

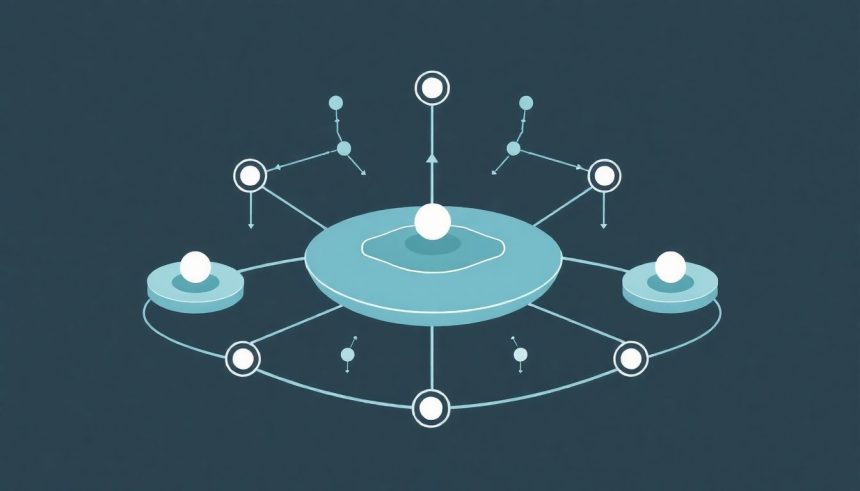
A modern digitális gazdaságban az adat az új olaj, de ez az „olaj” ma már nem statikus tárolókban pihen, hanem folyamatosan áramlik. A streaming adatarchitektúra az a komplex rendszer, amely lehetővé teszi számunkra, hogy valós időben gyűjtsük, dolgozzuk fel és elemezzük ezeket a folyamatosan érkező adatfolyamokat. Gondoljunk csak a közösségi média hírfolyamokra, az online banki tranzakciókra, az IoT eszközök szenzoradataira vagy akár a weboldalak látogatói interakcióira. Mindezek az események egy pillanat alatt generálódnak, és azonnali reakciót igényelhetnek. Egy jól megtervezett streaming architektúra képes kezelni ezt a hatalmas sebességű és volumenű adatözönt, biztosítva az üzleti folyamatok agilitását és a gyors döntéshozatalt.
A streaming architektúrák célja, hogy az adatok feldolgozása ne kötegelt (batch) módon, előre meghatározott időközönként történjen, hanem folyamatosan, ahogy az adatok beérkeznek. Ez a megközelítés gyökeresen átalakítja az üzleti intelligencia, az operációs rendszerek és a felhasználói élmény terén elérhető lehetőségeket. Képzeljük el, hogy egy online áruházban azonnal értesülünk a raktárkészlet változásairól, vagy egy banki rendszer valós időben azonosítja a potenciális csalásokat. Ezek a forgatókönyvek mind a robusztus és skálázható streaming adatarchitektúra alapjain nyugszanak.
A streaming adatarchitektúra alapvető komponensei
Egy tipikus streaming adatarchitektúra több, egymással szorosan összefüggő komponensből épül fel, amelyek mindegyike specifikus szerepet tölt be az adatok életciklusában. Ezek a komponensek együttesen biztosítják az adatok zökkenőmentes áramlását az adatforrástól a fogyasztóig, miközben garantálják a megbízhatóságot, a skálázhatóságot és az alacsony késleltetést.
Adatforrások: az adatfolyamok eredete
Az adatforrások azok a pontok, ahol az adatok keletkeznek. Ezek rendkívül sokfélék lehetnek, és a streaming architektúra sikeréhez elengedhetetlen a különböző típusú forrásokból származó adatok hatékony kezelése. Példaként említhetjük az IoT eszközöket (szenzorok, okosotthoni berendezések, ipari gépek), amelyek folyamatosan küldenek telemetriai adatokat. A webes alkalmazások és mobil appok felhasználói interakciói (kattintások, keresések, kosárba helyezések) szintén gazdag adatfolyamokat generálnak. A log fájlok, amelyek szerverek, alkalmazások és hálózati eszközök működéséről adnak információt, kritikus forrásai lehetnek a rendszerállapot-elemzésnek. Végül, de nem utolsósorban, a relációs adatbázisok változásai (Change Data Capture – CDC) is valós időben feldolgozhatók, lehetővé téve a tranzakciók nyomon követését és a replikációt.
