

A modern üzleti környezetben az adatok jelentősége megkérdőjelezhetetlen. Azonban az adatok növekvő mennyisége, sokfélesége és a felhasználási igények dinamikus változása komoly kihívásokat támaszt a hagyományos adatinfrastruktúrák elé. A központosított adatplatformok, mint az adatlerakatok (data warehouse) vagy az adattavak (data lake), gyakran szűk keresztmetszetet jelentenek, lassítják az innovációt és megnehezítik az adatokhoz való hozzáférést a gyorsan változó üzleti igények mellett. Ezek a rendszerek jellemzően egyetlen, központi adatcsapatra támaszkodnak, amely felelős az adatok beolvasásáért, feldolgozásáért és szolgáltatásáért minden üzleti egység számára. Ez a modell kiválóan működik egy statikusabb, kevesebb adatforrással rendelkező környezetben, de a mai, dinamikus, adatközpontú világban már nem elegendő.
Ezen kihívásokra válaszul merült fel a data mesh koncepciója, amelyet Zhamak Dehghani, a ThoughtWorks tanácsadója mutatott be 2019-ben. A data mesh nem csupán egy technológiai megoldás, hanem egy paradigmaváltás az adatinfrastruktúra tervezésében és kezelésében. Lényegében arról szól, hogy az adatok kezelését decentralizálja, és azokat az üzleti domainekhez rendeli, amelyek az adatokat létrehozzák és a legjobban ismerik. Ez a megközelítés az adatok felelősségét és tulajdonjogát a termékfejlesztési és szolgáltatásnyújtási modellekhez hasonlóan osztja szét, ahol az adatok is termékként, szolgáltatásként működnek.
A data mesh a mikroszolgáltatások architektúrájának és a termékorientált gondolkodásmódnak az adatok világába való átültetése. Célja, hogy feloldja azokat a korlátokat, amelyeket a centralizált adatplatformok jelentenek a skálázhatóság, az agilitás és az adatokhoz való hozzáférés terén. Azáltal, hogy az adatok kezelését, minőségét és szolgáltatását az adatok forrásához legközelebb eső csapatokhoz helyezi, a data mesh lehetővé teszi a gyorsabb innovációt, a jobb adatközpontú döntéshozatalt és a nagyobb üzleti értéket.
A data mesh nem egy dobozos szoftver vagy egy konkrét technológia, hanem egy architekturális paradigma, amely négy alapvető pillérre épül. Ezek a pillérek együttesen biztosítják azt a keretrendszert, amely lehetővé teszi az adatok hatékonyabb kezelését és felhasználását nagy, elosztott rendszerekben. A következő szakaszokban részletesen bemutatjuk ezeket az alapelveket, feltárva működésüket és azt, hogy miként járulnak hozzá a data mesh által kínált előnyökhöz.
A data mesh négy alapelve: a decentralizáció pillérei
A data mesh architektúra alapját négy fő elv képezi, amelyek együttesen biztosítják az adatok hatékony, skálázható és agilis kezelését. Ezek az elvek radikális szakítást jelentenek a hagyományos, centralizált adatkezelési modellekkel, és egy új megközelítést kínálnak az adatok értékének kiaknázására. Fontos megérteni, hogy ezek az elvek nem elszigetelten működnek, hanem egymást erősítve alkotnak egy koherens rendszert.
1. Domain-orientált adatbirtoklás
A data mesh legelső és talán legfontosabb alapelve a domain-orientált adatbirtoklás. A hagyományos adatarchitektúrákban az adatok kezeléséért és tulajdonjogáért egy központi adatcsapat felel. Ez a csapat gyakran szakad el az üzleti domainektől, amelyek az adatokat generálják és felhasználják, ami kommunikációs szakadékokhoz és lassú válaszidőkhöz vezethet az üzleti igényekre. A data mesh ezzel szemben azt javasolja, hogy az adatok tulajdonjogát és felelősségét decentralizálják, és azokat az üzleti domainekhez rendeljék, amelyek az adatokat létrehozzák és a legjobban ismerik.
Ez azt jelenti, hogy minden üzleti domain – legyen szó értékesítésről, marketingről, logisztikáról vagy termékfejlesztésről – saját, keresztfunkcionális csapatot hoz létre, amely nemcsak a domain specifikus alkalmazásokért, hanem az általa generált vagy felhasznált adatokért is teljes mértékben felelős. Ezek a csapatok felelnek az adatok minőségéért, megbízhatóságáért, hozzáférhetőségéért és biztonságáért. A domain-alapú megközelítés biztosítja, hogy az adatok kezelése a leginkább releváns üzleti kontextusban történjen, ami jobb adatminőséget és nagyobb relevanciát eredményez.
A domain-orientált birtoklás előnye, hogy a döntéshozatal közelebb kerül az adatok forrásához és felhasználási pontjához. Azok a mérnökök és adatszakértők, akik nap mint nap dolgoznak egy adott üzleti területtel, sokkal jobban értik az adatok mögötti üzleti logikát és a felhasználási eseteket, mint egy centralizált csapat. Ez a megközelítés drámaian felgyorsítja az adatprojektek megvalósítását, csökkenti a kommunikációs overheadet és növeli az adatok megbízhatóságát, mivel a felelősség egyértelműen az adatok forrásánál van.
Ez a modell egyben azt is jelenti, hogy a domain csapatoknak rendelkezniük kell a megfelelő szakértelemmel és eszközökkel az adatok önálló kezeléséhez. Ehhez azonban szükség van a következő alapelvre, a self-serve adatplatformra, amely biztosítja a szükséges infrastruktúrát és eszközöket.
