


Az üzleti döntéshozatalhoz elengedhetetlen a megbízható és gyorsan hozzáférhető adatok megléte. Ebben a kontextusban az adattárházak (data warehouses) kulcsszerepet játszanak, hiszen céljuk, hogy a különböző operatív rendszerekből származó, szétszórt információkat egységes, konzisztens és analitikus célokra optimalizált formában tárolják. Az adattárházak gerincét, az analitikus lekérdezések alapját kétségkívül a ténytáblák (fact tables) alkotják. Ezek a táblák tartalmazzák azokat a számszerűsíthető mérőszámokat, amelyek az üzleti folyamatok teljesítményét, alakulását tükrözik, és a dimenziótáblákkal együtt alkotják a csillagséma (star schema) vagy hópelyhes séma (snowflake schema) alapját.
A ténytábla fogalma nem csupán egy technikai definíció, hanem egy mélyebb, üzleti logikát tükröző adatmodell-elem. Az adattárházban tárolt adatok értékét az adja, hogy képesek válaszolni az üzleti kérdésekre: Hány terméket adtunk el tegnap? Melyik régióban nőtt a legtöbbet az árbevétel az elmúlt negyedévben? Mennyi időt vesz igénybe egy átlagos megrendelés feldolgozása? Ezekre a kérdésekre a ténytáblákban található mérőszámok (measures) és a dimenziótáblákból származó kontextuális információk (idő, hely, termék, ügyfél) együttesen adnak választ.
Mi is az a ténytábla az adattárházban?
A ténytábla az adattárház központi eleme, amely az üzleti folyamatok során bekövetkező események vagy tranzakciók számszerűsíthető adatait tárolja. Két fő típusú oszlopot tartalmaz: mérőszámokat és idegen kulcsokat (foreign keys). A mérőszámok azok a numerikus értékek, amelyeket elemezni szeretnénk, például eladási mennyiség, árbevétel, profit, hívásidő, tranzakciós összeg. Az idegen kulcsok pedig kapcsolatot teremtenek a ténytábla és a dimenziótáblák között, amelyek a mérőszámok kontextusát biztosítják (pl. idő, termék, ügyfél, földrajzi hely, értékesítő).
Egy ténytábla minden egyes sora egy adott üzleti eseményt vagy folyamatot reprezentál a legfinomabb, legatomibb részletességi szinten (ezt nevezzük granularitásnak). Például egy kiskereskedelmi adattárházban egy ténytábla minden sora egyetlen eladott terméket rögzíthet egy adott tranzakcióból, egy adott időpontban, egy adott üzletben, egy adott ügyfél számára. Ez a részletességi szint kulcsfontosságú, mert ebből lehet a legkülönfélébb aggregációkat és elemzéseket elvégezni.
A ténytábla az adattárház motorja, amely az üzleti elemzésekhez szükséges nyers, számszerűsíthető adatokat szolgáltatja, összekapcsolva azokat a dimenziótáblák által biztosított üzleti kontextussal.
A ténytáblák jellemzően nagyon nagy méretűek, gyakran több milliárd sort is tartalmazhatnak, mivel minden egyes üzleti eseményhez egy-egy sor tartozik. Ezért a tervezésük és optimalizálásuk kiemelt figyelmet igényel a teljesítmény és a skálázhatóság szempontjából. A hatékony lekérdezésekhez elengedhetetlen a megfelelő indexelés, particionálás és aggregációs stratégiák alkalmazása.
A ténytábla anatómiája: mérőszámok és idegen kulcsok
Ahhoz, hogy megértsük egy ténytábla működését és jelentőségét, részletesen meg kell vizsgálnunk annak két alapvető komponensét: a mérőszámokat és az idegen kulcsokat.
Mérőszámok: az elemezhető értékek
A mérőszámok azok a numerikus adatok, amelyek az üzleti folyamatok kvantitatív aspektusait tükrözik. Ezeken az értékeken végezzük el az aggregációkat (összegzés, átlagolás, minimum, maximum, darabszám) és a különböző elemzéseket. A mérőszámok viselkedésük alapján három fő kategóriába sorolhatók:
Additív mérőszámok
Az additív mérőszámok azok, amelyek bármely dimenzió mentén összegezhetők. Ez a leggyakoribb és leginkább kívánatos mérőszám típus, mivel rugalmasan aggregálható bármilyen üzleti szempont szerint. Példák: eladási mennyiség, árbevétel, költség, profit. Ha például tudjuk az egyes termékek eladási mennyiségét naponta, akkor könnyedén kiszámíthatjuk a heti, havi, éves eladási mennyiséget, vagy az összes termék eladási mennyiségét egy adott régióban.
Fél-additív mérőszámok
A fél-additív mérőszámok csak bizonyos dimenziók mentén összegezhetők. A leggyakoribb példa a készletállomány vagy a fiókegyenleg. Ezeket idő dimenzió mentén általában nem érdemes összegezni (például havi átlagot érdemes venni, nem pedig összegezni a havi záró készletet), de más dimenziók (például termék, raktár) mentén már értelmes az összegzés. Egy banki számlaegyenleg például összegezhető ügyfélenként, de idődimenzió mentén az összegezés értelmetlen lenne, hiszen egy adott időpontban érvényes állapotot mutat.