Adatgyűjtés és ingesztálás: az adatok beáramlása
Az adatgyűjtés és ingesztálás a streaming architektúra első kritikus lépése, amelynek során az adatok bekerülnek a rendszerbe. Ennek a fázisnak a feladata, hogy nagy mennyiségű, változatos formátumú adatot fogadjon, puffereljen és megbízhatóan továbbítson a következő feldolgozási lépések felé. A leggyakrabban használt technológiák ebben a szakaszban a üzenetsorok (message queues) és a elosztott naplózási rendszerek (distributed log systems). Az Apache Kafka az egyik legnépszerűbb választás, amely rendkívül skálázható, hibatűrő és nagy átviteli sebességet biztosít. Más megoldások közé tartozik az Amazon Kinesis, a Google Cloud Pub/Sub vagy a RabbitMQ. Ezek a rendszerek biztosítják, hogy az adatok ne vesszenek el, még akkor sem, ha a fogyasztó rendszerek átmenetileg nem elérhetők, és lehetővé teszik több fogyasztó számára ugyanazon adatfolyam feldolgozását.
Adatfolyam feldolgozás: az adatok értelmezése valós időben
Az adatfolyam feldolgozás (stream processing) a streaming architektúra szíve. Itt történik az adatok valós idejű elemzése, transzformációja és aggregálása. A feldolgozás történhet egyszerű szűréstől és átalakítástól kezdve egészen a komplex eseményfeldolgozásig (Complex Event Processing – CEP) vagy gépi tanulási modellek futtatásáig. A feldolgozó motoroknak képesnek kell lenniük az adatok rendkívül alacsony késleltetéssel történő kezelésére, miközben garantálják a konzisztenciát és a hibatűrést. Néhány vezető technológia ezen a területen az Apache Flink, amely valós idejű, állapotfüggő számításokat tesz lehetővé, az Apache Spark Streaming, amely mikro-kötegelt feldolgozással szimulálja a streaminget, valamint az Apache Storm és az Apache Samza. Ezek a rendszerek gyakran támogatják az ablakos (windowed) számításokat, ahol az adatok egy bizonyos időablakon belül kerülnek feldolgozásra (pl. az utolsó 5 percben beérkezett adatok átlaga).
A valós idejű adatfeldolgozás képessége alapvető paradigmaváltást hozott, lehetővé téve az azonnali reakciót az üzleti eseményekre és az adatokban rejlő értékek azonnali kiaknázását.
Adattárolás: az adatok perzisztenciája és hozzáférhetősége
A streaming architektúrában az adattárolás szerepe kettős. Egyrészt szükség van egy perzisztens tárolóra az ingesztált, nyers adatok számára (gyakran egy adat tó, azaz data lake formájában, ahol az adatok strukturálatlanul vagy félig strukturáltan tárolódnak). Másrészt a feldolgozott adatoknak is szükségük van egy tárolási helyre, ahonnan az alkalmazások könnyen és gyorsan hozzáférhetnek. Ez utóbbi célra gyakran használnak NoSQL adatbázisokat (például Apache Cassandra, MongoDB, Redis, Elasticsearch), amelyek nagy sebességű írási és olvasási műveleteket tesznek lehetővé, és jól skálázhatók. A kiválasztott tárolási megoldásnak támogatnia kell a nagy adatmennyiséget és az alacsony késleltetést, hogy a fogyasztó alkalmazások valós időben tudjanak reagálni a friss adatokra.