„A domain-orientált adatbirtoklás az adatokhoz való viszonyunk gyökeres átalakítása: az adatok többé nem egy központi raktár passzív tartalma, hanem az üzleti domainek aktív termékei, amelyekért a létrehozó csapatok vállalnak felelősséget.”
2. Adatok mint termékek (data as a product)
A második alapelv, az adatok mint termékek, szorosan kapcsolódik a domain-orientált adatbirtokláshoz, és talán ez a leginkább forradalmi gondolat a data mesh koncepciójában. A hagyományos megközelítésben az adatok gyakran melléktermékként, vagy egy feldolgozási folyamat nyersanyagaként kezelhetők. A data mesh ezzel szemben azt állítja, hogy az adatoknak önmagukban is termékekként kell működniük, amelyeknek saját életciklusuk, felhasználói bázisuk és minőségi sztenderdjeik vannak.
Mit jelent pontosan az, hogy az adatok termékek? Azt jelenti, hogy minden adatterméknek rendelkeznie kell bizonyos tulajdonságokkal, amelyek biztosítják, hogy az adatok könnyen felfedezhetők, érthetők, megbízhatók és felhasználhatók legyenek más domainek vagy alkalmazások számára. Zhamak Dehghani számos kulcsfontosságú tulajdonságot sorol fel, amelyek egy jó adatterméket jellemeznek:
- Felfedezhető (Discoverable): Az adattermékeknek könnyen megtalálhatóknak kell lenniük egy központi adat katalógusban, érthető metaadatokkal.
- Címezhető (Addressable): Az adattermékeknek egyértelműen azonosítható és hozzáférhető végpontokon keresztül kell elérhetőknek lenniük.
- Megbízható és hiteles (Trustworthy and True): Az adatoknak pontosnak, konzisztensnek és időben frissítettnek kell lenniük, megbízható eredettel.
- Önleíró (Self-describing): Az adattermékeknek tartalmazniuk kell minden szükséges metaadatot a megértésükhöz és felhasználásukhoz, anélkül, hogy külső dokumentációra lenne szükség.
- Interoperábilis (Interoperable): Az adattermékeknek szabványos formátumokban és protokollokon keresztül kell kommunikálniuk más adattermékekkel és rendszerekkel.
- Biztonságos (Secure): Az adatokhoz való hozzáférésnek szigorúan szabályozottnak és ellenőrzöttnek kell lennie, a vonatkozó biztonsági és adatvédelmi előírásoknak megfelelően.
Az adattermékek fejlesztéséért és fenntartásáért a domain csapatok felelnek. Ez a szemléletváltás arra ösztönzi a csapatokat, hogy az adatokra ne csak mint nyersanyagra, hanem mint értékes, újrafelhasználható eszközre tekintsenek, amely más csapatok vagy külső partnerek számára is értéket teremt. Az adatok mint termékek megközelítés javítja az adatok minőségét, csökkenti az adathoz való hozzáférés akadályait és elősegíti az adatok szélesebb körű felhasználását a szervezetben.
Ez az elv kulcsfontosságú a data mesh skálázhatóságához. Ahogy egy szervezet növekszik, és egyre több adatot gyűjt, a domain csapatok önállóan tudnak új adattermékeket létrehozni és szolgáltatni, anélkül, hogy egy központi csapat szűk keresztmetszetévé válna. Ez a rugalmasság és agilitás teszi lehetővé a data mesh számára, hogy alkalmazkodjon a változó üzleti igényekhez és a növekvő adatmennyiséghez.
3. Self-serve adat infrastruktúra platform
A harmadik alapelv, a self-serve adat infrastruktúra platform, teszi lehetővé az első két elv gyakorlati megvalósítását. Ahhoz, hogy a domain csapatok valóban képesek legyenek az adatok birtoklására és adattermékek létrehozására, szükségük van egy olyan infrastruktúrára és eszközökre, amelyeket könnyen és önállóan használhatnak, anélkül, hogy minden egyes lépésnél egy központi infrastruktúra csapatra kellene támaszkodniuk. Ez a platform a „DataOps” elvek megvalósítását segíti elő, biztosítva a gyors és automatizált adatfolyamokat.
A self-serve platform feladata, hogy elvonatkoztassa a domain csapatokat az alapul szolgáló technológiai komplexitástól, és egy magasabb szintű absztrakciót biztosítson az adatkezelési feladatokhoz. Ez magában foglalja az adatok beolvasását, tárolását, feldolgozását, transzformációját, biztonságos hozzáférését és publikálását. A platformnak biztosítania kell a szükséges infrastruktúra-mintákat és eszközöket, amelyek lehetővé teszik a domain csapatok számára, hogy önállóan hozzanak létre és működtessenek adattermékeket.
A self-serve platform tipikus komponensei a következők lehetnek:
- Adatbeolvasó és transzformációs eszközök: Automatizált eszközök az adatok különböző forrásokból való beolvasására és a szükséges transzformációk elvégzésére.
- Adattárolási szolgáltatások: Skálázható, biztonságos tárolási megoldások a strukturált, félig strukturált és strukturálatlan adatok számára.
- Adatfeldolgozó motorok: Elosztott számítási kapacitás az adatok feldolgozására és elemzésére.
- Adat katalógus és metaadat-kezelés: Központi rendszer az adattermékek metaadatainak tárolására, keresésére és kezelésére, biztosítva a felfedezhetőséget.
- Biztonsági és hozzáférés-kezelési eszközök: Egységes mechanizmusok az adatokhoz való hozzáférés szabályozására és a biztonsági előírások betartására.
- Megfigyelhetőségi és monitorozási eszközök: Lehetőségek az adatfolyamok és adattermékek állapotának, teljesítményének és minőségének monitorozására.
- Adatminőség-ellenőrző eszközök: Automatikus ellenőrzések és validációk az adatok minőségének biztosítására.
