

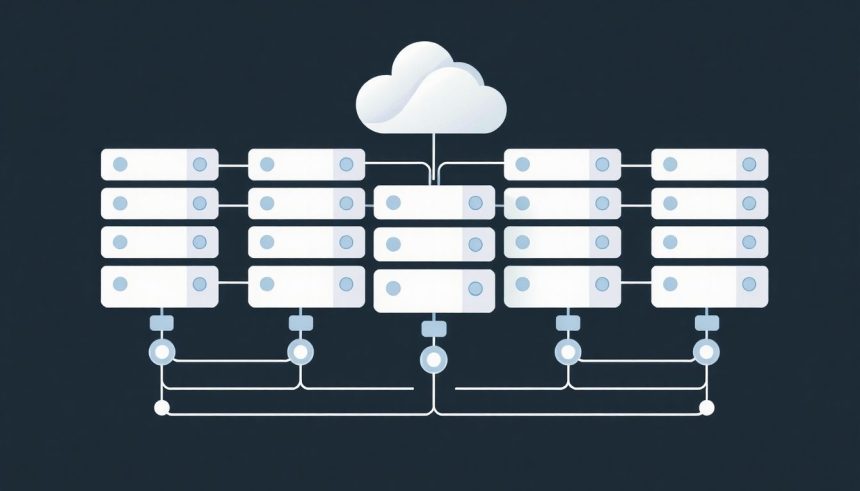
A modern informatikai infrastruktúrák gerincét a hatékony és rugalmas adattárolás adja. Ahogy a digitális adatok exponenciálisan növekednek, úgy válik egyre kritikusabbá a tárolási megoldások optimalizálása, különösen a megosztott, virtualizált és felhőalapú környezetekben. Ebben a kontextusban a tárolókészlet, vagy angolul storage pool, kulcsfontosságú fogalom, amely alapjaiban változtatta meg az adatok kezelésének és elosztásának módját. Ez a koncepció lehetővé teszi a heterogén tárolóeszközök egységes, absztrakt erőforrásként való kezelését, optimalizálva a kapacitást, a teljesítményt és a menedzselhetőséget, miközben jelentősen növeli az infrastruktúra rugalmasságát és skálázhatóságát.
A tárolókészletek lényege az absztrakció: a fizikai lemezeket, legyen szó HDD-kről, SSD-kről vagy NVMe meghajtókról, egyetlen logikai egységbe vonják össze. Ezen egységből aztán virtuális köteteket, fájlrendszereket vagy objektumtárolókat lehet létrehozni, amelyek dinamikusan allokálhatók az alkalmazások és felhasználók számára. Ez a megközelítés gyökeresen eltér a hagyományos, lemezalapú tárolási modelltől, ahol minden egyes fizikai meghajtót különálló entitásként kezeltek, ami gyakran vezetett kapacitás- és teljesítmény-silókhoz. A tárolókészletek bevezetése forradalmasította az adatközpontok működését, jelentős rugalmasságot és hatékonyságot biztosítva a digitális erőforrások kezelésében.
Mi az a tárolókészlet? Definíció és alapelvek
A tárolókészlet egy logikai gyűjteménye a fizikai tárolóeszközöknek, amelyeket egyetlen egységes tárolási erőforrásként kezelnek. Ennek elsődleges célja a tárolókapacitás és a teljesítmény aggregálása, valamint a fizikai hardver komplexitásának elrejtése a felhasználók és az alkalmazások elől. Képzeljünk el egy nagy medencét, amelybe különböző méretű és típusú víztározókból (fizikai lemezekből) ömlik a víz (tárolókapacitás). Ebből a medencéből aztán igény szerint meríthetünk vizet különböző célokra (virtuális kötetek, fájlrendszerek létrehozása), anélkül, hogy aggódnunk kellene a forrás pontos fizikai elhelyezkedése miatt.
Ez az absztrakciós réteg lehetővé teszi a dinamikus erőforrás-allokációt és a skálázhatóságot. Amikor egy alkalmazásnak új tárolóra van szüksége, nem kell egy adott fizikai lemezhez kötni; ehelyett a tárolókészletből kap egy szeletet, anélkül, hogy tudná, melyik fizikai lemezen tárolódnak az adatai. Ez jelentősen leegyszerűsíti a tárolási infrastruktúra menedzsmentjét és optimalizálja a rendelkezésre álló erőforrások kihasználtságát. A tárolókészletek alapvető építőkövei a modern adatközpontoknak, ahol a virtualizáció és a felhőalapú szolgáltatások dominálnak, és ahol az agilitás és a gyors reagálóképesség kritikus üzleti tényezővé vált.
A tárolókészletek mögött meghúzódó filozófia a szoftveresen definiált tárolás (SDS) elvével rezonál. Az SDS leválasztja a tárolóvezérlő funkciókat a fizikai hardverről, lehetővé téve a tárolóerőforrások programozható és automatizált kezelését. Egy tárolókészlet valójában az SDS egyik megnyilvánulása, ahol a szoftveres réteg kezeli a lemezek aggregálását, az adatvédelmet (pl. RAID, erasure coding), a teljesítményoptimalizálást (pl. tiering) és a kapacitáselosztást. Ez a megközelítés sokkal rugalmasabb és költséghatékonyabb megoldásokat kínál, mint a hagyományos, hardver-centrikus tárolórendszerek, amelyek gyakran zárt, dedikált hardvereket igényeltek.
A hagyományos tárolási modellekkel szemben, ahol minden alkalmazás vagy szerver saját dedikált lemezekkel rendelkezett, a tárolókészletek központosítják az erőforrásokat. Ez nemcsak a kapacitás jobb kihasználtságát eredményezi, hanem lehetővé teszi a közös menedzsmentet és a dinamikus erőforrás-elosztást is. Egy fizikai lemez, amely korábban csak egyetlen szerver számára volt elérhető, egy tárolókészlet részeként több szerver és virtuális gép között is megoszthatóvá válik, maximalizálva az infrastruktúra értékét és minimalizálva a felesleges kapacitásokat.
A tárolókészlet nem csupán lemezek halmaza, hanem egy intelligens rendszer, amely optimalizálja az adatok elhelyezését, védelmét és hozzáférését, függetlenül a mögöttes fizikai infrastruktúrától.