Adatfogyasztók és alkalmazások: az érték kiaknázása
Az adatfogyasztók és alkalmazások jelentik a streaming architektúra végét, ahol az adatokból végül üzleti érték születik. Ezek az alkalmazások a feldolgozott adatfolyamokból táplálkoznak, és a legkülönfélébb célokat szolgálhatják. Ide tartoznak a valós idejű dashboardok és vizualizációk, amelyek azonnali betekintést nyújtanak az üzleti folyamatokba és a rendszerállapotba. A gépi tanulási modellek folyamatosan frissített adatokkal táplálhatók a prediktív analitikához vagy az anomáliafelismeréshez. Az automatizált riasztási rendszerek azonnal értesítést küldenek, ha bizonyos feltételek teljesülnek (pl. rendszerhiba, szokatlan aktivitás). Végül, a mikroszolgáltatások és más üzleti alkalmazások is felhasználhatják a valós idejű adatokat a felhasználói élmény személyre szabásához, a döntéshozatal támogatásához vagy az operatív folyamatok optimalizálásához.
Kulcsfontosságú tervezési elvek a streaming adatarchitektúrában
Egy hatékony streaming adatarchitektúra megtervezése számos alapvető elv figyelembevételét igényli. Ezek az elvek biztosítják, hogy a rendszer ne csak működőképes, hanem robusztus, megbízható és fenntartható is legyen a hosszú távon.
Skálázhatóság: a növekvő adatmennyiség kezelése
A skálázhatóság az egyik legfontosabb szempont, hiszen a streaming rendszereknek gyakran kell hatalmas és változó adatmennyiséget kezelniük. Egy jól skálázható architektúra képes lesz az adatforgalom növekedésével együtt bővülni anélkül, hogy a teljesítménye jelentősen romlana. Ez magában foglalja a horizontális skálázhatóságot, ahol további erőforrások (szerverek, konténerek) adhatók a rendszerhez, valamint a komponensek független skálázhatóságát. Például az üzenetsorok, mint az Apache Kafka, elosztott architektúrájuknak köszönhetően könnyen skálázhatók, ahogy az adatfolyam-feldolgozó motorok is, mint az Apache Flink, amelyek képesek párhuzamosan feldolgozni az adatokat több csomóponton.
Hibatűrés és megbízhatóság: az adatok biztonsága
A hibatűrés (fault tolerance) garantálja, hogy a rendszer képes legyen tovább működni, még akkor is, ha egyes komponensek meghibásodnak. Ez kritikus fontosságú az adatok integritásának és a szolgáltatás folyamatosságának biztosításában. A streaming rendszerek gyakran használnak redundáns tárolást, replikációt és automatikus feladatátvételt (failover) a hibatűrés eléréséhez. Az üzenetsorok például replikálják az adatokat több szerveren, így ha az egyik meghibásodik, az adatok nem vesznek el. Az adatfolyam-feldolgozó motorok képesek a feldolgozási állapotot (state) perzisztensen tárolni, így egy hiba után onnan folytatható a feldolgozás, ahol az megszakadt. A véglegesen pontos (exactly-once) feldolgozás egy ideális, de nehezen elérhető cél, amely azt jelenti, hogy minden adatrekordot pontosan egyszer dolgoznak fel, elkerülve a duplikációkat vagy az adatok elvesztését.
Alacsony késleltetés: az azonnali reakció képessége
Az alacsony késleltetés (low latency) a streaming rendszerek egyik legfőbb előnye és egyben kihívása. Az adatoknak a lehető leggyorsabban kell áthaladniuk a rendszeren, hogy az üzleti döntések vagy a felhasználói interakciók valós időben történhessenek. Ez megköveteli a komponensek optimalizálását, a felesleges lépések elhagyását és a hatékony adatátviteli mechanizmusok alkalmazását. A mikro-kötegelt feldolgozás (mint a Spark Streamingben) bár alacsony késleltetést biztosít, de nem igazi valós idejű, míg a valódi eseményenkénti feldolgozás (mint a Flinkben) sokkal alacsonyabb késleltetést kínál. A hálózati késleltetés minimalizálása, a gyors tárolási megoldások és az optimalizált feldolgozási algoritmusok mind hozzájárulnak az alacsony késleltetés eléréséhez.