A platformot egy dedikált platformcsapat fejleszti és tartja fenn, amelynek célja, hogy a domain csapatok számára a lehető legsimább és leginkább automatizált élményt nyújtsa. Ez a megközelítés elválasztja az infrastruktúra komplexitását az üzleti logika fejlesztésétől, lehetővé téve a domain csapatok számára, hogy az üzleti értékteremtésre fókuszáljanak, miközben a platform csapat gondoskodik a mögöttes technológiai rétegről.
„A self-serve platform nem csupán eszközök gyűjteménye, hanem egy gondolkodásmód, amely a domain csapatokat felruházza az adatokkal való önálló munkavégzés képességével, minimalizálva a központi függőségeket és maximalizálva az agilitást.”
4. Federált számítási irányítás (federated computational governance)
A negyedik és egyben utolsó alapelv a federált számítási irányítás. Míg az első három elv a decentralizációt és az autonómiát hangsúlyozza, a federált irányítás biztosítja, hogy ez a decentralizált rendszer koherens és interoperábilis maradjon. Egy nagy szervezetben elengedhetetlen, hogy legyenek bizonyos globális sztenderdek, szabályok és irányelvek, amelyek biztosítják az adatok konzisztenciáját, biztonságát, minőségét és a szabályozási megfelelőséget. A hagyományos, centralizált irányítás azonban szűk keresztmetszetet jelentene egy data mesh környezetben.
A federált irányítás egy hibrid megközelítés, amely ötvözi a decentralizált autonómiát a központi koordinációval. Egy irányítási tanács (governance council) vagy hasonló testület felelős a globális szabályok és sztenderdek meghatározásáért, de ezeket a szabályokat nem felülről kényszerítik ki, hanem a domain csapatokkal együttműködve, konszenzusosan alakítják ki. Ez a tanács magában foglalja az adatbirtokosokat, adatfelhasználókat, jogi és biztonsági szakértőket, valamint a platform csapat képviselőit.
A federált irányítás kulcsfontosságú elemei a következők:
- Globális sztenderdek és szabályok: Meghatározzák az adattermékek közös definícióit, metaadat-formátumait, adatminőségi elvárásokat, biztonsági protokollokat és a hozzáférés-kezelési irányelveket.
- Automatizált ellenőrzés és kikényszerítés: A szabályok kikényszerítése a self-serve platformba integrált automatizált eszközökön keresztül történik, nem pedig manuális ellenőrzésekkel. Ez biztosítja a skálázhatóságot és a konzisztenciát.
- Konszenzus alapú döntéshozatal: A szabályok kialakítása a domain csapatok bevonásával, közös megegyezéssel történik, ami növeli az elfogadottságot és a betartást.
- Auditálhatóság és nyomon követhetőség: Lehetőség van az adatok életciklusának, felhasználásának és a szabályok betartásának nyomon követésére.
- Decentralizált felelősségvállalás: Míg a globális szabályokat a tanács határozza meg, az egyes domain csapatok felelősek a szabályok betartásáért a saját adattermékeik vonatkozásában.
Ez a megközelítés biztosítja, hogy az adatok interoperábilisak legyenek a különböző domainek között, miközben fenntartja az egyes domain csapatok autonómiáját. A federált irányítás célja, hogy egyensúlyt teremtsen a központi koordináció és a decentralizált végrehajtás között, elkerülve a bürokratikus akadályokat, miközben fenntartja az adatok megbízhatóságát és biztonságát az egész szervezetben.
A négy alapelv együttesen alkotja a data mesh architektúra gerincét. Ezek az elvek radikális szakítást jelentenek a hagyományos adatkezelési modellekkel, és egy új, agilisabb, skálázhatóbb és adatközpontúbb szervezeti működést tesznek lehetővé. Azonban a data mesh bevezetése jelentős szervezeti és kulturális változással jár, amihez alapos tervezés és elkötelezettség szükséges.
A data mesh előnyei és potenciális hatásai
A data mesh architektúra bevezetése számos jelentős előnnyel járhat egy szervezet számára, különösen azokban az esetekben, ahol a hagyományos adatinfrastruktúrák már nem képesek hatékonyan kezelni a növekvő adatmennyiséget és a komplex üzleti igényeket. Ezek az előnyök nem csupán technológiaiak, hanem szervezeti és üzleti szempontból is jelentős hatással bírnak.
Nagyobb agilitás és gyorsabb innováció
Az egyik legfontosabb előnye a data mesh-nek a megnövekedett agilitás. Mivel a domain csapatok önállóan birtokolják és kezelik az adataikat, sokkal gyorsabban tudnak reagálni az üzleti igényekre és új adattermékeket fejleszteni. Nincs szükség hosszú várakozási időre egy központi adatcsapatra, ami felgyorsítja az adatokhoz való hozzáférést és az új elemzések vagy alkalmazások bevezetését. Ez a decentralizált megközelítés felgyorsítja az innovációs ciklusokat, és lehetővé teszi a szervezetek számára, hogy gyorsabban alkalmazkodjanak a piaci változásokhoz.
Fokozott adathoz való hozzáférés és felfedezhetőség
A „data as a product” elv és az önkiszolgáló platform biztosítja, hogy az adatok könnyen felfedezhetők és hozzáférhetők legyenek a szervezet egészében. A jól dokumentált, önleíró adattermékek, amelyek egy központi katalógusban szerepelnek, lehetővé teszik a felhasználók számára, hogy gyorsan megtalálják a számukra releváns adatokat anélkül, hogy bonyolult adatbázis-sémákban kellene navigálniuk vagy a központi adatcsapatot kellene segítségül hívniuk. Ez demokratizálja az adatokhoz való hozzáférést és ösztönzi a szélesebb körű adathasználatot.