Nem-additív mérőszámok
A nem-additív mérőszámok egyáltalán nem, vagy csak nagyon korlátozottan összegezhetők. Ezek tipikusan arányok, százalékok, átlagok vagy egyedi azonosítók. Példák: átlagos rendelési érték, árfolyam, százalékos kedvezmény, egyedi ügyfélszám. Ezeket a mérőszámokat gyakran úgy számítják ki, hogy additív mérőszámok aggregációjából származtatják őket, például az átlagos rendelési érték az „összes árbevétel” és az „összes rendelés száma” hányadosa. Közvetlenül a ténytáblában való tárolásuk ritkább, inkább a lekérdezések során számítják őket.
A mérőszámok kiválasztása kritikus lépés a ténytábla tervezése során. Fontos, hogy azok relevánsak legyenek az üzleti kérdések szempontjából, és pontosan tükrözzék az elemezni kívánt folyamatokat. A granularitás szintje is szorosan összefügg a mérőszámokkal; minél finomabb a granularitás, annál több additív mérőszámot lehet tárolni, és annál rugalmasabbak az elemzési lehetőségek.
Idegen kulcsok: a dimenziókhoz való kapcsolódás
Az idegen kulcsok a ténytábla és a dimenziótáblák közötti kapcsolatot biztosítják. Minden idegen kulcs egy adott dimenziótábla elsődleges kulcsára mutat. Ezek az oszlopok nem tartalmaznak mérőszámokat, hanem a kontextuális információkhoz való hozzáféréshez szükségesek. Például egy eladási ténytáblában lehet egy datum_kulcs, amely a dátum dimenziótáblára mutat, egy termek_kulcs, amely a termék dimenziótáblára mutat, és így tovább. Ez a struktúra teszi lehetővé, hogy a mérőszámokat idő, termék, ügyfél, földrajzi hely és egyéb üzleti dimenziók szerint elemezzük.
Az idegen kulcsoknak mindig pontosan meg kell egyezniük a dimenziótáblák elsődleges kulcsaival. Ez biztosítja az adatkonzisztenciát és a helyes illesztést a lekérdezések során. Fontos, hogy az adattárház betöltési (ETL/ELT) folyamata során az idegen kulcsok mindig érvényes értékeket kapjanak, még akkor is, ha az eredeti forrásrendszerben hiányosak voltak az adatok. Erre a célra gyakran használnak „ismeretlen” vagy „nem alkalmazható” bejegyzéseket a dimenziótáblákban, amelyekhez az idegen kulcsok mutathatnak.
A ténytábla idegen kulcsainak száma közvetlenül arányos azzal, hogy hány dimenzió mentén szeretnénk elemezni a mérőszámokat. Minél több dimenzióval rendelkezik egy ténytábla, annál több kontextust biztosít az adatokhoz, ami gazdagabb elemzési lehetőségeket eredményez. Ugyanakkor a túl sok dimenzió növelheti a tábla szélességét és a lekérdezések komplexitását.
Különböző ténytábla típusok és tervezési minták
Bár a ténytáblák alapvető szerkezete hasonló, funkcionalitásuk és az általuk modellezett üzleti folyamatok jellege alapján többféle típusuk létezik. A megfelelő ténytábla típus kiválasztása alapvető fontosságú az adattárház hatékonysága és az üzleti elemzések pontossága szempontjából.
Tranzakciós ténytáblák (Transactional Fact Tables)
A tranzakciós ténytáblák a leggyakoribb és legegyszerűbb ténytábla típusok. Minden sor egyetlen üzleti eseményt vagy tranzakciót reprezentál a legfinomabb granularitással. Ezek a táblák tartalmazzák a tranzakcióhoz kapcsolódó összes mérőszámot és az összes releváns dimenzió idegen kulcsát. Például egy online áruházban minden egyes vásárlás egy tranzakció, és minden egyes vásárolt termék egy sor a tranzakciós ténytáblában. Ez a típus ideális a részletes, atomi szintű elemzésekhez, például az egyedi rendelések, hívások, vagy tranzakciók vizsgálatához.
Jellemzők:
- Magas granularitás: minden sor egyedi eseményt jelent.
- Gyakori frissítés: folyamatosan érkeznek új tranzakciók.
- Nagy méret: hatalmas mennyiségű adatot tartalmazhatnak.
- Könnyen érthető: közvetlenül leképezi az üzleti eseményeket.
Példa: Online értékesítési ténytábla, amely rögzíti minden egyes eladott termék adatait (mennyiség, ár, kedvezmény) egy adott rendelésen belül, adott időpontban, adott ügyfél és termék dimenziókkal.
Periódikus pillanatkép ténytáblák (Periodic Snapshot Fact Tables)
A periódikus pillanatkép ténytáblák egy adott időszak (pl. nap, hét, hónap) végén rögzítik az aggregált állapotot vagy teljesítményt. Ezek a táblák nem egyedi eseményeket, hanem egy időszak összesített mérőszámait tartalmazzák. Például egy készletnyilvántartó rendszerben egy periódikus pillanatkép ténytábla minden hónap végén rögzítheti az egyes termékek aktuális készletállományát egy adott raktárban. Ez a típus kiválóan alkalmas trendek elemzésére és időbeli összehasonlításokhoz.