A tárolókészletek architektúrája és komponensei
Egy tipikus tárolókészlet számos komponenst foglal magában, amelyek együttműködve biztosítják a zökkenőmentes és hatékony adattárolást. Az architektúra rétegelt felépítésű, a fizikai hardvertől a logikai absztrakciókig. A megértéshez fontos áttekinteni ezeket az építőelemeket és azok funkcióit, hiszen mindegyik hozzájárul a tárolókészlet stabilitásához és teljesítményéhez.
Fizikai réteg: a tárolókészlet alapja
A tárolókészlet legalapvetőbb elemei a fizikai tárolóeszközök. Ezek a meghajtók alkotják a nyers kapacitást, amelyből a készlet építkezik. Jellemzően a következő típusok fordulnak elő:
- Merevlemezek (HDD): Ezek a hagyományos, forgólemezes meghajtók nagy kapacitásúak és költséghatékonyak, ideálisak archiválásra, biztonsági mentésekre és ritkán hozzáférhető adatokra, ahol a költség/gigabájt arány a legfontosabb szempont. Bár lassabbak, mint az SSD-k, még mindig nélkülözhetetlenek a nagy mennyiségű, hideg adatok tárolásában.
- Szilárdtest-meghajtók (SSD): Az SSD-k flash memóriát használnak, ami jelentősen gyorsabb hozzáférési időket és nagyobb IOPS-számot (Input/Output Operations Per Second) eredményez. Ideálisak gyakran hozzáférhető, teljesítménykritikus adatokhoz, adatbázisokhoz, virtualizált környezetekhez és alkalmazásokhoz, amelyek alacsony késleltetést igényelnek.
- NVMe meghajtók: A legújabb generációs, nagy teljesítményű tárolóeszközök, amelyek a PCIe (Peripheral Component Interconnect Express) buszon keresztül közvetlenül kapcsolódnak a CPU-hoz. Az NVMe meghajtók minimális késleltetéssel és extrém magas átviteli sebességgel rendelkeznek, így tökéletesek a leginkább teljesítményigényes munkaterhelésekhez, mint például a valós idejű analitika, mesterséges intelligencia (MI) és gépi tanulás (ML) alkalmazások, vagy nagy teljesítményű adatbázisok.
Egy tárolókészletben gyakran találhatók meg ezen eszközök kombinációi, kihasználva mindegyik előnyeit egy hibrid tárolási modell keretében. Például, a leggyakrabban használt, „forró” adatok SSD-ken vagy NVMe-n tárolódnak, míg a ritkábban használt, nagyobb mennyiségű adatok HDD-ken foglalnak helyet, automatizált tiering mechanizmusok segítségével.
RAID és adatvédelem a készleteken belül
Az adatok biztonsága és integritása kulcsfontosságú. A RAID (Redundant Array of Independent Disks) technológia továbbra is alapvető szerepet játszik a tárolókészleteken belül az adatvédelem és a teljesítmény növelése érdekében. A RAID-szintek (pl. RAID 0, 1, 5, 6, 10) különböző kombinációkat kínálnak az adatok szétosztására és paritásinformációk tárolására, biztosítva az adatok elérhetőségét egy vagy több lemez meghibásodása esetén is. A tárolókészlet menedzsment szoftvere gyakran lehetővé teszi a RAID konfigurációk rugalmas kialakítását a készleten belül, akár különböző RAID-szintek alkalmazását is a különböző adathierarchiákhoz vagy teljesítményprofilokhoz.
A RAID mellett modern adatvédelmi mechanizmusok is beépülnek, mint például a hibatűrő kódolás (erasure coding), amely nagyobb hatékonyságot kínál a nagy méretű tárolókészletekben, különösen az objektumtároló rendszerekben és a diszaggregált SDS megoldásokban. Ez a módszer az adatok darabokra bontásával és redundáns információs blokkok generálásával biztosítja, hogy az adatok akkor is helyreállíthatók legyenek, ha a tárolókészlet több komponense is meghibásodik, gyakran nagyobb redundanciát biztosítva kevesebb tárhelyfelhasználással, mint a hagyományos RAID.
Tárolóvezérlők és HBA-k
A fizikai lemezek és a szerverek közötti kommunikációt a tárolóvezérlők vagy Host Bus Adapterek (HBA) biztosítják. Ezek a kártyák felelősek az I/O műveletek kezeléséért, a RAID-szintek implementálásáért (hardveres RAID vezérlők esetén) és a tárolókészlethez való hozzáférés biztosításáért. A modern tárolórendszerekben a vezérlők gyakran redundánsak, hogy elkerüljék az egyetlen hibapontot (SPOF) és biztosítsák a folyamatos rendelkezésre állást. A HBA-k egyszerűbb, „átengedő” (pass-through) módban működnek, amikor a szoftveresen definiált tárolóréteg végzi a RAID és egyéb funkciókat, míg a dedikált tárolóvezérlők saját processzorokkal és memóriával rendelkezhetnek a fejlettebb funkcionalitás érdekében.
Metaadatok és a készlet integritása
A tárolókészletek működésének kulcsfontosságú eleme a metaadatok kezelése. A metaadatok olyan információk, amelyek leírják az adatokat: hol tárolódnak fizikailag a készleten belül, milyen attribútumokkal rendelkeznek (pl. létrehozási dátum, tulajdonos), milyen hozzáférési jogok vonatkoznak rájuk, és hogyan vannak elosztva a tárolókészleten belül. Ezek a kis méretű, de rendkívül fontos adatok teszik lehetővé az adatok gyors megtalálását és kezelését. A metaadatok integritása létfontosságú a tárolókészlet működéséhez. Ha a metaadatok megsérülnek, az adatokhoz való hozzáférés is meghiúsulhat, még akkor is, ha a tényleges adatblokkok sértetlenek. Ezért a metaadatok is gyakran redundánsan tárolódnak, különösen gyors tárolóeszközökön (pl. SSD-ken), és különleges védelmi mechanizmusokkal vannak ellátva a konzisztencia és a rendelkezésre állás biztosítására.