Jobb adatminőség és megbízhatóság
A domain-orientált adatbirtoklás révén az adatok minőségéért a domain csapatok vállalnak felelősséget, akik a legjobban ismerik az adatokat és azok üzleti kontextusát. Ez a közvetlen felelősségvállalás motiválja a csapatokat a magas adatminőség fenntartására. A beépített adatminőségi ellenőrzések és a „data as a product” elv által támasztott elvárások eredményeként az adatok megbízhatóbbá és pontosabbá válnak, ami jobb döntéshozatalt tesz lehetővé.
Skálázhatóság szervezeti és technológiai szinten
A data mesh természeténél fogva skálázható. Mivel a felelősség és a munka elosztott, a szervezet növekedésével és az adatmennyiség emelkedésével a domain csapatok önállóan tudnak bővülni és új adattermékeket létrehozni. Ez elkerüli a központi csapat túlterhelését és a skálázhatósági problémákat, amelyek a monolitikus adatarchitektúrákra jellemzőek. Technológiai szempontból is skálázhatóbb, mivel az egyes adattermékek függetlenek, és saját infrastruktúrájukon futhatnak, elkerülve a központi erőforrások szűk keresztmetszeteit.
Csökkentett szűk keresztmetszetek és függőségek
A centralizált adatplatformok gyakran képeznek szűk keresztmetszetet, ahol minden adatigény egyetlen csapaton keresztül halad. Ez lassúvá és nehézkessé teszi az új projektek indítását. A data mesh decentralizált megközelítése felszámolja ezeket a szűk keresztmetszeteket, mivel a domain csapatok önállóan képesek az adatok előállítására és fogyasztására. Ez csökkenti a függőségeket és felgyorsítja a fejlesztési folyamatokat.
Nagyobb üzleti értékteremtés
Az adatokhoz való gyorsabb hozzáférés, a jobb minőség és az agilitás mind hozzájárulnak ahhoz, hogy a szervezet gyorsabban és hatékonyabban tudjon üzleti értéket teremteni az adatokból. Legyen szó új termékekről, optimalizált folyamatokról vagy mélyebb ügyfélismeretről, a data mesh felgyorsítja az adatok üzleti insightokká és cselekvő képességgé alakítását.
Összességében a data mesh egy olyan jövőképet vázol fel, ahol az adatok nem csupán technikai entitások, hanem aktív, termékként kezelt eszközök, amelyek közvetlenül hozzájárulnak az üzleti sikerhez. Azonban fontos hangsúlyozni, hogy a bevezetés nem kockázatmentes, és jelentős kihívásokkal is járhat.
Kihívások és megfontolások a data mesh bevezetésénél
Bár a data mesh számos ígéretes előnnyel kecsegtet, a bevezetése nem egyszerű feladat, és jelentős kihívásokat rejt magában. Nem csupán technológiai váltásról van szó, hanem egy mélyreható szervezeti és kulturális átalakulásról, amely alapos tervezést, elkötelezettséget és türelmet igényel.
Szervezeti és kulturális átalakulás
Talán a legnagyobb kihívás a szervezeti és kulturális átalakulás. A data mesh megköveteli a gondolkodásmód gyökeres változását: a központosított irányításról a decentralizált autonómiára való áttérést. Ez magában foglalja a felelősségi körök újradefiniálását, új csapatstruktúrák kialakítását (keresztfunkcionális domain csapatok), és a központi adatcsapat szerepének átalakítását platform csapattá.
A csapatoknak el kell sajátítaniuk az „adat mint termék” gondolkodásmódot, ami azt jelenti, hogy az adatok kezeléséért és minőségéért való felelősség a domain csapatokhoz kerül. Ez ellenállásba ütközhet, mivel új készségeket és felelősségeket igényel. A változásmenedzsment és a kommunikáció kulcsfontosságú a sikeres átmenet szempontjából.
Kezdeti beruházás és komplexitás
A data mesh architektúra bevezetése jelentős kezdeti beruházást igényel mind időben, mind erőforrásokban. A self-serve adatplatform kiépítése, a meglévő rendszerek integrálása és az adattermékek kezdeti definíciója komplex és időigényes folyamat lehet. Emellett a megfelelő szakértelemmel rendelkező tehetségek megtalálása és képzése is kihívást jelenthet.
A kezdeti komplexitás abból is fakad, hogy nincsenek egyértelmű „dobozos” data mesh megoldások. A szervezetnek saját maga kell megterveznie és kiépítenie a platformot és az adattermékeket a saját egyedi igényei szerint, ami jelentős mérnöki munkát igényel.
Adattermék definíció és szabványosítás
Az „adat mint termék” elv megvalósítása megköveteli az adattermékek egyértelmű definícióját és szabványosítását. Mi minősül adatterméknek? Milyen granularitással kell őket létrehozni? Hogyan biztosítható az interoperabilitás a különböző domainek között? Ezekre a kérdésekre a federált irányítási tanácsnak kell választ adnia, de a kezdeti konszenzus kialakítása és a sztenderdek bevezetése időigényes lehet.
A metaadat-kezelés és az adat katalógusok kiépítése is kulcsfontosságú, hogy az adattermékek valóban felfedezhetők és érthetők legyenek. Ennek hiánya alááshatja az egész data mesh koncepciót.
Biztonság és hozzáférés-kezelés elosztott környezetben
Egy elosztott, decentralizált környezetben a biztonság és a hozzáférés-kezelés különösen összetett feladattá válik. Hogyan biztosítható, hogy csak az arra jogosult felhasználók férjenek hozzá a megfelelő adatokhoz? Hogyan valósítható meg az adatok maszkolása, anonimizálása vagy titkosítása a különböző domainekben? A federált irányításnak ki kell dolgoznia a globális biztonsági és adatvédelmi irányelveket, de a technikai megvalósítás és kikényszerítés kihívást jelenthet.