Jellemzők:
- Fix időszak: adatok rögzítése előre meghatározott időközönként.
- Aggregált mérőszámok: gyakran tartalmaznak összegzett, átlagolt vagy számlált értékeket.
- Kisebb méret, mint a tranzakciós táblák: kevesebb sort tartalmaznak, de minden sor több adatot sűríthet.
- Időbeli elemzésekre optimalizált: könnyű összehasonlítani a különböző időszakokat.
Példa: Havi készlet ténytábla, amely minden hónap utolsó napján rögzíti az egyes termékek készletállományát és a mozgásokat (bejövő, kimenő) raktáranként.
Akkumuláló pillanatkép ténytáblák (Accumulating Snapshot Fact Tables)
Az akkumuláló pillanatkép ténytáblák egy olyan üzleti folyamat előrehaladását követik nyomon, amelynek több, jól definiált lépése van. Ezek a táblák egyetlen sorban rögzítik a folyamat kezdeti állapotát, majd ahogy a folyamat halad, ugyanazt a sort frissítik új mérőszámokkal és időbélyegekkel, amelyek az egyes lépések befejezését jelölik. Például egy rendelés feldolgozási folyamatában nyomon követhetők a lépések (rendelés leadva, kifizetve, kiszállítva, kézbesítve), és minden egyes lépéshez időbélyeg tartozik. Ez a típus ideális a folyamatok átfutási idejének elemzésére és a szűk keresztmetszetek azonosítására.
Jellemzők:
- Folyamatkövetés: egyetlen sor reprezentálja a folyamat egészét.
- Több dátumdimenzió: minden lépéshez tartozhat egy dátumkulcs.
- Sorok frissítése: a már létező sorokat frissítik az új adatokkal.
- Átfutási idő elemzésekre optimalizált.
Példa: Rendelésfeldolgozási ténytábla, amely egy sorban tartalmazza a rendelés leadásának, fizetésének, szállításának és kézbesítésének dátumait, valamint a rendelés teljes értékét és a benne lévő tételek számát.
Ténytáblák ténytáblái (Factless Fact Tables)
A ténytáblák ténytáblái (vagy más néven „factless fact tables”) olyan ténytáblák, amelyek nem tartalmaznak numerikus mérőszámokat, csak idegen kulcsokat. Ezeket a táblákat akkor használjuk, ha egy esemény bekövetkezését vagy egy kapcsolat létezését szeretnénk nyomon követni, de nincs hozzá közvetlenül kapcsolódó mérőszám. Az elemzés ilyenkor a bekövetkezett események számosságára vagy a kapcsolatok gyakoriságára fókuszál. Például egy diáklátogatási rendszerben egy ténytábla rögzítheti, hogy melyik diák, melyik órán, melyik dátumon volt jelen. Nincs konkrét „mennyiségi” mérőszám, de a jelenlétek számát mégis elemezni lehet.
Jellemzők:
- Nincsenek numerikus mérőszámok.
- Csak idegen kulcsokat tartalmaz.
- Események vagy kapcsolatok létezését rögzíti.
- Számossági elemzésekre alkalmas.
Példa: Tanfolyam-látogatottsági ténytábla, amely egy sorban rögzíti, hogy egy adott diák (diák_kulcs) részt vett egy adott tanfolyamon (tanfolyam_kulcs) egy adott dátumon (dátum_kulcs).
A megfelelő ténytábla típus kiválasztása nagyban függ az üzleti igényektől és a modellezni kívánt folyamatok természetétől. Gyakran egy adattárházban többféle ténytábla típus is megtalálható, amelyek kiegészítik egymást, és különböző szintű elemzéseket tesznek lehetővé.