Szoftveresen definiált tárolás (SDS) és a tárolókészletek
Az SDS alapjaiban határozza meg a modern tárolókészletek működését. Ez a megközelítés a tárolóerőforrásokat szoftveres rétegen keresztül kezeli, függetlenül a mögöttes hardvertől. Az SDS lehetővé teszi a tárolókészletek programozható és automatizált menedzselését, skálázását és optimalizálását, leválasztva a tárolási szolgáltatásokat a hardverről. Ezáltal a szervezetek elkerülhetik a gyártói függőséget, és standard, olcsóbb hardvereket használhatnak, miközben továbbra is élvezhetik a fejlett tárolási funkciókat.
Az SDS keretrendszerek, mint például a Ceph, a GlusterFS, a VMware vSAN vagy a Microsoft Storage Spaces Direct, beépített tárolókészlet-kezelési funkciókkal rendelkeznek. Ezek a platformok lehetővé teszik a felhasználók számára, hogy a meglévő szerverekben lévő fizikai lemezekből tárolókészleteket hozzanak létre, és azokat hálózaton keresztül tegyék elérhetővé. Ez a diszaggregált architektúra rendkívüli rugalmasságot és költséghatékonyságot kínál, mivel a tárolókapacitás és a számítási teljesítmény egymástól függetlenül skálázható, lehetővé téve a vállalatok számára, hogy a dinamikusan változó igényeikhez igazítsák infrastruktúrájukat.
Működési elvek és fejlett technológiák a tárolókészletekben
A tárolókészletek nem csupán a fizikai lemezek aggregálását jelentik; számos fejlett technológia és működési elv teszi őket rendkívül hatékonnyá és rugalmassá. Ezek a funkciók optimalizálják a kapacitást, a teljesítményt, az adatvédelmet és a menedzselhetőséget, jelentősen hozzájárulva a modern adatközpontok hatékonyságához.
Vékony kiépítés (Thin Provisioning)
A vékony kiépítés (Thin Provisioning) az egyik legfontosabb technológia, amely lehetővé teszi a tárolókészletek hatékony kihasználását. Ez a módszer lehetővé teszi, hogy a felhasználók vagy alkalmazások számára nagyobb tárolókapacitást „ígérjünk”, mint amennyi fizikailag rendelkezésre áll a készletben. Például, ha egy virtuális gépnek 1 TB tárhelyre van szüksége, a tárolókészlet azonnal allokálhatja ezt a logikai teret, de fizikailag csak akkor foglalja le a helyet, amikor az adatok ténylegesen íródnak. Ez jelentősen csökkenti a tárolási költségeket és növeli a kihasználtságot, mivel nem kell előre lefoglalni a teljes kapacitást, ha az még üres, elkerülve a felesleges beruházásokat.
A vékony kiépítés kulcsfontosságú a dinamikus környezetekben, ahol a tárolási igények gyorsan változnak. Amikor a tárolókészletben a fizikai hely fogy, új lemezek adhatók hozzá a készlethez anélkül, hogy a felhasználók vagy az alkalmazások ezt észrevennék, és a készlet automatikusan kiterjeszti a rendelkezésre álló logikai teret. Ez a rugalmasság lehetővé teszi a tárolóinfrastruktúra „igény szerinti” bővítését, minimalizálva a kezdeti beruházási költségeket és optimalizálva a tőke- (CAPEX) és működési (OPEX) kiadásokat.
Adat deduplikáció és tömörítés
Az adat deduplikáció és tömörítés további kapacitás-optimalizáló technológiák. A deduplikáció az ismétlődő adatblokkok azonosítását és eltávolítását jelenti, úgy, hogy csak egyetlen példányt tárol a rendszer, a többi azonos blokk pedig erre a példányra mutató hivatkozásként jelenik meg. Ez különösen hatékony virtualizált környezetekben, ahol számos virtuális gép osztozhat ugyanazon operációs rendszer-fájlokon vagy alkalmazás-binárisokon, de hatékony lehet adatbázisokban, fájlmegosztásokban és biztonsági mentésekben is. A deduplikáció történhet inline (írás közben) vagy post-process (írás után), mindkettőnek megvannak a maga előnyei és hátrányai a teljesítmény és a hatékonyság szempontjából.
Az adattömörítés ezzel szemben az adatok méretét csökkenti algoritmusok segítségével, mielőtt azok a lemezre kerülnének. Ez a technológia különösen hatékony a jól tömöríthető adatok (pl. szöveges fájlok, adatbázisok) esetében. Mindkét technológia jelentős mértékben csökkentheti a szükséges fizikai tárolókapacitást, ami alacsonyabb hardverbeszerzési költségeket és jobb teljesítményt eredményezhet, mivel kevesebb adatot kell mozgatni az I/O műveletek során, csökkentve a sávszélesség-igényt is.
Snapshotok és klónok
A snapshotok (pillanatképek) és klónok kulcsfontosságúak az adatvédelemben, a tesztelésben és a fejlesztésben. Egy snapshot egy adott időpontban rögzíti egy kötet állapotát, lehetővé téve a gyors visszaállítást egy korábbi állapotba adatvesztés, korrupció vagy zsarolóvírus-támadás esetén. Mivel a snapshotok általában csak a változásokat tárolják (copy-on-write vagy redirect-on-write mechanizmusokkal, amelyek csak az eredeti adatok módosításakor másolják az érintett blokkokat), rendkívül helytakarékosak és gyorsan létrehozhatók.
A klónok teljes, írható másolatokat hoznak létre egy kötetről. Ez ideális fejlesztői vagy tesztkörnyezetek számára, ahol a fejlesztők a valós éles adatokkal dolgozhatnak anélkül, hogy az eredeti adatok integritását veszélyeztetnék. A klónok létrehozása a tárolókészleten belül rendkívül gyors lehet, mivel gyakran csak metaadat-műveletet igényelnek, és nem az adatok fizikai másolását, így percek alatt rendelkezésre állhat egy teljesen új tesztkörnyezet. Ez felgyorsítja a fejlesztési ciklusokat és lehetővé teszi a hibák gyorsabb azonosítását és javítását.