Az adatvédelmi szabályozások, mint a GDPR vagy a CCPA, betartása is bonyolultabbá válhat egy elosztott rendszerben, ahol az adatok sokkal több helyen tárolódnak és kezelődnek.
Eszközök és technológiai ökoszisztéma
Bár a data mesh nem egy konkrét technológia, a bevezetéséhez szükség van egy robusztus eszköz- és technológiai ökoszisztémára. A self-serve platform kiépítése számos különböző technológia integrációját igényelheti (felhő alapú szolgáltatások, adatbázisok, stream feldolgozó rendszerek, BI eszközök stb.). A megfelelő eszközök kiválasztása, integrálása és fenntartása jelentős technológiai szakértelmet igényel.
Nincsenek „egy az egyben” data mesh szoftverek, így a szervezeteknek maguknak kell összeállítaniuk a megoldást a rendelkezésre álló komponensekből, ami komplexitást és testreszabási igényeket jelent.
Ezek a kihívások rávilágítanak arra, hogy a data mesh bevezetése nem egy gyors projekt, hanem egy stratégiai kezdeményezés, amely hosszú távú elkötelezettséget és alapos tervezést igényel. A szervezeteknek fel kell mérniük saját érettségi szintjüket, és fokozatosan kell megközelíteniük az átállást, kezdve pilot projektekkel és fokozatosan bővítve a hatókörüket.
Data mesh vs. hagyományos adatarchitektúrák: összehasonlítás
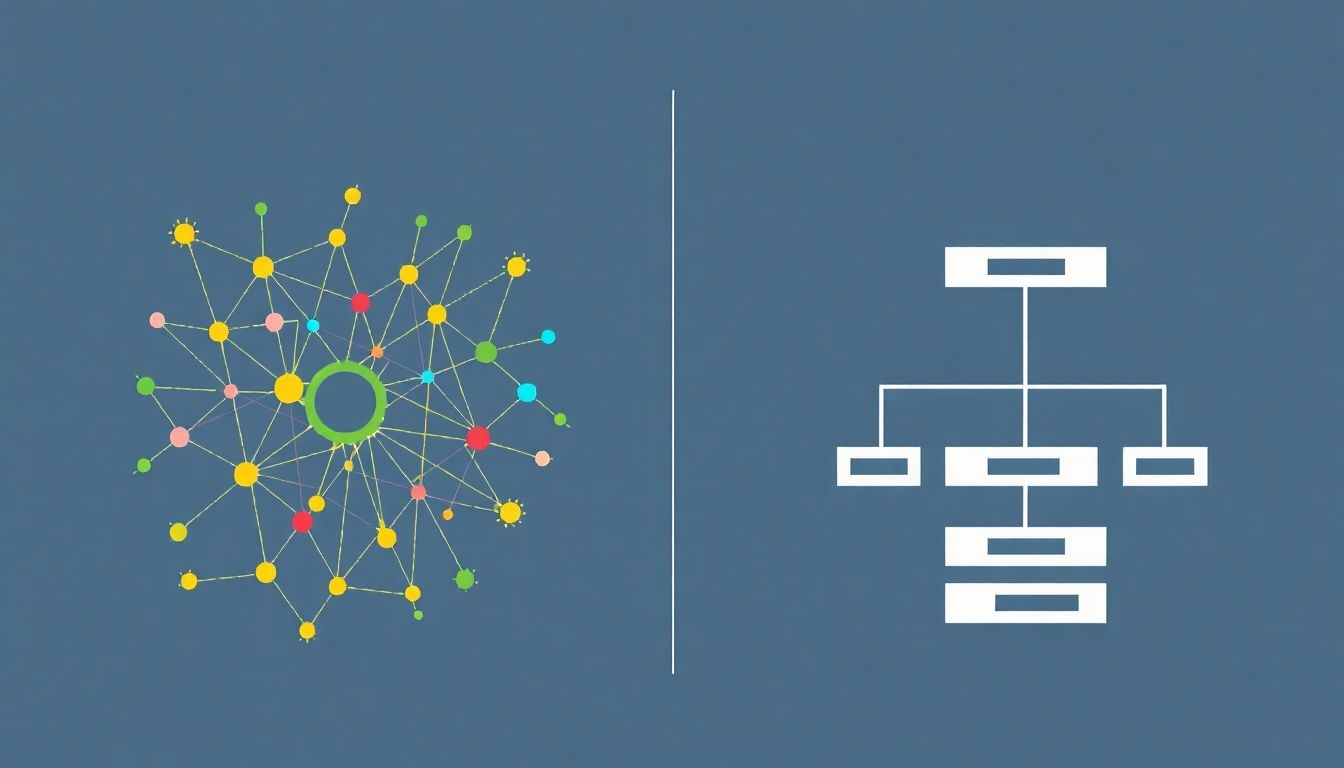
A data mesh koncepciójának megértéséhez elengedhetetlen, hogy összehasonlítsuk a hagyományos adatarchitektúrákkal, mint az adatlerakatokkal (data warehouse), az adattavakkal (data lake) és a viszonylag újabb adatgyártó szalaggal (data fabric). Bár mindegyik célja az adatok kezelése és elemzése, alapvető filozófiájukban és működési elveikben jelentősen különböznek.