A ténytáblák és dimenziótáblák kapcsolata: a csillagséma
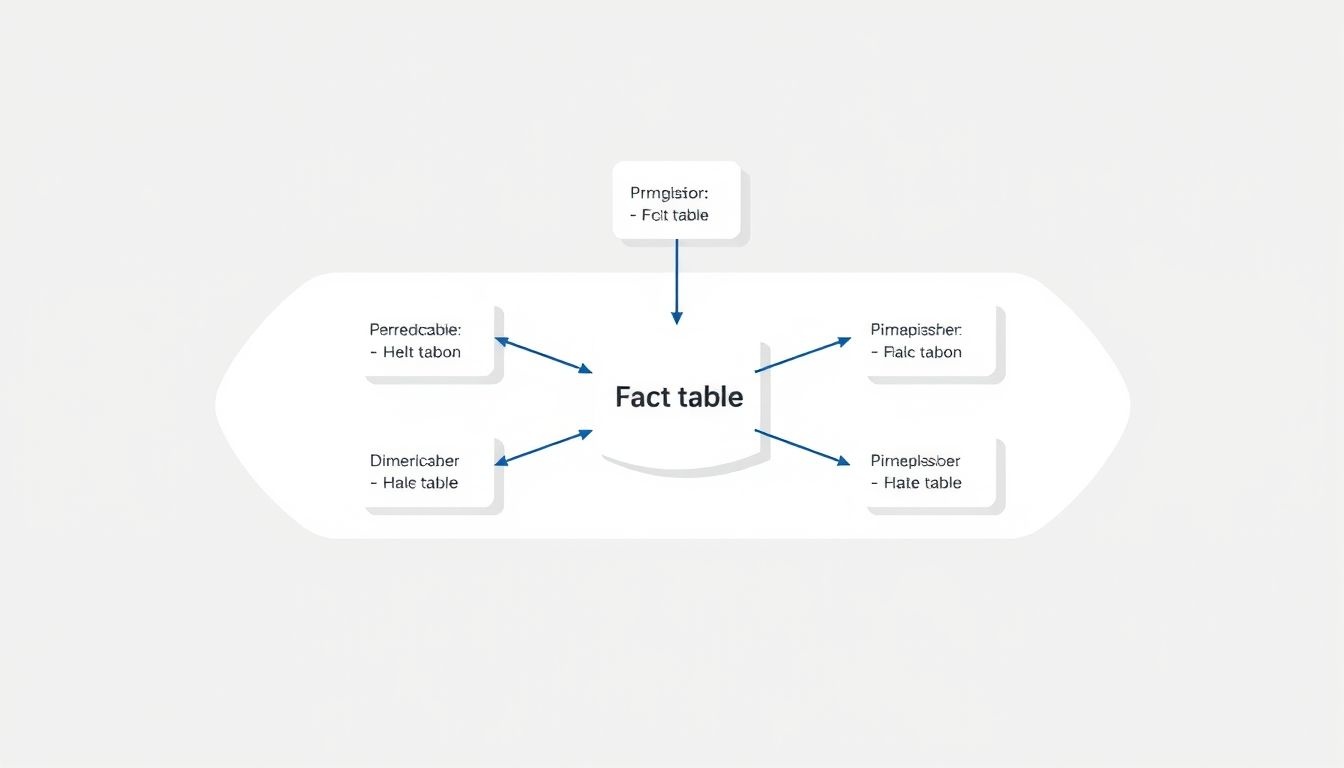
Az adattárházak alapvető építőköve a dimenziós modellezés, amelynek központi eleme a csillagséma (star schema). Ebben a modellben egyetlen ténytábla áll a középpontban, amelyet közvetlenül vesznek körül a dimenziótáblák. Ez a struktúra rendkívül hatékony az analitikus lekérdezések szempontjából, mivel minimalizálja a táblák közötti illesztések számát, és egyszerűsíti az adatok megértését.
A dimenziótáblák (dimension tables) adják a ténytáblában található mérőszámok kontextusát. Ezek tartalmazzák azokat a leíró attribútumokat, amelyek alapján az adatokat elemezni, szűrni, csoportosítani és aggregálni lehet. Például egy idő dimenziótábla tartalmazhatja az év, negyedév, hónap, nap, napszak, hét napja, ünnepnap, munkanap attribútumokat. Egy termék dimenziótábla tartalmazhatja a termék nevét, kategóriáját, márkáját, színét, méretét. Ezek az attribútumok teszik lehetővé, hogy az eladási mennyiséget például termékkategória, vagy hónap szerint vizsgáljuk.
A csillagséma elnevezés a vizuális megjelenéséből ered: a ténytábla a csillag közepén van, a dimenziótáblák pedig a sugarak, amelyek közvetlenül kapcsolódnak a ténytáblához. Minden dimenziótábla egy elsődleges kulccsal rendelkezik, amelyre a ténytábla megfelelő idegen kulcsa hivatkozik.
A csillagséma az adattárházak arany standardja, amely a ténytábla és a dimenziótáblák egyszerű, de rendkívül hatékony elrendezésével biztosítja az üzleti elemzések sebességét és rugalmasságát.
A csillagséma előnyei:
- Egyszerűség: Könnyen érthető és navigálható az üzleti felhasználók és az adatelemzők számára.
- Lekérdezési teljesítmény: A kevés illesztés miatt a lekérdezések gyorsabbak, különösen nagy adatmennyiségek esetén. Az OLAP (Online Analytical Processing) motorok és az BI (Business Intelligence) eszközök optimalizálva vannak a csillagséma struktúrára.
- Rugalmasság: Új dimenziók vagy attribútumok hozzáadása viszonylag egyszerűen megoldható anélkül, hogy a ténytábla szerkezetét jelentősen módosítani kellene.
- Adatminőség: A dimenziótáblákba történő adatelőkészítés (ETL/ELT) során könnyebb biztosítani az adatok konzisztenciáját és minőségét.
Hópelyhes séma (Snowflake Schema)
Bár a csillagséma az ideális, néha a dimenziótáblákat tovább normalizálják, ami a hópelyhes séma létrejöttéhez vezet. Ebben az esetben a dimenziótáblák is kapcsolódnak más dimenziótáblákhoz, létrehozva egy hierarchikusabb struktúrát. Például egy termék dimenziótábla kapcsolódhat egy alkategória dimenziótáblához, amely tovább kapcsolódhat egy fő kategória dimenziótáblához.