Tiering (rétegezés) és automatikus adatáthelyezés
A tiering, vagy rétegezés, a különböző teljesítményű tárolóeszközök (pl. NVMe, SSD, HDD) intelligens kihasználására szolgál egy tárolókészleten belül. A rendszer automatikusan mozgatja az adatokat a megfelelő tárolási rétegbe az adatok hozzáférési mintázatai alapján. A gyakran hozzáférhető, „forró” adatok a gyorsabb, drágább rétegeken (pl. NVMe, SSD) tárolódnak, míg a ritkábban használt, „hideg” adatok a lassabb, olcsóbb rétegeken (pl. HDD) kapnak helyet. Ez optimalizálja a teljesítményt és a költségeket egyszerre, maximalizálva az erőforrások kihasználtságát.
Az automatikus adatáthelyezés biztosítja, hogy a tiering folyamatosan működjön, anélkül, hogy manuális beavatkozásra lenne szükség. A tárolókészlet szoftvere figyeli az adatok hozzáférési mintázatait (pl. olvasási/írási gyakoriság, utolsó hozzáférés ideje), és dinamikusan áthelyezi azokat a megfelelő rétegek között, gyakran blokkszinten. Ez a funkció különösen hasznos a változó munkaterhelésű környezetekben, ahol az adatok „hőmérséklete” folyamatosan változik, és garantálja, hogy a legfontosabb adatok mindig a leggyorsabb tárolón legyenek, miközben a költségek alacsonyan maradnak.
QoS (Quality of Service) a tárolókészletekben
A Quality of Service (QoS) képességek lehetővé teszik a tárolókészlet erőforrásainak finomhangolását és prioritásainak beállítását. Ez kritikus fontosságú a megosztott környezetekben, ahol több alkalmazás, virtuális gép vagy konténer osztozik ugyanazon tárolóinfrastruktúrán. A QoS segítségével garantálható egy adott alkalmazás számára a minimális I/O teljesítmény (pl. garantált IOPS vagy átviteli sebesség), vagy korlátozható egy kevésbé kritikus alkalmazás erőforrás-felhasználása, elkerülve a hírhedt „zajos szomszéd” problémát, ahol egyetlen erőforrás-igényes munkaterhelés negatívan befolyásolja a többi teljesítményét. Ez biztosítja, hogy a kritikus üzleti alkalmazások mindig megkapják a szükséges tárolási teljesítményt, függetlenül a többi munkaterheléstől.
Adatok replikációja és katasztrófa-helyreállítás (DR)
A tárolókészletek gyakran beépített adat replikációs képességekkel rendelkeznek, amelyek lehetővé teszik az adatok szinkron vagy aszinkron másolását egy másik tárolókészletre, akár helyben, akár távoli adatközpontba. Ez elengedhetetlen a katasztrófa-helyreállítás (DR) stratégiákhoz, mivel biztosítja, hogy egy elsődleges helyszínen bekövetkező katasztrófa (pl. tűz, árvíz, hardverhiba) esetén az adatok egy másik helyszínen azonnal elérhetők legyenek, minimális adatvesztéssel és állásidővel. A szinkron replikáció garantálja a nulla adatvesztést (RPO=0), de nagyobb hálózati sávszélességet és alacsonyabb késleltetést igényel, míg az aszinkron replikáció tolerál némi adatvesztést, de kisebb hálózati igényekkel működik, és alkalmasabb távoli helyszínek közötti replikációra. A replikáció hozzájárul az üzletmenet folytonosságához és minimalizálja az adatvesztést.
Tárolókészletek megosztott környezetekben
A tárolókészletek igazi ereje a megosztott környezetekben, mint például a virtualizált infrastruktúrák, a konténerizált alkalmazások és a felhőalapú rendszerek, mutatkozik meg. Ezekben a környezetekben a tárolókészletek biztosítják azt a rugalmasságot, skálázhatóságot és hatékonyságot, amely nélkülözhetetlen a modern IT működéséhez, és lehetővé teszik a dinamikus, igény szerinti erőforrás-allokációt.
Virtualizált környezetek: VMware vSphere, Hyper-V, KVM
A szervervirtualizáció forradalmasította az adatközpontokat, és a tárolókészletek alapvető fontosságúak ebben a paradigmában. A virtualizációs platformok, mint a VMware vSphere, a Microsoft Hyper-V vagy a KVM, dinamikus és rugalmas tárolóinfrastruktúrát igényelnek a virtuális gépek (VM) számára. A tárolókészletek absztrakt réteget biztosítanak, amely lehetővé teszi a VM-ek számára, hogy a mögöttes fizikai tárolástól függetlenül hozzáférjenek a szükséges erőforrásokhoz, mintha azok dedikált lemezek lennének, miközben valójában egy megosztott erőforráskészletből gazdálkodnak.
A tárolókészletek lehetővé teszik a vMotion (VMware) vagy Live Migration (Hyper-V) funkciók zökkenőmentes működését, mivel a virtuális gépek tárolója is hálózaton keresztül érhető el, és a VM-ek mozgatásakor az adatoknak nem kell fizikailag áthelyeződniük, csak a vezérlőinformációk frissülnek. Ezenkívül a vékony kiépítés, a deduplikáció és a tiering funkciók jelentősen optimalizálják a tárolókapacitás kihasználtságát a virtualizált környezetekben, ahol gyakran számos azonos operációs rendszerű VM fut. A tárolókészletek egyszerűsítik a tárolási erőforrások allokációját és menedzselését a VM-ek számára, lehetővé téve a gyors kiépítést és a rugalmas bővítést, ami kritikus a dinamikus felhőalapú környezetekben.
Konténerizáció (Docker, Kubernetes) és perzisztens tárolás
A konténerizáció, különösen a Docker és a Kubernetes térnyerésével, új kihívásokat támasztott a tárolás terén. A konténerek alapvetően állapotmentesek (stateless), ami azt jelenti, hogy az alkalmazás adatai nem a konténeren belül tárolódnak, és a konténer leállásakor elvesznek. A perzisztens tárolásra van szükség, hogy az adatok megmaradjanak, még akkor is, ha egy konténer leáll, újraindul vagy áttelepül egy másik csomópontra. Itt jönnek képbe a tárolókészletek.