Adatkonzisztencia: a megbízható eredmények biztosítása
Az adatkonzisztencia azt jelenti, hogy a rendszer által szolgáltatott adatok pontosak és megbízhatóak. A streaming környezetben ez különösen nagy kihívást jelenthet, mivel az adatok folyamatosan változnak és érkeznek. Különbséget tehetünk a gyenge (eventual) konzisztencia és az erős (strong) konzisztencia között. A legtöbb streaming architektúra a gyenge konzisztenciára törekszik, ahol az adatok egy idő után válnak konzisztenssé az elosztott rendszerben. Azonban bizonyos üzleti logikák megkövetelhetik az erősebb konzisztenciát, ami kompromisszumokkal járhat a késleltetés és a skálázhatóság terén. A feldolgozási garanciák (at-most-once, at-least-once, exactly-once) kiválasztása kulcsfontosságú a konzisztencia és a megbízhatóság eléréséhez.
Monitorozás és menedzsment: a rendszer egészségének fenntartása
Egy komplex streaming architektúra megfelelő működéséhez elengedhetetlen a folyamatos monitorozás és menedzsment. Ez magában foglalja a rendszer komponenseinek (üzenetsorok, feldolgozó motorok, adatbázisok) teljesítményének, erőforrás-kihasználtságának és hibáinak nyomon követését. A metrikák (átviteli sebesség, késleltetés, hibaarány) gyűjtése, a logok elemzése és a riasztási rendszerek beállítása lehetővé teszi a problémák gyors azonosítását és elhárítását. A modern felhőplatformok (AWS CloudWatch, Google Cloud Monitoring, Azure Monitor) integrált megoldásokat kínálnak ehhez, de nyílt forráskódú eszközök (Prometheus, Grafana, ELK stack) is széles körben alkalmazhatók. A proaktív monitorozás segít megelőzni a nagyobb leállásokat és biztosítja a rendszer optimális működését.
Gyakori architektúra minták a streaming rendszerekben
A streaming adatarchitektúrák tervezésekor számos bevált mintát alkalmazhatunk, amelyek segítenek a komplexitás kezelésében és a különböző üzleti igények kielégítésében. A két leggyakoribb és legbefolyásosabb minta a Lambda és a Kappa architektúra.
Lambda architektúra: a batch és a stream ötvözete
A Lambda architektúra egy hagyományos megközelítés, amely a batch feldolgozás és a stream feldolgozás előnyeit ötvözi. Három rétegből áll: a batch rétegből, a speed rétegből és a serving rétegből. A batch réteg felelős a nagy mennyiségű, történelmi adatok feldolgozásáért, jellemzően naponta vagy óránként futó kötegelt feladatokkal. Ez a réteg garantálja a magas pontosságot és a konzisztenciát, mivel elegendő ideje van az adatok alapos feldolgozására és az esetleges hibák korrigálására. Gyakran használ olyan eszközöket, mint az Apache Hadoop vagy az Apache Spark.
A speed réteg (vagy valós idejű réteg) feladata, hogy az új, beérkező adatokat valós időben feldolgozza, alacsony késleltetéssel. Ez a réteg adja az azonnali betekintést, de a feldolgozása lehet kevésbé pontos, mint a batch rétegé, mivel a gyorsaságra fókuszál. Itt tipikusan Apache Kafka, Apache Storm, Apache Flink vagy Spark Streaming technológiák kapnak szerepet. A speed réteg eredményei ideiglenesek, és a batch réteg eredményei végül felülírják vagy kiegészítik őket.
A serving réteg (szolgáltató réteg) egyesíti a batch és a speed réteg eredményeit, és egyetlen, lekérdezhető nézetet biztosít az adatokról az alkalmazások számára. Ez a réteg gyakran használ NoSQL adatbázisokat, mint például az Apache Cassandra vagy az Elasticsearch, amelyek gyors lekérdezési sebességet biztosítanak. A Lambda architektúra előnye a magas megbízhatóság és az adatok teljes körű történelmi elemzésének lehetősége, hátránya viszont a komplexitás és a két különböző feldolgozási logikát igénylő karbantartás.