| Jellemző | Hagyományos Adatlerakat (Data Warehouse) | Adattó (Data Lake) | Adatgyártó Szalag (Data Fabric) | Data Mesh |
|---|---|---|---|---|
| Fókusz | Strukturált adatok elemzése, üzleti intelligencia (BI) | Nyers, strukturálatlan adatok tárolása, Big Data, ML | Adatintegráció és egységes hozzáférés a heterogén adatokhoz | Decentralizált adatbirtoklás, adatok mint termékek, skálázható adatszolgáltatás |
| Architektúra | Központosított, monolitikus | Központosított tárolás, elosztott feldolgozás | Föderált, integrációs réteg a meglévő rendszerek felett | Decentralizált, elosztott, domain-orientált |
| Adatkezelés | Központi adatcsapat, ETL/ELT pipeline-ok | Központi adatcsapat, Data Engineers | Automatizált adatintegráció, metaadat-kezelés | Domain csapatok (Data Product Owners), self-serve platform |
| Adatminőség | Magas, de a minőségért a központi csapat felel | Változó, „garbage in, garbage out” kockázat | Fokozatosan javul az integrációval | Magas, a domain csapatok felelőssége |
| Skálázhatóság | Korlátozott, szűk keresztmetszetek | Technikailag skálázható, de szervezeti korlátok | Jól skálázható az integrációval | Kiváló, mind technológiai, mind szervezeti szinten |
| Adatokhoz való hozzáférés | Lassú, függőség a központi csapattól | Komplex, adatszakértelmet igényel | Egységesített, virtuális hozzáférés | Gyors, önkiszolgáló, adatok mint termékek |
| Fő hátrány | Szűk keresztmetszetek, merevség, lassú innováció | Adat mocsár (data swamp) kockázata, komplexitás | Nem oldja meg az alapvető szervezeti problémákat, csak integrál | Jelentős kulturális és szervezeti változás, kezdeti komplexitás |
Adatlerakatok (Data Warehouse)
Az adatlerakatok évtizedek óta a vállalati adatelemzés gerincét képezik. Jellemzően strukturált, tisztított adatok tárolására szolgálnak, amelyeket előzetesen transzformáltak és modelleztek üzleti intelligencia (BI) és jelentéskészítési célokra. Központosítottak, és egyetlen adatcsapat felel az adatok beolvasásáért (ETL/ELT), tisztításáért és modellezéséért. Előnyük a magas adatminőség és a megbízhatóság, hátrányuk a merevség, a skálázhatóság korlátai és a lassú reakcióidő az új adatokra és üzleti igényekre. Az adatokhoz való hozzáférés gyakran szűk keresztmetszeten keresztül történik, ami lassítja az innovációt.
Adattavak (Data Lake)
Az adattavak a Big Data térnyerésével jelentek meg, és a strukturált, félig strukturált és strukturálatlan adatok nyers formában történő tárolására szolgálnak. Céljuk, hogy minden adatot egy helyen gyűjtsenek össze, mielőtt azok feldolgozásra kerülnének. Ez nagyobb rugalmasságot biztosít az adatok elemzésében, különösen a gépi tanulás (ML) és a fejlett analitika számára. Azonban az adattavak gyakran „adat mocsárrá” (data swamp) válhatnak, ha nincs megfelelő metaadat-kezelés és adatirányítás. A központi csapat továbbra is kulcsszerepet játszik, ami korlátozza az agilitást és a domain specifikus szakértelem kihasználását.
Adatgyártó szalag (Data Fabric)
Az adatgyártó szalag egy viszonylag új koncepció, amely az adatintegrációra és az adatokhoz való egységes hozzáférésre fókuszál. Célja, hogy egy intelligens réteget hozzon létre a heterogén adatforrások felett, lehetővé téve a felhasználók számára, hogy egységesen hozzáférjenek az adatokhoz, függetlenül azok fizikai elhelyezkedésétől vagy formátumától. Az adatgyártó szalag automatizált adatintegrációt, metaadat-kezelést és adatirányítást használ. Főként technológiai megoldás, amely a meglévő rendszerek integrációjára összpontosít, de nem feltétlenül oldja meg az alapvető szervezeti és tulajdonjogi problémákat, amelyek a centralizált modellekből fakadnak.
Data Mesh
A data mesh alapvetően különbözik az előzőektől, mivel nem csupán egy technológiai megoldás, hanem egy decentralizált architekturális és szervezeti paradigma. Míg az adatlerakatok és adattavak központi adattárolókra épülnek, a data mesh az adatok tulajdonjogát és felelősségét az üzleti domainekhez helyezi. Nem egyetlen központi adattárolót hoz létre, hanem egy elosztott hálózatot, ahol minden domain saját adattermékeket szolgáltat. Az adatgyártó szalaggal ellentétben, amely egy integrációs réteg a meglévő adatok felett, a data mesh megváltoztatja az adatok létrehozásának és kezelésének módját az alapoktól kezdve.
A data mesh erőssége abban rejlik, hogy a technológiai megoldásokat ötvözi a szervezeti átalakulással. A „data as a product” elv és a „self-serve platform” biztosítja a technológiai képességeket, míg a „domain-orientált birtoklás” és a „federált irányítás” biztosítja a szervezeti agilitást és a globális koherenciát. Ez a holisztikus megközelítés teszi a data mesh-t egyedivé és potenciálisan hatékonyabbá a nagy, komplex szervezetek számára, amelyek a hagyományos modellekkel küzdenek.
Végső soron a választás az adott szervezet igényeitől, érettségi szintjétől és kulturális adottságaitól függ. A data mesh nem mindenki számára ideális, és egy jelentős átalakítást igényel. Azonban azoknak a nagyvállalatoknak, amelyek súlyos skálázhatósági, agilitási és adatminőségi problémákkal küzdenek, a data mesh egy ígéretes, hosszú távú megoldást kínálhat.
A data mesh implementációs stratégiája
A data mesh bevezetése egy szervezetben nem egy egyszerű technológiai projekt, hanem egy átfogó stratégiai kezdeményezés, amely gondos tervezést, fázisos megközelítést és folyamatos alkalmazkodást igényel. Nincsenek univerzális „lépésről lépésre” útmutatók, mivel minden szervezet egyedi, de az alábbiakban felvázolunk egy általános stratégiát, amely segíthet a sikeres átmenetben.