A Kubernetes például Persistent Volumes (PV) és Persistent Volume Claims (PVC) koncepciókat használ, amelyek a tárolókészletekre épülnek. A tárolókészletek biztosítják az alapul szolgáló tárolóerőforrást, amelyből a PV-k létrehozhatók, majd a PVC-k segítségével a konténerekhez csatolhatók. A Container Storage Interface (CSI) lehetővé teszi, hogy a Kubernetes a különböző tárolórendszerekkel (beleértve a tárolókészleteket) egységes módon kommunikáljon. Ez lehetővé teszi a konténerizált alkalmazások számára, hogy dinamikusan és megbízhatóan hozzáférjenek a tárolóhoz, függetlenül a mögöttes infrastruktúrától. A tárolókészletek biztosítják a konténeres munkaterhelések skálázhatóságát és hordozhatóságát, ami elengedhetetlen a mikroservice alapú architektúrákhoz.
Felhőalapú tárolókészletek: public, private, hybrid cloud
A felhőalapú tárolás, legyen szó nyilvános (public), privát (private) vagy hibrid (hybrid) felhőről, szinte kizárólagosan tárolókészletekre épül. A felhőszolgáltatók (pl. AWS, Azure, Google Cloud) hatalmas, elosztott tárolókészleteket üzemeltetnek, amelyekből a felhasználók igény szerint bérelhetnek tárolókapacitást. Ezek a készletek a felhő saját skálázhatósági, rugalmassági és költséghatékonysági ígéretének alapját képezik, lehetővé téve a felhasználók számára, hogy csak azért fizessenek, amit ténylegesen felhasználnak.
- Nyilvános felhő: Az AWS S3, Azure Blob Storage, Google Cloud Storage mind objektumtároló szolgáltatások, amelyek hatalmas, globálisan elosztott tárolókészletekre épülnek. A blokk- és fájltároló szolgáltatások (pl. AWS EBS, Azure Disks, Google Persistent Disk) is hasonló elven működnek, absztrahálva a mögöttes hardvert.
- Privát felhő: A vállalatok saját adatközpontjaikban építenek ki tárolókészleteket SDS megoldásokkal (pl. OpenStack Cinder, VMware vSAN), hogy felhőszerű rugalmasságot és automatizálást biztosítsanak belső felhasználóik számára, megőrizve az adatok feletti kontrollt és a biztonságot.
- Hibrid felhő: A tárolókészletek kulcsszerepet játszanak a hibrid felhő stratégiákban, lehetővé téve az adatok zökkenőmentes mozgatását a helyi és a nyilvános felhő környezetek között (data mobility). Ez kritikus az adatbázisok áthelyezéséhez, a biztonsági mentések felhőbe történő tárolásához, vagy a burst munkaterhelések felhőbe történő kiterjesztéséhez.
A felhőalapú tárolókészletek a vékony kiépítés, deduplikáció és tiering funkcióit is alkalmazzák a költségek optimalizálása és a teljesítmény maximalizálása érdekében. Emellett beépített redundanciát és katasztrófa-helyreállítási mechanizmusokat is kínálnak, amelyek a felhőszolgáltatások alapvető részét képezik.
Fájl-, blokk- és objektumtárolás a készleteken belül
A tárolókészletek képesek különféle tárolási típusokat biztosítani a rajtuk futó alkalmazások igényei szerint. Ez a sokoldalúság teszi őket rendkívül értékessé a heterogén IT környezetekben, ahol különböző alkalmazásoknak eltérő hozzáférési protokollokra és tárolási paradigmákra van szükségük:
- Blokktárolás: Gyakran használt adatbázisokhoz, virtuális gépekhez és egyéb alkalmazásokhoz, amelyek közvetlen, alacsony késleltetésű hozzáférést igényelnek a tárolóhoz. A blokkokat a rendszer egy nyers lemezpartícióként kezeli, mintha az közvetlenül a szerverhez csatlakozna. Ideális a strukturált adatok és a tranzakciós munkaterhelések számára.
- Fájltárolás: Megosztott fájlokhoz, felhasználói home könyvtárakhoz, tartalomkezelő rendszerekhez, vagy alkalmazásokhoz, amelyek fájlrendszer-alapú hozzáférésre támaszkodnak. Protokollok, mint az NFS (Network File System) Unix/Linux alapú rendszerekhez vagy SMB (Server Message Block) Windows alapú rendszerekhez segítségével érhető el. A fájltárolás biztosítja a fájlok hierarchikus rendszerezését és könnyű megosztását.
- Objektumtárolás: Nagy mennyiségű strukturálatlan adathoz, mint például képek, videók, biztonsági mentések, archivált adatok, vagy Big Data alkalmazások. Rendkívül skálázható és költséghatékony, API-alapú hozzáféréssel (pl. S3 kompatibilis). Az objektumtárolás nem hierarchikus, hanem az adatokhoz egyedi azonosítókon keresztül lehet hozzáférni, metaadatokkal kiegészítve.
Egyetlen tárolókészlet képes lehet mindhárom típusú tárolást biztosítani, dinamikusan allokálva az erőforrásokat az adott igényeknek megfelelően. Ez a rugalmasság tovább növeli a tárolókészletek értékét a heterogén IT környezetekben, ahol a különböző alkalmazások eltérő tárolási modelleket igényelnek.
Hálózati protokollok: iSCSI, Fibre Channel, NFS, SMB
A tárolókészletekhez való hozzáférés különböző hálózati protokollokon keresztül történik, attól függően, hogy milyen típusú tárolásra van szükség, és milyen hálózati infrastruktúra áll rendelkezésre:
- iSCSI (Internet Small Computer System Interface): Blokkszintű tárolást biztosít TCP/IP hálózaton keresztül, standard Ethernet hálózatot használva. Költséghatékony és rugalmas megoldás, széles körben elterjedt virtualizált környezetekben és KKV szektorban, mivel kihasználja a meglévő hálózati infrastruktúrát.
- Fibre Channel (FC): Dedikált, nagy sebességű optikai hálózaton keresztül biztosít blokkszintű tárolást. Magas teljesítményt, alacsony késleltetést és garantált átviteli sebességet kínál, jellemzően nagyvállalati adatközpontokban és kritikus adatbázis-alkalmazásokhoz használják, ahol a teljesítmény és a megbízhatóság a legfontosabb.