Kappa architektúra: a tiszta stream megközelítés
A Kappa architektúra egy egyszerűsített megközelítés, amelyet Jay Kreps (Kafka társalapítója) javasolt, válaszul a Lambda architektúra komplexitására. Ebben a mintában minden adat egyetlen, elosztott, perzisztens logba (például Apache Kafka) kerül, és kizárólag stream feldolgozással történik a feldolgozása. Nincs külön batch réteg; a történelmi adatok újrafeldolgozása is az adatfolyam-feldolgozó motor segítségével történik, egyszerűen azzal, hogy a log elejétől újraolvassák az adatokat.
Ez a megközelítés jelentősen csökkenti a rendszer komplexitását, mivel csak egyetlen kódalapot kell karbantartani a feldolgozási logikához. Az adatok konzisztenciája és a hibatűrés is egyszerűbbé válik. A Kappa architektúra különösen jól illeszkedik azokhoz az esetekhez, ahol az adatok forrása alapvetően egy log-szerű adatfolyam (pl. események, logok, IoT szenzoradatok). Azonban hátránya lehet, hogy a nagyon nagy történelmi adatok újrafeldolgozása időigényes lehet, és a stream feldolgozó motornak képesnek kell lennie a nagy mennyiségű adat hatékony kezelésére. Az Apache Flink és az Apache Spark Streaming a Kappa architektúra népszerű megvalósítási eszközei.
Valós idejű adatfolyam-feldolgozás serverless környezetben
A serverless (szerver nélküli) megközelítés egyre népszerűbbé válik a streaming architektúrákban is. Ebben az esetben a fejlesztőknek nem kell szervereket provisioningolniuk, konfigurálniuk vagy menedzselniük. A felhőszolgáltatók (AWS Lambda, Google Cloud Functions, Azure Functions) automatikusan skálázzák az erőforrásokat a beérkező adatfolyamokhoz igazodva, és csak a ténylegesen felhasznált számítási időért kell fizetni. Ez a modell kiválóan alkalmas az eseményvezérelt architektúrákhoz, ahol az egyes adatpontok vagy mikro-kötegek eseményként indítanak el egy-egy feldolgozó függvényt.
Például egy AWS környezetben az Amazon Kinesis Data Streams szolgáltatás fogadja az adatokat, majd ezek az adatok egy AWS Lambda függvényt triggerelnek, amely elvégzi a szükséges transzformációt és egy Amazon DynamoDB adatbázisba vagy S3 tárolóba írja az eredményeket. Ez a megközelítés rendkívül költséghatékony lehet alacsony és változó terhelés esetén, és nagymértékben leegyszerűsíti az üzemeltetést. Azonban a serverless funkciók korlátozott futásideje és az állapotkezelés kihívásai miatt komplex, állapotfüggő stream feldolgozásra kevésbé ideális, mint a dedikált stream feldolgozó motorok.
Eszközök és technológiák a streaming adatarchitektúrában

A streaming adatarchitektúra megvalósításához számos nyílt forráskódú és kereskedelmi eszköz, valamint felhőszolgáltatás áll rendelkezésre. A megfelelő technológiai stack kiválasztása nagyban függ a projekt specifikus igényeitől, a skálázhatósági követelményektől, a késleltetési céloktól és a költségvetéstől.
Üzenetsorok és adatfolyam-platformok
- Apache Kafka: Az ipari szabvány a elosztott, perzisztens üzenetsorok és esemény streaming platformok között. Kiválóan skálázható, hibatűrő és nagy átviteli sebességet biztosít, ideális az adatgyűjtéshez és az adatok megbízható továbbításához.
- Amazon Kinesis: Az AWS felhőplatform streaming szolgáltatásainak családja, amely magában foglalja a Kinesis Data Streams-et (valós idejű adatfolyamokhoz), a Kinesis Firehose-t (adattárolókba történő egyszerű betöltéshez) és a Kinesis Data Analytics-et (valós idejű elemzéshez).
- Google Cloud Pub/Sub: Egy globálisan elosztott üzenetküldő szolgáltatás a Google Cloud platformon, amely aszinkron és skálázható üzenetátvitelt biztosít a szolgáltatások között.
- RabbitMQ: Egy nyílt forráskódú üzenet bróker, amely támogatja a különböző üzenetküldő protokollokat és rugalmas útválasztási lehetőségeket kínál, bár nagy volumenű, perzisztens streaminghez kevésbé optimalizált, mint a Kafka.