1. Felmérés és stratégiaalkotás
Mielőtt bármilyen technológiai döntés születne, alaposan fel kell mérni a szervezet jelenlegi adatérettségi szintjét, a meglévő adatinfrastruktúrát, a felmerülő fájdalompontokat és az üzleti igényeket. Ez magában foglalja az érdekelt felekkel való beszélgetéseket, az adatfolyamok elemzését és a jelenlegi adatkezelési folyamatok azonosítását.
Ezt követően meg kell fogalmazni a data mesh bevezetésének stratégiai céljait. Miért van szükség a data mesh-re? Milyen üzleti problémákat kell megoldania? Milyen metrikák alapján mérjük a sikert? Egyértelműen kommunikálni kell a felső vezetés felé az architektúra előnyeit és a várható kihívásokat. A vezetői támogatás elengedhetetlen a sikerhez.
2. Pilot projekt kiválasztása és bevezetése
Ahelyett, hogy egyszerre próbálnánk meg az egész szervezetet átalakítani, javasolt egy kisebb, jól körülhatárolt pilot projektel kezdeni. Válasszunk ki egy olyan üzleti domaint, amelynek adatai kritikusak, de viszonylag egyszerűen kezelhetők, és a csapat nyitott az új megközelítésekre. Ez a pilot projekt lehetővé teszi a szervezet számára, hogy megtanulja a data mesh működését, azonosítsa a kihívásokat és finomítsa a folyamatokat, mielőtt szélesebb körben bevezetnék.
A pilot projekt során építsünk ki egy minimális életképes self-serve platformot, és hozzunk létre egy vagy két „adatterméket” az adott domainen belül. Koncentráljunk a négy alapelv gyakorlati megvalósítására ebben a korlátozott környezetben.
3. Domainek azonosítása és adattermékek definiálása
A pilot projekt tapasztalatai alapján kezdjük el az üzleti domainek azonosítását és az adatok domainekhez való hozzárendelését. Ez egy iteratív folyamat, amely megköveteli az üzleti és technológiai csapatok szoros együttműködését. Minden domainhez rendeljünk egy keresztfunkcionális csapatot, amely felelős lesz a domain adataiért és az adattermékekért.
Ezzel párhuzamosan el kell kezdeni az adattermékek részletes definícióját. Ez magában foglalja az adatforrások azonosítását, az adatok modelljének és sémájának meghatározását, a minőségi elvárások specifikálását, a hozzáférés-kezelési szabályok megfogalmazását és a szükséges metaadatok rögzítését. A „data as a product” elvnek megfelelően az adattermékeket úgy kell tervezni, hogy könnyen fogyaszthatók és újrafelhasználhatók legyenek.
4. Self-serve platform fejlesztése és bővítése
A pilot projekt során kiépített self-serve platformot fokozatosan kell fejleszteni és bővíteni, hogy képes legyen támogatni a növekvő számú domain csapatot és adatterméket. A platform csapat feladata, hogy automatizálja az adatkezelési folyamatokat, biztosítsa a skálázható infrastruktúrát és fejlessze azokat az eszközöket, amelyek lehetővé teszik a domain csapatok számára az önálló munkát.
A platform fejlesztése során kiemelt figyelmet kell fordítani a biztonságra, a monitorozásra, a hibakezelésre és a teljesítményre. A cél egy olyan robusztus és felhasználóbarát platform létrehozása, amely minimalizálja a domain csapatok technológiai terheit.
5. Federált irányítási keretrendszer kialakítása
Párhuzamosan a platform és az adattermékek fejlesztésével, el kell kezdeni a federált irányítási keretrendszer kialakítását. Hozzunk létre egy irányítási tanácsot, amely magában foglalja a kulcsfontosságú érdekelt feleket (adatbirtokosok, adatfelhasználók, jogi, biztonsági, platform képviselők).
Ez a tanács felelős a globális sztenderdek és szabályok meghatározásáért, mint például az adatminőségi elvárások, a biztonsági irányelvek, a metaadat-szabványok és az interoperabilitási protokollok. Fontos, hogy ezeket a szabályokat konszenzusosan, a domain csapatokkal együttműködve alakítsák ki, és azokat automatizáltan lehessen kikényszeríteni a self-serve platformon keresztül.
6. Tudásmegosztás és képzés
A data mesh bevezetése jelentős tudásmegosztást és képzést igényel. A domain csapatok tagjainak el kell sajátítaniuk az adatkezelési, adatminőségi és adatbiztonsági alapelveket. A platform csapatnak folyamatosan oktatnia kell a domain csapatokat a platform használatára és a legjobb gyakorlatokra.
Hozzon létre belső közösségeket, fórumokat és dokumentációkat, amelyek segítik a tudás áramlását és a problémák megoldását. Ösztönözze a csapatok közötti együttműködést és a tapasztalatcserét.
7. Folyamatos iteráció és finomítás
A data mesh bevezetése nem egy egyszeri projekt, hanem egy folyamatos iterációs és finomítási folyamat. A szervezetnek folyamatosan fel kell mérnie a bevezetett megoldások hatékonyságát, gyűjtenie kell a visszajelzéseket a domain csapatoktól és az érdekelt felektől, és ennek alapján finomítania kell az architektúrát, a platformot és az irányítási keretrendszert.
Az adatok világa folyamatosan változik, és a data mesh-nek is képesnek kell lennie az alkalmazkodásra. Ez a rugalmasság és a folyamatos fejlődés teszi a data mesh-t egy hosszú távon is fenntartható és értékes megoldássá.