- NFS (Network File System): Fájlszintű hozzáférést biztosít Unix/Linux alapú rendszerek számára TCP/IP hálózaton keresztül. Széles körben elterjedt a megosztott fájlrendszerek és a konténeres környezetekben (pl. Kubernetes Persistent Volumes) a Linux alapú munkaterhelések számára.
- SMB (Server Message Block): Fájlszintű hozzáférést biztosít Windows alapú rendszerek számára TCP/IP hálózaton keresztül. Gyakran használják fájlmegosztásokhoz, felhasználói home könyvtárakhoz és Windows alapú alkalmazásokhoz.
A modern tárolókészlet-megoldások gyakran támogatják ezeket a protokollokat, lehetővé téve a különböző operációs rendszerek és alkalmazások számára a tárolóerőforrásokhoz való zökkenőmentes hozzáférést, optimalizálva a hálózati forgalmat és a teljesítményt.
Előnyök és kihívások a tárolókészletek alkalmazásában
A tárolókészletek számos jelentős előnnyel járnak a hagyományos tárolási megközelítésekkel szemben, forradalmasítva az adatközpontok működését. Azonban, mint minden komplex technológia, bizonyos kihívásokat is tartogatnak, amelyek megfelelő tervezést és menedzsmentet igényelnek.
Előnyök
Skálázhatóság és rugalmasság
A tárolókészletek alapvető előnye a skálázhatóság. Könnyedén bővíthetők további fizikai lemezek vagy tárolócsomópontok hozzáadásával, anélkül, hogy az infrastruktúra leállna vagy jelentős konfigurációs változtatásokra lenne szükség. Ez a rugalmasság lehetővé teszi a vállalatok számára, hogy a tárolókapacitásukat az üzleti igényeknek megfelelően növeljék vagy csökkentsék, elkerülve a túlméretezést és a felesleges beruházásokat. A tárolókészletek képesek kezelni mind a kapacitás, mind a teljesítmény növekedését, dinamikusan alkalmazkodva a változó munkaterhelésekhez.
A rugalmasság abban is megmutatkozik, hogy a tárolókészletek heterogén hardverekkel is működhetnek, és dinamikusan allokálhatják az erőforrásokat a különböző munkaterhelésekhez. Ezáltal a tárolóinfrastruktúra sokkal agilisabbá válik, képes gyorsan reagálni az üzleti igények változására, legyen szó új alkalmazások bevezetéséről, adatok gyors növekedéséről vagy teljesítményigények ingadozásáról.
Költséghatékonyság
A tárolókészletek jelentős költségmegtakarítást eredményezhetnek a teljes tulajdonlási költség (TCO) szempontjából. A vékony kiépítés, a deduplikáció és a tömörítés csökkenti a szükséges fizikai tárolókapacitást, ami alacsonyabb hardverbeszerzési költségeket jelent. Az SDS alapú tárolókészletek lehetővé teszik a standard, olcsóbb hardverek használatát is, szemben a drága, zárt tárolórendszerekkel, amelyek gyakran jelentős kezdeti beruházást igényelnek. Az egyszerűsített menedzsment, az automatizálás és a jobb erőforrás-kihasználtság tovább csökkenti az üzemeltetési költségeket (OPEX), beleértve az energiafogyasztást és a hűtési igényeket is.
Egyszerűsített menedzsment
A tárolókészletek absztrakciós rétege leegyszerűsíti a tárolási infrastruktúra menedzselését. A rendszergazdáknak nem kell minden egyes fizikai lemezt külön-külön kezelniük; ehelyett egyetlen logikai entitást, a tárolókészletet felügyelik. Ez jelentősen csökkenti a komplexitást és a hibalehetőségeket. Az automatizált funkciók, mint a tiering, a terheléselosztás, a hibatűrő kódolás vagy a vékony kiépítés, tovább csökkentik a manuális beavatkozás szükségességét, felszabadítva az IT-munkatársak idejét más stratégiai feladatokra, és lehetővé téve a „set it and forget it” megközelítést bizonyos mértékig.
Teljesítményoptimalizáció
A tárolókészletek intelligens algoritmusokat használnak a teljesítmény optimalizálására. A tiering biztosítja, hogy a leggyakrabban használt adatok a leggyorsabb tárolókon legyenek, minimalizálva a késleltetést. A terheléselosztás egyenletesen osztja el az I/O műveleteket a rendelkezésre álló lemezek és vezérlők között, elkerülve a szűk keresztmetszeteket. Az SSD-k és NVMe meghajtók integrálása a készletekbe drámaian növelheti az átviteli sebességet és csökkentheti a késleltetést a teljesítménykritikus alkalmazások számára. A QoS képességek pedig lehetővé teszik a teljesítmény garanciáját a legfontosabb munkaterhelések számára, még egy megosztott környezetben is.
A tárolókészletek a modern adatközpontok sarokkövei, amelyek a rugalmasság, a költséghatékonyság és a teljesítmény optimális egyensúlyát kínálják.
Kihívások
Komplexitás és tervezési kihívások
Bár a tárolókészletek egyszerűsítik a napi menedzsmentet, a kezdeti tervezés és beállítás összetett lehet. Megfelelő szakértelemre van szükség a különböző tárolóeszközök (HDD, SSD, NVMe), RAID-szintek, hálózati protokollok és szoftveres konfigurációk kiválasztásához és optimalizálásához. Egy rosszul tervezett tárolókészlet teljesítményproblémákhoz, kapacitáshiányhoz vagy akár adatvesztéshez is vezethet. A tervezési fázisban figyelembe kell venni a jövőbeli növekedési igényeket, a munkaterhelések jellegét és a rendelkezésre állási követelményeket.