Adatfolyam feldolgozó motorok
- Apache Flink: Egy nyílt forráskódú, elosztott valós idejű adatfolyam feldolgozó motor, amely képes állapotfüggő számításokat végezni rendkívül alacsony késleltetéssel és véglegesen pontos (exactly-once) garanciákkal. Kiválóan alkalmas komplex eseményfeldolgozáshoz és állapotkezelést igénylő feladatokhoz.
- Apache Spark Streaming: Az Apache Spark elosztott feldolgozó keretrendszer kiterjesztése, amely mikro-kötegelt feldolgozással szimulálja a streaminget. Nagyobb késleltetésű, mint a Flink, de jól integrálódik a Spark ökoszisztémával és a meglévő Spark batch feladatokkal.
- Apache Storm: Az egyik első valós idejű stream feldolgozó rendszer, amely garantálja az adatok feldolgozását (at-least-once). Bár még használják, a Flink és a Spark Streaming általában modernebb és rugalmasabb megoldásokat kínálnak.
- Google Cloud Dataflow / Apache Beam: A Google Cloud Dataflow egy menedzselt szolgáltatás az Apache Beam SDK-ra épülve, amely egyesíti a batch és stream feldolgozást egyetlen programozási modellel. Lehetővé teszi a hordozható, elosztott adatfeldolgozó pipeline-ok építését.
Adattárolási megoldások streaminghez
- Apache Cassandra: Egy elosztott, oszloporientált NoSQL adatbázis, amely rendkívül skálázható és nagy sebességű írási műveleteket tesz lehetővé, ideális a stream feldolgozott eredmények tárolására.
- MongoDB: Egy dokumentumorientált NoSQL adatbázis, amely rugalmas sémát és skálázható architektúrát kínál, gyakran használják az adatok gyors tárolására és lekérdezésére.
- Redis: Egy memóriabeli kulcs-érték adatbázis és adatstruktúra-szerver, amely rendkívül gyors hozzáférést biztosít az adatokhoz, ideális gyorsítótárazáshoz vagy valós idejű aggregációk tárolására.
- Elasticsearch: Egy elosztott, RESTful kereső- és analitikai motor, amelyet gyakran használnak log adatok, események és egyéb idősoros adatok valós idejű indexelésére és lekérdezésére.
- Adat tavak (Data Lake): Például az Amazon S3, Google Cloud Storage vagy Azure Data Lake Storage. Ezek a tárolók lehetővé teszik a nyers, strukturálatlan vagy félig strukturált adatok tárolását rendkívül költséghatékony módon, későbbi elemzés céljából.
Gyakori felhasználási esetek a streaming adatarchitektúrában
A streaming adatarchitektúrák rendkívül sokoldalúak, és számos iparágban forradalmasítják az adatkezelést és az üzleti folyamatokat. Néhány kiemelt felhasználási eset:
Valós idejű analitika és riportolás
A vállalatok számára kritikus fontosságú, hogy azonnal hozzáférjenek a legfrissebb üzleti adatokhoz. A streaming architektúrák lehetővé teszik a valós idejű dashboardok és riportok készítését, amelyek azonnali betekintést nyújtanak az értékesítési trendekbe, a weboldal forgalmába, a marketingkampányok teljesítményébe vagy a gyártási folyamatokba. Ezáltal a vezetők és az operatív csapatok gyorsabban hozhatnak megalapozott döntéseket, és azonnal reagálhatnak a piaci változásokra.
Anomaly Detection és csalásfelismerés
A pénzügyi szektorban, az e-kereskedelemben és a kiberbiztonságban az anomáliafelismerés és a csalásfelismerés alapvető fontosságú. A streaming rendszerek képesek valós időben elemezni a tranzakciókat, felhasználói viselkedéseket vagy hálózati forgalmat, és azonnal azonosítani a szokatlan mintázatokat, amelyek csalásra vagy biztonsági fenyegetésre utalhatnak. Ez lehetővé teszi a gyors beavatkozást, minimalizálva a károkat.
