor egy processzor olyan memóriaterülethez fér hozzá, amely fizikailag egy másik NUMA node-on található.
A monitorozás során figyelni kell a következőkre:
- Processzorhasználat node-onként: Segít azonosítani, hogy egy adott node túlterhelt-e a többihez képest.
- Memóriahasználat node-onként: Kimutatja, ha egy node-on elfogy a memória, miközben a többi node-on van szabad kapacitás.
- Távoli memória-hozzáférések aránya: Magas érték esetén a memória-lokalitás optimalizálására van szükség.
A hibaelhárítás során a következő lépéseket érdemes megfontolni:
- A folyamatok affinitásának beállítása: A folyamatokat olyan processzorokhoz rendeljük, amelyek a hozzájuk tartozó memóriához a legközelebb vannak.
- Memória-allokációs szabályok optimalizálása: Bizonyos operációs rendszerek és programozási nyelvek lehetővé teszik a memória node-specifikus allokációját.
- Az alkalmazás architektúrájának felülvizsgálata: Ha az alkalmazás nagymértékben támaszkodik távoli memória-hozzáférésekre, érdemes lehet újratervezni a hatékonyabb adatkezelés érdekében.
A hatékony NUMA monitorozás és hibaelhárítás elengedhetetlen a rendszer teljesítményének maximalizálásához és a potenciális szűk keresztmetszetek elkerüléséhez.
Számos eszköz áll rendelkezésre a NUMA rendszerek monitorozásához, beleértve az operációs rendszer beépített eszközeit (pl. numastat Linuxon) és a harmadik féltől származó teljesítményfigyelő szoftvereket. A megfelelő eszközök kiválasztása a rendszer specifikus igényeitől függ.
A NUMA architektúra alkalmazási területei: szerverek, adatbázisok, HPC
A NUMA architektúra széles körben alkalmazott a modern számítástechnikában, különösen ott, ahol a teljesítmény és a skálázhatóság kritikus fontosságú. Három fő terület emelkedik ki:
- Szerverek: A NUMA architektúra ideális a nagy terhelésű szerverek számára. Ezek a szerverek gyakran több processzorral rendelkeznek, és a NUMA lehetővé teszi, hogy minden processzor a hozzá legközelebb eső memóriához férjen hozzá a leggyorsabban. Ez minimalizálja a késleltetést és növeli a teljesítményt, különösen olyan alkalmazásoknál, amelyek erősen támaszkodnak a memóriára.
- Adatbázisok: Az adatbázis-kezelő rendszerek (DBMS) óriási mennyiségű adatot kezelnek, és a gyors adathozzáférés elengedhetetlen a hatékony működéshez. A NUMA architektúra lehetővé teszi az adatbázisok számára, hogy kihasználják a helyi memória előnyeit, csökkentve a memória-hozzáférési ütközéseket és javítva a lekérdezések sebességét. A nagy tranzakciós terhelésű rendszerek különösen profitálnak a NUMA által kínált alacsonyabb késleltetésből.
- HPC (High-Performance Computing): A tudományos számítások, szimulációk és más HPC alkalmazások rendkívül nagy számítási teljesítményt igényelnek. A NUMA lehetővé teszi a HPC rendszerek számára, hogy skálázhatóbbak és hatékonyabbak legyenek, mivel a processzorok párhuzamosan dolgozhatnak a helyi memóriájukon, minimalizálva a kommunikációs költségeket.
A NUMA architektúra előnyei különösen akkor nyilvánvalóak, amikor a feladatok párhuzamosíthatóak. Ebben az esetben az egyes processzorok a hozzájuk rendelt memóriaterületeken dolgozhatnak anélkül, hogy állandóan más processzorokkal kellene kommunikálniuk. Ezáltal a rendszer hatékonyabban tudja kihasználni a rendelkezésre álló erőforrásokat.
A NUMA architektúra a teljesítménykritikus alkalmazások számára kínál optimális megoldást a memória-hozzáférés kezelésére és a skálázhatóság növelésére.
A NUMA architektúrák implementációja során figyelembe kell venni a memória-lokalitás kérdését. Az alkalmazásoknak optimalizálniuk kell a memóriahasználatukat annak érdekében, hogy a lehető legtöbb adatot a helyi memóriában tárolják. Ez javíthatja a teljesítményt, mivel a helyi memória-hozzáférés sokkal gyorsabb, mint a távoli memória-hozzáférés.
A NUMA architektúra jövőbeli trendjei és fejlesztési irányai
A NUMA architektúra jövője szorosan összefonódik a növekvő számítási igényekkel és a nagy adathalmazok kezelésével kapcsolatos kihívásokkal. A fejlesztési irányok főként a memória-hozzáférés optimalizálására, a skálázhatóság növelésére és a programozási modell egyszerűsítésére összpontosítanak.
Az egyik legfontosabb trend a NUMA-aware alkalmazások elterjedése. A programozók egyre inkább tisztában vannak a NUMA architektúra sajátosságaival, és igyekeznek olyan alkalmazásokat fejleszteni, amelyek kihasználják a lokális memória előnyeit és minimalizálják a távoli memória-hozzáférést. Ez magában foglalja a folyamatok és szálak megfelelő ütemezését, valamint az adatok optimális elosztását a memóriában.
A jövőben várható a memóriatechnológiák fejlődése is, ami közvetlen hatással lesz a NUMA rendszerek teljesítményére. Az új generációs memóriák, mint például a memristor alapú megoldások, nagyobb sűrűséget, alacsonyabb késleltetést és kisebb energiafogyasztást ígérnek, ami jelentősen javíthatja a NUMA rendszerek hatékonyságát.
A NUMA architektúrák fejlesztésének egyik kulcseleme a hardveres és szoftveres megoldások közötti szinergia megteremtése.
További fejlesztési irány a NUMA rendszerek virtualizációjának tökéletesítése. A virtualizációs technológiák lehetővé teszik, hogy egy fizikai NUMA rendszeren több virtuális gép (VM) fusson, amelyek mindegyike saját, elkülönített memória-területtel rendelkezik. A NUMA-aware virtualizáció biztosítja, hogy a VM-ek a lehető legközelebb helyezkedjenek el a hozzájuk tartozó memóriához, minimalizálva ezzel a távoli memória-hozzáférést.
Végül, de nem utolsósorban, a NUMA rendszerek programozásának egyszerűsítése is fontos célkitűzés. A jelenlegi NUMA programozási modellek gyakran bonyolultak és nehezen kezelhetők. Az új programozási nyelvek és keretrendszerek célja, hogy absztrahálják a NUMA architektúra komplexitását és megkönnyítsék a NUMA-aware alkalmazások fejlesztését.