A hópelyhes séma előnyei:
- Adatnormalizálás: Csökkenti az adatduplikációt, ami helytakarékosabb lehet.
- Adatintegritás: Jobban biztosítja az adatok integritását a normalizálás révén.
A hópelyhes séma hátrányai:
- Komplexitás: Több illesztést igényel a lekérdezések során, ami lassíthatja a teljesítményt.
- Nehezebb érthetőség: Az üzleti felhasználók számára bonyolultabb lehet.
Általánosságban elmondható, hogy az adattárházak tervezésekor a csillagséma az preferált megközelítés a teljesítmény és az egyszerűség miatt. A hópelyhes séma csak akkor indokolt, ha a tárhely optimalizálása vagy a dimenziótáblák közötti komplex hierarchiák modellezése elsődleges szempont.
Konform dimenziók (Conformed Dimensions)
Az adattárház tervezés egyik kulcsfontosságú koncepciója a konform dimenziók. Egy dimenzió akkor konform, ha különböző ténytáblákban (vagy akár különböző adattárházakban) azonos módon használják, azonos jelentéssel és attribútumokkal. Például egy „Idő” dimenzió konform, ha minden ténytábla (eladás, készlet, pénzügy) ugyanazt az idő dimenziót használja, ugyanazokkal az év, hónap, nap attribútumokkal.
A konform dimenziók előnyei:
- Konzisztencia: Biztosítja, hogy a különböző üzleti területek adatai egységesen értelmezhetők és összehasonlíthatók legyenek.
- Egyszerűség: Az üzleti felhasználók könnyebben navigálnak az adatok között, ha a dimenziók jelentése egységes.
- Újrafelhasználhatóság: A dimenziótáblák egyszer megtervezhetők és elkészíthetők, majd több ténytáblához is felhasználhatók.
- Teljesítmény: A BI eszközök gyakran képesek optimalizálni a lekérdezéseket konform dimenziók esetén.
A konform dimenziók alkalmazása elengedhetetlen egy integrált, vállalati szintű adattárház kiépítéséhez, amely egységes képet ad a vállalat teljesítményéről.
A ténytábla tervezés alapelvei és bevált gyakorlatok
A hatékony és skálázható ténytábla tervezés alapvető fontosságú az adattárház sikeréhez. Számos alapelv és bevált gyakorlat létezik, amelyek segítenek a robusztus és performáns adatmodellek létrehozásában.
Granularitás (Granularity): a részletesség szintje
A granularitás az adattárház tervezés egyik legfontosabb döntése, és azt határozza meg, hogy milyen szintű részletességgel tároljuk az adatokat a ténytáblában. A legfinomabb granularitás azt jelenti, hogy minden egyes üzleti eseményt külön sorban rögzítünk, míg a durvább granularitás aggregált adatokat tárol. Például egy online boltban a legfinomabb granularitás az „egy eladott termék egy tranzakcióban”, míg a durvább lehet „napi eladások termékkategória szerint”.
Fontos szempontok a granularitás kiválasztásakor:
- Üzleti igények: Milyen szintű részletességre van szükség az elemzésekhez? Ha az üzleti felhasználóknak egyedi tranzakciókat kell vizsgálniuk, akkor finom granularitás szükséges.
- Adatmennyiség: Minél finomabb a granularitás, annál több adatot kell tárolni, ami nagyobb tárhelyet és hosszabb betöltési időt igényel.
- Teljesítmény: A nagyon nagy, finom granularitású ténytáblák lekérdezése lassabb lehet. Az aggregált táblák (summary tables) használatával lehet optimalizálni a gyakori lekérdezéseket.
- Additivitás: A finomabb granularitás általában több additív mérőszámot tesz lehetővé, ami rugalmasabb elemzést biztosít.
Általános szabály, hogy érdemes a lehető legfinomabb granularitással kezdeni, amennyiben az üzleti igények és a technikai korlátok ezt megengedik. Ha később durvább granularitásra van szükség, azt könnyebb aggregálni a már meglévő adatokból, mint fordítva.
Dimenziók kiválasztása és tervezése
A ténytábla tervezése során kulcsfontosságú a releváns dimenziók azonosítása és megfelelő kialakítása. Minden dimenziónak egyértelműen definiált attribútumokkal kell rendelkeznie, amelyek segítik a ténytáblában lévő mérőszámok kontextualizálását. Fontos a lassan változó dimenziók (SCD – Slowly Changing Dimensions) kezelése, amelyek attribútumai idővel változhatnak (pl. egy ügyfél címe, egy termék kategóriája). Az SCD típusok (Type 1, Type 2, Type 3) megfelelő alkalmazása biztosítja az időbeli elemzések pontosságát.
Az SCD Type 2 a leggyakoribb megközelítés az adattárházakban, mivel lehetővé teszi a történeti adatok megőrzését. Ebben az esetben, amikor egy dimenzió attribútuma megváltozik, egy új sor jön létre a dimenziótáblában az új adatokkal, és a régi sor „lejár”, vagyis egy érvényességi időszakot kap. A ténytábla ekkor az adott tranzakcióhoz tartozó dimenzió sor megfelelő verziójára mutat.