Személyre szabott ajánlások és felhasználói élmény
Az online platformok (streaming szolgáltatók, e-kereskedelmi oldalak, közösségi média) folyamatosan gyűjtik a felhasználói interakciókat. A streaming architektúra segítségével ezeket az adatokat valós időben lehet feldolgozni, és azonnal frissíteni a személyre szabott ajánlásokat, hírfolyamokat vagy hirdetéseket. Ez jelentősen javítja a felhasználói élményt és növeli az elkötelezettséget.
IoT adatfeldolgozás és ipari automatizálás
Az Internet of Things (IoT) eszközök milliárdjai generálnak folyamatosan adatokat. A streaming architektúrák ideálisak ezen adatok gyűjtésére, feldolgozására és elemzésére. Legyen szó okosvárosok szenzoradatairól, ipari gépek telemetriájáról vagy egészségügyi viselhető eszközökről, a valós idejű feldolgozás lehetővé teszi a proaktív karbantartást, az energiahatékonyság optimalizálását és az automatizált vezérlést.
Log és eseménykezelés
A szerverek, alkalmazások és hálózati eszközök által generált log adatok hatalmas mennyiségben keletkeznek. A streaming architektúrák segítségével ezeket a logokat valós időben lehet gyűjteni, aggregálni és elemezni. Ez kritikus fontosságú a rendszerhibák diagnosztizálásához, a teljesítmény monitorozásához, a biztonsági auditokhoz és a működési problémák gyors azonosításához.
Adatátalakítás és -integráció (ETL a streaming világban)
Sok esetben az adatok különböző forrásokból érkeznek, különböző formátumokban. A streaming architektúra képes valós időben átalakítani, normalizálni és integrálni ezeket az adatokat, mielőtt továbbítaná őket más rendszerekbe vagy adattárolókba. Ez a valós idejű ETL (Extract, Transform, Load) képesség biztosítja, hogy a downstream rendszerek mindig tiszta, konzisztens és azonnal felhasználható adatokkal dolgozzanak.
Kihívások és megfontolások a streaming architektúrák tervezésekor
Bár a streaming adatarchitektúrák hatalmas előnyöket kínálnak, tervezésük és üzemeltetésük számos kihívással jár, amelyeket gondosan mérlegelni kell.
Adatminőség és validáció
A valós idejű adatok gyors áramlása miatt nehezebb lehet biztosítani az adatminőséget és a validációt. Hibás vagy hiányos adatok gyorsan szétterjedhetnek a rendszerben, és téves döntésekhez vezethetnek. Megfelelő adatvalidációs mechanizmusokat kell beépíteni az ingesztálási és feldolgozási szakaszokba, valamint hibakezelési stratégiákat kell kidolgozni a problémás adatok kezelésére (pl. hibás rekordok karanténba helyezése, újrapróbálkozások).
Adatbiztonság és adatvédelem (GDPR)
Az érzékeny adatok valós idejű áramlása különös figyelmet igényel az adatbiztonság és az adatvédelem (például GDPR) szempontjából. Az adatok titkosítását mind nyugalmi állapotban (at rest), mind mozgásban lévő állapotban (in transit) biztosítani kell. Hozzáférési kontrollokat kell implementálni, és az anonimizálás, pszeudonimizálás technikáit alkalmazni kell, ahol szükséges. Az auditálhatóság és a nyomon követhetőség is kulcsfontosságú, hogy az adatok életciklusát végig lehessen követni.
Költségek és erőforrás-menedzsment
A streaming rendszerek üzemeltetése jelentős költségekkel és erőforrás-igénnyel járhat, különösen nagy adatmennyiség és szigorú késleltetési követelmények esetén. A felhőalapú szolgáltatások rugalmasságot kínálnak, de a költségek gyorsan növekedhetnek, ha nincs megfelelő erőforrás-optimalizálás. A skálázhatóság tervezésekor figyelembe kell venni a költséghatékonyságot, és folyamatosan monitorozni kell az erőforrás-kihasználtságot.