Adatbiztonság és hozzáférés-vezérlés
A megosztott környezetekben az adatbiztonság kiemelt fontosságú. A tárolókészletek központi jellege azt jelenti, hogy ha egy támadó hozzáférést szerez a készlethez, az potenciálisan nagy mennyiségű érzékeny adathoz juthat hozzá. Megfelelő hozzáférés-vezérlési mechanizmusok (pl. RBAC – Role-Based Access Control), adatok titkosítása nyugalmi állapotban (encryption at rest) és átvitel közben (encryption in transit), valamint részletes naplózás és auditálás bevezetése elengedhetetlen a tárolókészletek védelméhez. Ezenkívül a data immutability (adatok megváltoztathatatlansága) funkciók, például a WORM (Write Once Read Many) tárolás, egyre fontosabbá válnak a zsarolóvírusok elleni védelemben.
Teljesítmény-ingadozások
Bár a tárolókészletek célja a teljesítmény optimalizálása, a „zajos szomszéd” probléma továbbra is fennállhat egy megosztott környezetben, ha a QoS nincs megfelelően konfigurálva vagy a rendszer túlterhelt. Egyetlen erőforrás-igényes alkalmazás jelentősen lelassíthatja más alkalmazások tárolóhozzáférését. A megfelelő méretezés, a folyamatos teljesítményfelügyelet és a QoS szabályok finomhangolása kritikus a stabil és kiszámítható teljesítmény biztosításához minden felhasználó és alkalmazás számára.
Vendor lock-in (gyártói függőség)
Bár az SDS megoldások célja a hardveres gyártói függőség csökkentése és a nyílt szabványok támogatása, egyes tárolókészlet-megoldások (különösen a zárt, integrált rendszerek) továbbra is bizonyos fokú gyártói függőséget okozhatnak a szoftveres réteg, a menedzsment eszközök vagy a speciális hardverek tekintetében. Fontos, hogy a vállalatok alaposan értékeljék a hosszú távú rugalmasságot és a migrációs lehetőségeket, és nyílt szabványokra épülő, rugalmas megoldásokat válasszanak, amennyire csak lehetséges, hogy elkerüljék a jövőbeli korlátozásokat.
Gyakorlati alkalmazások és use case-ek
A tárolókészletek rendkívül sokoldalúak, és számos iparágban és alkalmazási területen megtalálhatók. Képességük a heterogén tárolóeszközök egységes kezelésére és a dinamikus erőforrás-elosztásra teszi őket ideálissá a modern, adatközpontú környezetekben. Nézzük meg a leggyakoribb use case-eket, amelyek bemutatják a tárolókészletek széleskörű alkalmazhatóságát.
Vállalati adatközpontok
A tárolókészletek a modern vállalati adatközpontok alapkövei. Lehetővé teszik a virtualizált szerverek, adatbázisok (pl. SQL, Oracle), fájlmegosztások és üzleti alkalmazások (pl. ERP, CRM, Exchange) hatékony tárolását és menedzselését. A skálázhatóság, a rugalmasság és a teljesítményoptimalizáció kulcsfontosságú a folyamatosan növekvő adatmennyiség és a változó üzleti igények kezelésében. A tárolókészletek biztosítják a magas rendelkezésre állást és az adatvédelmet a kritikus üzleti adatok számára, lehetővé téve a gyors helyreállítást és az üzletmenet folytonosságát vészhelyzetek esetén.
A tárolókészletek bevezetése a vállalati környezetben jelentősen csökkenti a tárolási silók számát, javítja az erőforrások kihasználtságát, és leegyszerűsíti a tárolóinfrastruktúra bővítését. A központosított menedzsment felületen keresztül a rendszergazdák könnyedén allokálhatnak új tárhelyet, monitorozhatják a teljesítményt és kezelhetik az adatvédelmi politikákat, mindezt egyetlen integrált rendszerből.
Big Data és analitika
A Big Data és az analitikai munkaterhelések hatalmas mennyiségű adatot generálnak és dolgoznak fel, gyakran elosztott fájlrendszereken (pl. Hadoop HDFS) vagy objektumtárolókon keresztül. A tárolókészletek ideálisak ezekhez a környezetekhez, mivel rendkívül skálázhatóak, képesek kezelni a nagy áteresztőképességet és a párhuzamos hozzáférést, ami elengedhetetlen a nagy adathalmazok gyors feldolgozásához. Az objektumtárolókra épülő tárolókészletek különösen alkalmasak a strukturálatlan adatok (pl. logfájlok, szenzoradatok, közösségi média tartalmak) tárolására és elemzésére, mivel natívan támogatják a masszív skálázhatóságot és a metaadat-gazdag adatelhelyezést.
Ezek a környezetek gyakran igénylik a tiering funkciót is, ahol az aktív analitikai adatok a gyorsabb NVMe/SSD rétegeken, míg a régebbi, ritkábban elemzett adatok a költséghatékonyabb HDD rétegeken tárolódnak. Ez optimalizálja a teljesítményt az éppen futó elemzésekhez, miközben minimalizálja a hosszú távú tárolási költségeket.
Fejlesztési és tesztelési környezetek
A fejlesztési és tesztelési (Dev/Test) környezetek gyakran igényelnek gyorsan kiépíthető és eldobható tárolókapacitást, valósághű adatokkal, anélkül, hogy az éles rendszereket befolyásolnák. A tárolókészletek vékony kiépítési és snapshot/klón funkciói ideálissá teszik őket erre a célra. A fejlesztők és tesztelők percek alatt létrehozhatnak egy új környezetet, valós éles adatok klónjával, anélkül, hogy az eredeti rendszert befolyásolnák vagy jelentős extra tárhelyet foglalnának. Ez jelentősen felgyorsítja a fejlesztési ciklusokat, javítja a szoftverminőséget és támogatja a CI/CD (Continuous Integration/Continuous Delivery) folyamatokat, ahol a gyakori tesztelés elengedhetetlen.
Archiválás és biztonsági mentés
A tárolókészletek kiválóan alkalmasak archiválási és biztonsági mentési célokra is. A tiering segítségével a ritkán hozzáférhető archivált adatok olcsóbb, nagy kapacitású HDD-rétegeken tárolhatók, vagy akár felhőalapú objektumtároló szolgáltatásokba is áthelyezhetők a hosszú távú megőrzés érdekében. Az objektumtárolókra épülő tárolókészletek különösen költséghatékony és skálázható megoldást kínálnak a hosszú távú archiválásra és a biztonsági mentések tárolására, akár a felhőben is, megfelelve a jogi és szabályozási előírásoknak (compliance). Az immutabilitás (változtathatatlanság) funkciók, mint a WORM, biztosítják, hogy az archivált adatok ne legyenek módosíthatók vagy törölhetők egy meghatározott időn belül, ami kritikus a jogi megfelelés szempontjából.