Mérőszámok definiálása és származtatása
A mérőszámoknak egyértelműen definiáltnak kell lenniük, és tükrözniük kell az üzleti igényeket. Fontos eldönteni, hogy mely mérőszámok legyenek közvetlenül a ténytáblában tárolva (pl. eladási mennyiség, egységár), és melyek legyenek származtatottak (pl. profit margó, átlagos rendelési érték), amelyeket a lekérdezések során számítanak ki. Az additivitás alapos mérlegelése elengedhetetlen a helyes elemzésekhez.
Teljesítmény optimalizálás
Mivel a ténytáblák hatalmas méretűek lehetnek, a teljesítmény optimalizálása kritikus. Néhány technika:
- Indexelés: Az idegen kulcsokon és gyakran használt mérőszámokon létrehozott indexek felgyorsítják a lekérdezéseket.
- Particionálás: A ténytábla felosztása kisebb, kezelhetőbb részekre (pl. idő szerint) javítja a lekérdezési teljesítményt és a karbantarthatóságot.
- Aggregációk (Summary Tables/Aggregates): Gyakran használt aggregációk (pl. napi vagy heti összesítések) előre kiszámítása és külön táblákban való tárolása jelentősen gyorsíthatja a lekérdezéseket, amelyek ezeket az aggregációkat igénylik. Ez egyfajta „denormalizálás” a teljesítmény érdekében.
- Anyagiasított nézetek (Materialized Views): Bizonyos adatbázis-rendszerek támogatják az anyagiasított nézeteket, amelyek előre kiszámított lekérdezési eredményeket tárolnak, és automatikusan frissülnek az alapul szolgáló adatok változásakor.
- Oszlopos tárolás (Columnar Storage): Sok modern adattárház (pl. Snowflake, Redshift, BigQuery) oszlopos tárolást használ, ami rendkívül hatékony a ténytáblákhoz, mivel a lekérdezések jellemzően csak a mérőszámok oszlopainak egy részét és néhány dimenzió kulcsát érintik.
Adatbetöltési stratégiák (ETL/ELT)
A ténytáblák betöltési folyamata (Extract, Transform, Load – ETL, vagy Extract, Load, Transform – ELT) kritikus a teljes adattárház működéséhez. Fontos a hatékony, inkrementális betöltés biztosítása, amely csak az új vagy megváltozott adatokat dolgozza fel. A hibakezelés és az adatminőség ellenőrzése is kulcsfontosságú a betöltési folyamat során, mivel a ténytáblákban lévő hibás adatok az elemzések pontatlanságához vezethetnek.
A dátum dimenzió különösen fontos a ténytáblákban, mivel szinte minden üzleti folyamat időben történik. Egy jól megtervezett dátum dimenzió lehetővé teszi a rugalmas időbeli elemzéseket, mint például a „year-to-date” (YTD) vagy „month-over-month” (MoM) összehasonlításokat.
Gyakori kihívások a ténytábla tervezésben és kezelésben
A ténytáblák tervezése és karbantartása számos kihívást rejthet, különösen nagy és komplex rendszerek esetén. Az alábbiakban bemutatunk néhány gyakori problémát és lehetséges megoldásukat.
Későn érkező dimenziók (Late Arriving Dimensions)
Előfordulhat, hogy a ténytáblába bekerülő tranzakciós adatokhoz tartozó dimenzió adatok még nem állnak rendelkezésre az adattárházban. Például egy új ügyfél rendelést ad le, de az ügyfél dimenzió adatai (pl. szegmens, demográfia) még nem kerültek be a dimenziótáblába. Ez adatminőségi problémákhoz vezethet, mivel a ténytábla egy olyan dimenzió kulcsra hivatkozna, amely nem létezik.
Megoldások:
- Helyőrző dimenzió kulcsok: Hozzon létre egy „ismeretlen” vagy „nem alkalmazható” sort a dimenziótáblában, és használja annak kulcsát, amíg a tényleges dimenzió adatok meg nem érkeznek. Amikor az adatok megérkeznek, frissítse a ténytáblában a kulcsot a megfelelő értékre.
- Várakozás és újrafeldolgozás: Tartsa a ténytábla sorokat egy átmeneti tárolóban, amíg a dimenzió adatok be nem töltődnek, majd dolgozza fel őket.
- Null értékek kezelése: Bár nem ideális, bizonyos esetekben elfogadható a NULL érték használata az idegen kulcsoknál, ha a hiányzó dimenzió adatok nem kritikusak az elsődleges elemzések szempontjából.
Változó dimenziók kezelése (Slowly Changing Dimensions – SCD)
Ahogy korábban említettük, a dimenzió attribútumok idővel változhatnak (pl. egy termék átkerül egy másik kategóriába, egy értékesítő egy másik régióba). A kihívás az, hogy hogyan kezeljük ezeket a változásokat úgy, hogy a történeti elemzések továbbra is pontosak maradjanak. Az SCD Type 2 a leggyakoribb megoldás, de megvalósítása komplexitással jár.