Komplexitás és üzemeltetés
Egy elosztott streaming architektúra komplex rendszert alkot, amelynek tervezése, fejlesztése és üzemeltetése jelentős szakértelmet igényel. A hibakeresés, a teljesítményhangolás és a komponensek közötti függőségek kezelése különösen nagy kihívást jelenthet. A konténerizáció (Docker, Kubernetes) és az infrastruktúra kódként (Infrastructure as Code – IaC) megközelítés segíthet a komplexitás kezelésében és az automatizálásban.
Fejlesztési és tesztelési stratégiák
A streaming alkalmazások fejlesztése és tesztelése eltér a hagyományos kötegelt feldolgozástól. A valós idejű adatokkal való munka megköveteli a folyamatos tesztelést, a hibatűrő kód írását és a feldolgozási garanciák (at-least-once, exactly-once) helyes implementálását. Szükség van megfelelő tesztkörnyezetekre, amelyek szimulálni tudják a valós adatfolyamokat és a terhelést, valamint robusztus integrációs és végpontok közötti tesztekre.
A streaming adatarchitektúra jövőbeli trendjei
A streaming adatarchitektúrák területe folyamatosan fejlődik, új technológiák és megközelítések jelennek meg, amelyek tovább bővítik a valós idejű adatfeldolgozás lehetőségeit.
Mesterséges intelligencia és gépi tanulás az adatfolyamokban
A mesterséges intelligencia (MI) és a gépi tanulás (ML) integrálása a streaming architektúrákba az egyik legfontosabb trend. A valós idejű adatfolyamok táplálhatják az ML modelleket, amelyek azonnali predikciókat vagy anomáliafelismerést végezhetnek. Ugyanakkor az ML modellek betanítása és frissítése is történhet folyamatosan, az új adatok beérkezésével (online learning). Ez a konvergencia lehetővé teszi az intelligensebb, adaptívabb rendszerek építését, amelyek azonnal reagálnak a változó körülményekre.
Edge computing és elosztott intelligencia
Az edge computing (peremhálózati számítástechnika) egyre nagyobb szerepet kap a streaming adatok feldolgozásában, különösen az IoT szektorban. Az adatok egy részét már az adatforrás közelében, a hálózat „szélén” feldolgozzák, mielőtt a központi felhőbe küldenék. Ez csökkenti a hálózati késleltetést, a sávszélesség-igényt és növeli az adatbiztonságot. Az elosztott intelligencia azt jelenti, hogy az MI modellek egy része az edge eszközökön fut, míg a komplexebb elemzések a központi felhőben történnek.
Föderált tanulás és adatvédelem
A föderált tanulás egy olyan gépi tanulási megközelítés, amely lehetővé teszi, hogy az MI modellek több elosztott adatforráson (pl. mobil eszközökön) tanuljanak anélkül, hogy az adatokat központilag összegyűjtenék. Ez különösen releváns az adatvédelem szempontjából, mivel az érzékeny adatok nem hagyják el a felhasználó eszközét. A streaming architektúrák segíthetnek a modellfrissítések és a tanult paraméterek valós idejű aggregálásában.
Streamlit és valós idejű dashboardok
Az olyan eszközök, mint a Streamlit, lehetővé teszik az adat tudósok és fejlesztők számára, hogy gyorsan és egyszerűen építsenek interaktív, valós idejű dashboardokat és webalkalmazásokat, amelyek közvetlenül kapcsolódnak a streaming adatfolyamokhoz. Ez demokratizálja az adatokhoz való hozzáférést és az adatalapú döntéshozatalt, mivel a nem technikai felhasználók is könnyen vizualizálhatják és interakcióba léphetnek a friss adatokkal.
Data Mesh és Data Fabric
A Data Mesh és a Data Fabric koncepciók a modern adatarchitektúrák új megközelítései, amelyek célja az adatok hozzáférhetőségének és kezelhetőségének javítása a nagy, elosztott szervezetekben. A Data Mesh az adatokat termékként kezeli, decentralizált tulajdonlással és adattermékek közötti interakcióval. A Data Fabric egy technológiai réteg, amely automatizálja az adatintegrációt és -kezelést az heterogén adatforrások felett. Mindkét megközelítés erősen támaszkodik a streaming adatfolyamokra az adatok mozgásának és elérhetőségének biztosításában.