Jövőbeli trendek és kihívások
A tárolókészletek technológiája folyamatosan fejlődik, ahogy az adatok növekednek, az alkalmazások egyre összetettebbé válnak, és az IT infrastruktúra egyre inkább elosztottá válik. Számos izgalmas trend és kihívás formálja a jövő tárolási megoldásait, amelyek még intelligensebbé, ellenállóbbá és hatékonyabbá teszik a tárolókészleteket.
Mesterséges intelligencia és gépi tanulás a tárolásban
A mesterséges intelligencia (MI) és a gépi tanulás (ML) egyre nagyobb szerepet játszik a tárolórendszerek, beleértve a tárolókészletek, menedzselésében és optimalizálásában. Az MI/ML algoritmusok képesek elemezni az I/O mintázatokat, előre jelezni a teljesítményproblémákat, automatikusan optimalizálni az adatáthelyezést a rétegek között, és még a proaktív hibaelhárítást is lehetővé teszik a hibák bekövetkezte előtt. Ez a „intelligens tárolás” vagy „autonóm tárolás” tovább növeli a tárolókészletek hatékonyságát és önállóságát, csökkentve a manuális beavatkozás szükségességét és a működési költségeket. Az MI-vezérelt tárolókészletek képesek lesznek önállóan reagálni a változó környezeti feltételekre és optimalizálni az erőforrás-felhasználást.
Non-volatile memory express (NVMe) és a memória-centrikus tárolás
Az NVMe (Non-Volatile Memory Express) meghajtók térnyerése, amelyek a PCIe buszon keresztül közvetlenül kapcsolódnak a CPU-hoz, radikálisan csökkentik a késleltetést és növelik az átviteli sebességet. A tárolókészletek egyre inkább integrálják az NVMe-t, mint a leggyorsabb tárolási réteget, és az NVMe over Fabrics (NVMe-oF) technológia lehetővé teszi, hogy az NVMe meghajtók hálózaton keresztül is elérhetők legyenek, minimális késleltetéssel. A jövőben a memória-centrikus tárolás, ahol a tároló és a memória közötti határ elmosódik (pl. Intel Optane Persistent Memory technológiák), új lehetőségeket nyit meg a tárolókészletek teljesítményének és rugalmasságának növelésére, lehetővé téve az adatok rendkívül gyors elérését közvetlenül a memóriából.
Edge computing és a decentralizált tárolókészletek
Az edge computing, ahol az adatok feldolgozása a forráshoz közelebb történik, új kihívásokat támaszt a tárolás terén. Az edge környezetekben gyakran korlátozott a hálózati sávszélesség és a tárolóinfrastruktúra. A decentralizált tárolókészletek, amelyek több, kisebb, földrajzilag elosztott helyszínen működnek, de egy egységes logikai egységként kezelhetők, kulcsfontosságúak lesznek az edge computing támogatásában. Ez a megközelítés lehetővé teszi az adatok helyi tárolását és feldolgozását, csökkentve a felhőbe történő adatátvitel szükségességét, miközben biztosítja az adatok konzisztenciáját és elérhetőségét az elosztott környezetben. A konténerizáció és a Kubernetes itt is kulcsszerepet játszik a tárolókészletek menedzselésében.
Kiberbiztonsági fenyegetések és a tárolókészletek védelme
A növekvő kiberbiztonsági fenyegetések, mint a zsarolóvírusok, komoly kihívást jelentenek a tárolókészletek számára, mivel egy sikeres támadás katasztrofális következményekkel járhat a központosított adatmennyiség miatt. A jövő tárolókészleteinek fokozottan ellenállónak kell lenniük a támadásokkal szemben, beépített titkosítással, immutable (változtathatatlan) snapshotokkal, fejlett hozzáférés-vezérléssel és valós idejű fenyegetésészleléssel és automatikus válaszmechanizmusokkal. A kiberreziliencia kulcsfontosságúvá válik, ami magában foglalja az adatok sértetlenségének biztosítását, a gyors helyreállítási képességet és a támadások elleni proaktív védelmet a tárolási rétegben.
Fenntarthatóság és energiahatékonyság
Ahogy az adatközpontok energiafogyasztása növekszik, a fenntarthatóság és az energiahatékonyság egyre fontosabb szemponttá válik a tárolókészletek tervezésében és üzemeltetésében. Az új technológiák, mint az alacsony fogyasztású SSD-k, a fejlettebb adatáthelyezési algoritmusok, az intelligens energiafelügyelet és a felesleges adatok (pl. duplikátumok) minimalizálása, hozzájárulnak a tárolókészletek ökológiai lábnyomának csökkentéséhez. A jövő tárolórendszereinek képesnek kell lenniük a teljesítmény és az energiafogyasztás közötti optimális egyensúly megtalálására, miközben minimalizálják a környezeti hatásokat és a működési költségeket. Az automatizált energiagazdálkodási funkciók lehetővé teszik a tárolóeszközök alacsony fogyasztású üzemmódba kapcsolását, amikor nincs rájuk szükség, vagy optimalizálják az adatok elhelyezését az energiahatékonyabb tárolókon.
A tárolókészletek a modern IT infrastruktúra alapvető építőkövei, amelyek lehetővé teszik a szervezetek számára, hogy hatékonyan, rugalmasan és költséghatékonyan kezeljék folyamatosan növekvő adatmennyiségüket. A definíciójuktól és alapvető működési elveiktől kezdve a fejlett technológiákon át a megosztott környezetekben betöltött szerepükig, a tárolókészletek komplex, mégis nélkülözhetetlen elemei a digitális világnak. A folyamatos innováció és az új kihívásokra való reagálás biztosítja, hogy a tárolókészletek továbbra is a jövő adatközpontjainak és felhőszolgáltatásainak élvonalában maradjanak, adaptálódva az egyre gyorsabban változó technológiai és üzleti környezethez.