Kihívások az SCD Type 2-vel:
- Nagyobb dimenziótáblák: Az új sorok hozzáadása miatt a dimenziótáblák mérete növekedhet.
- Komplexebb ETL: Az ETL folyamatoknak képesnek kell lenniük az attribútumok változásának észlelésére, új sorok beszúrására és a régi sorok érvényességének lezárására.
- Ténytábla illesztés: A ténytáblának a megfelelő dimenzió sorra kell hivatkoznia az adott tranzakció időpontja alapján.
Nagy adatmennyiség kezelése (Volume)
A ténytáblák gyorsan gigabájtos, terabájtos, sőt petabájtos méretűvé is növekedhetnek, ami jelentős kihívást jelent a tárolás, a lekérdezési teljesítmény és a betöltési idők szempontjából.
Megoldások:
- Particionálás: Idő alapú particionálás (pl. év, hónap) a leggyakoribb, de más dimenziók (pl. régió) szerint is lehet. Ez lehetővé teszi, hogy a lekérdezések csak a releváns partíciókat vizsgálják, és a régi adatok archiválása is egyszerűbbé válik.
- Aggregált táblák: Gyakori lekérdezésekhez előre aggregált táblák létrehozása jelentősen csökkenti a fő ténytáblára nehezedő terhelést.
- Oszlopos adatbázisok: A modern oszlopos adatbázisok (pl. columnar databases) rendkívül hatékonyak a ténytáblák tárolására és lekérdezésére.
- Adatkompresszió: A ténytáblák adatainak tömörítése csökkentheti a tárhelyigényt és javíthatja az I/O teljesítményt.
- In-memory adatbázisok: Bizonyos esetekben, ha a sebesség kritikus, az in-memory adatbázisok használata is szóba jöhet, bár ezek drágábbak lehetnek.
Adatminőség és konzisztencia
A ténytáblákban tárolt adatok minősége alapvető fontosságú az üzleti döntések megbízhatósága szempontjából. A forrásrendszerekből származó hibás, hiányos vagy inkonzisztens adatok torzíthatják az elemzéseket.
Megoldások:
- Erőteljes ETL/ELT folyamatok: A betöltési folyamat során szigorú adatminőségi ellenőrzéseket és transzformációkat kell alkalmazni.
- Adatprofilozás: Rendszeresen profilozni kell a forrásadatokat a lehetséges problémák azonosítására.
- Üzleti szabályok érvényesítése: Az üzleti szabályoknak megfelelően kell tisztítani és validálni az adatokat.
- Dimenziók integritása: Biztosítani kell, hogy minden ténytábla sor érvényes dimenzió kulcsokra hivatkozzon.
Mérőszámok additivitása és származtatása
A mérőszámok helyes kezelése, különösen a fél-additív és nem-additív mérőszámok esetében, gyakori hibaforrás lehet. Az üzleti felhasználók könnyen hibás aggregációkat végezhetnek, ha nem értik a mérőszámok viselkedését.
Megoldások:
- Egyértelmű dokumentáció: Minden mérőszámot és annak additivitási tulajdonságát egyértelműen dokumentálni kell.
- BI eszközök konfigurálása: A BI eszközökben beállítható, hogy mely aggregációs függvények engedélyezettek az egyes mérőszámokhoz.
- Származtatott mérőszámok: A nem-additív mérőszámokat gyakran jobb a lekérdezések során származtatni, mint közvetlenül a ténytáblában tárolni.
Ezeknek a kihívásoknak a proaktív kezelése elengedhetetlen egy stabil, megbízható és nagy teljesítményű adattárház kiépítéséhez, amely hosszú távon képes támogatni az üzleti intelligencia igényeit.
A ténytáblák szerepe az üzleti intelligenciában és az analitikában
A ténytáblák nem csupán technikai adatstruktúrák; az üzleti intelligencia (BI) és az analitika alapkövei. Az általuk tárolt numerikus mérőszámok és a dimenziótáblák által biztosított kontextus teszi lehetővé a mélyreható üzleti elemzéseket, a teljesítmény mérését és a stratégiai döntéshozatalt.
Jelentések és műszerfalak
A ténytáblákból származó adatok képezik az alapját a különböző üzleti jelentéseknek és műszerfalaknak. Legyen szó napi értékesítési jelentésről, havi profit-kimutatásról, vagy egy interaktív ügyfél-műszerfalról, a mögöttes adatok mindig a ténytáblákból származnak, dimenzió attribútumok szerint aggregálva. A BI eszközök (pl. Tableau, Power BI, Qlik Sense) optimalizálva vannak a csillagsémákra, így rendkívül gyorsan képesek vizualizálni és aggregálni a ténytábla adatait a kiválasztott dimenziók szerint.