A sikeres data mesh implementáció kulcsa a fokozatosság, a rugalmasság és az erős vezetői támogatás. Azok a szervezetek, amelyek hajlandóak befektetni a kulturális és szervezeti átalakulásba, hosszú távon jelentős előnyökhöz juthatnak az adatok hatékonyabb kiaknázása révén.
A data mesh jövője és a kapcsolódó trendek
A data mesh koncepciója viszonylag új, de gyorsan terjed a technológiai és üzleti szektorban, különösen a nagyvállalatok körében, amelyek a hagyományos adatinfrastruktúrák korlátaival szembesülnek. Ahogy egyre több szervezet fedezi fel a decentralizált adatkezelés előnyeit, a data mesh várhatóan egyre inkább beépül a modern adatinfrastruktúra tervezésébe. A jövőben számos trend befolyásolhatja a data mesh fejlődését és adaptációját.
A mesterséges intelligencia és a gépi tanulás konvergenciája
A mesterséges intelligencia (AI) és a gépi tanulás (ML) térnyerése elengedhetetlenné teszi a magas minőségű, könnyen hozzáférhető adatok meglétét. Az AI/ML modellek betanításához és működtetéséhez óriási mennyiségű adatra van szükség, amelyek gyakran különböző domainekből származnak. A data mesh ideális környezetet biztosít ehhez, mivel az adatok „termékként” elérhetők, jól dokumentáltak és megbízhatók. Az adattermékek közvetlenül táplálhatják az ML pipeline-okat, felgyorsítva a modellfejlesztést és a telepítést.
Várhatóan a jövőben egyre több AI/ML specifikus adattermék jelenik meg, amelyek kifejezetten modellek betanítására vagy inferenciára optimalizált adatkészleteket szolgáltatnak. Ez tovább erősítheti a data mesh és az AI/ML közötti szinergiát, elősegítve az adatközpontú AI fejlesztését.
A felhőalapú szolgáltatások és a hibrid környezetek szerepe
A felhőalapú szolgáltatások (AWS, Azure, GCP) kulcsfontosságúak a data mesh megvalósításában. A self-serve platformok építése nagymértékben támaszkodik a felhő skálázhatóságára, rugalmasságára és az előre elkészített adatkezelési szolgáltatásokra (pl. adatbázisok, stream feldolgozó rendszerek, adattárolók). A felhő natív szolgáltatások lehetővé teszik a domain csapatok számára, hogy gyorsan és önállóan építsék ki az adattermékeiket anélkül, hogy az alapul szolgáló infrastruktúra kezelésével kellene foglalkozniuk.
A hibrid és multi-cloud környezetek is egyre gyakoribbak, ami további kihívásokat jelent az adatok interoperabilitása és a federált irányítás szempontjából. A data mesh elvei azonban segíthetnek ezeknek a komplex környezeteknek a kezelésében, biztosítva az adatok egységes kezelését és hozzáférhetőségét a különböző felhők és on-premise rendszerek között.
Az adatirányítás és az adatvédelmi szabályozások fejlődése
Az adatirányítás (data governance) és az adatvédelmi szabályozások (GDPR, CCPA stb.) folyamatosan fejlődnek és egyre szigorúbbá válnak. A data mesh federált irányítási elve ideális platformot biztosít ezeknek a követelményeknek a betartásához egy elosztott környezetben. Az automatizált irányítási szabályok és a beépített biztonsági mechanizmusok lehetővé teszik a szervezetek számára, hogy hatékonyabban kezeljék az adatvédelmi kockázatokat és biztosítsák a megfelelőséget.
A jövőben várhatóan még nagyobb hangsúlyt kapnak az adatminőség, az adat eredete (data lineage) és az adatok auditálhatósága, ami a data mesh „adat mint termék” elvével tökéletesen összeegyeztethető.
A „data product” fogalmának érettsége
Bár az „adat mint termék” a data mesh sarokköve, a fogalom még viszonylag új, és a gyakorlati megvalósítása folyamatosan fejlődik. A jövőben várhatóan egyre kifinomultabb adattermék-tervezési minták és szabványok alakulnak ki, amelyek segítik a szervezeteket a hatékony és újrafelhasználható adattermékek létrehozásában. Ez magában foglalhatja a standardizált API-kat az adatokhoz való hozzáféréshez, a metaadat-specifikációk egységesítését és a minőségi mutatók közös definícióit.
Az adattermékek életciklus-kezelése, verziózása és deprecation-je is egyre fontosabbá válik, ahogy a data mesh architektúra éretté válik.
A szervezeti kultúra és a szakértelem fejlődése
A data mesh sikere nagymértékben függ a szervezeti kultúra és a szakértelem fejlődésétől. Az adatokkal kapcsolatos felelősség decentralizálása új készségeket és gondolkodásmódot igényel a domain csapatoktól. A jövőben egyre nagyobb hangsúlyt kap a „data literacy” (adatműveltség) a szervezet minden szintjén, és a mérnöki csapatoknak is el kell sajátítaniuk az adattermék-fejlesztéshez szükséges képességeket.
A platform csapat szerepe is kulcsfontosságú marad, mint a domain csapatok támogatója és a központi infrastruktúra fenntartója. A jövőben valószínűleg egyre több olyan szakemberre lesz szükség, akik képesek hidat építeni az üzleti domainek és a komplex adatinfrastruktúra között.
Összességében a data mesh egy ígéretes irányvonalat mutat az adatok jövőbeli kezelésére. Bár a bevezetése kihívásokkal jár, a decentralizált, termékorientált megközelítés lehetővé teszi a szervezetek számára, hogy agilisabban, skálázhatóbban és hatékonyabban aknázzák ki az adatokban rejlő potenciált, felkészülve a jövőbeli üzleti és technológiai kihívásokra.