Adatfeltárás és ad-hoc elemzés
A ténytáblák finom granularitása lehetővé teszi az adatelemzők és üzleti felhasználók számára, hogy szabadon fedezzék fel az adatokat (data exploration) és ad-hoc lekérdezéseket futtassanak. Ez azt jelenti, hogy nem kell előre definiált jelentésekre korlátozódniuk, hanem tetszőlegesen fúrhatnak le (drill-down) a részletes adatokba, vagy fúrhatnak fel (drill-up) az aggregált szintekre, vághatják (slice) és kockázhatják (dice) az adatokat különböző dimenziók mentén. Ez a rugalmasság elengedhetetlen a váratlan minták, trendek és anomáliák felfedezéséhez.
Teljesítmény mérése és KPI-ok (Key Performance Indicators)
A ténytáblákban tárolt mérőszámok közvetlenül kapcsolódnak az üzleti teljesítménymutatókhoz (KPI-okhoz). Például az „árbevétel”, „profit”, „ügyfélszerzési költség”, „átlagos rendelési érték” mind ténytáblákból származó vagy azokból származtatott KPI-ok. A ténytáblák struktúrája lehetővé teszi a KPI-ok könnyű kiszámítását és időbeli nyomon követését, valamint különböző dimenziók (pl. termék, régió, kampány) szerinti elemzését.
Prediktív analitika és gépi tanulás
Bár a ténytáblák elsősorban a leíró és diagnosztikus analitikát támogatják, a bennük tárolt történeti adatok rendkívül értékes bemenetet jelentenek a prediktív modellek és gépi tanulási algoritmusok számára. A múltbeli tranzakciók, események és azokhoz kapcsolódó mérőszámok felhasználhatók jövőbeli viselkedés előrejelzésére, például ügyfél lemorzsolódás, termékkereslet vagy csalás detektálására. Az adattárház tisztított, strukturált adatai ideális alapot biztosítanak ezekhez a fejlett analitikai feladatokhoz.
Adatvezérelt döntéshozatal
Végső soron a ténytáblák célja, hogy támogassák az adatvezérelt döntéshozatalt. Azáltal, hogy pontos, konzisztens és könnyen hozzáférhető üzleti mérőszámokat biztosítanak, lehetővé teszik a vezetők és elemzők számára, hogy tényeken alapuló döntéseket hozzanak, optimalizálják a folyamatokat, azonosítsák a lehetőségeket és mérsékeljék a kockázatokat. Egy jól megtervezett ténytábla hozzájárul a vállalat stratégiai céljainak eléréséhez és versenyképességének növeléséhez.
Példák ténytáblákra különböző iparágakban

A ténytáblák univerzális koncepciót jelentenek, és szinte minden iparágban alkalmazhatók, ahol az üzleti teljesítményt mérni és elemezni kell. Íme néhány példa, bemutatva a ténytáblák sokoldalúságát.
Kiskereskedelem
A kiskereskedelemben az értékesítési ténytábla az egyik leggyakoribb. Minden sor egy eladott terméket reprezentál egy adott tranzakcióból.
| Oszlop neve | Típus | Leírás |
|---|---|---|
tranzakcio_kulcs |
INT | Idegen kulcs a tranzakció dimenzióhoz (ha van) |
datum_kulcs |
INT | Idegen kulcs a dátum dimenzióhoz |
ido_kulcs |
INT | Idegen kulcs az idő dimenzióhoz (óra, perc) |
uzlet_kulcs |
INT | Idegen kulcs az üzlet dimenzióhoz |
termek_kulcs |
INT | Idegen kulcs a termék dimenzióhoz |
ugyfel_kulcs |
INT | Idegen kulcs az ügyfél dimenzióhoz |
eladasi_mennyiseg |
DECIMAL | Eladott termék mennyisége (additív) |
egyseg_ar |
DECIMAL | Termék egységára (nem additív) |
kedvezmeny_osszeg |
DECIMAL | Alkalmazott kedvezmény összege (additív) |
brutto_ar_osszeg |
DECIMAL | Bruttó bevétel (additív) |
netto_ar_osszeg |
DECIMAL | Nettó bevétel (additív) |
Ezzel a ténytáblával elemezhető az árbevétel termék, üzlet, idő, ügyfél, vagy akár értékesítő szerint. Lehetőség van a kosárérték, az átlagos kedvezmény, vagy a legkeresettebb termékek vizsgálatára is.
Pénzügyi szektor
Egy banki fiókegyenleg ténytábla (periodikus pillanatkép) rögzítheti az ügyfél számlájának állapotát minden hónap végén.
| Oszlop neve | Típus | Leírás |
|---|---|---|
datum_kulcs |
INT | Idegen kulcs a dátum dimenzióhoz (hónap vége) |
ugyfel_kulcs |
INT | Idegen kulcs az ügyfél dimenzióhoz |
szamla_kulcs |
INT | Idegen kulcs a számla dimenzióhoz |
szamla_tipus_kulcs |
INT | Idegen kulcs a számla típus dimenzióhoz |
egyenleg_osszeg |
DECIMAL | Aktuális egyenleg (fél-additív) |
kamat_osszeg |
DECIMAL | Havi jóváírt kamat (additív) |
Ez a ténytábla lehetővé teszi az ügyfélportfólió alakulásának, a kamatbevételeknek, vagy a különböző számlatípusok teljesítményének elemzését időben.
Egészségügy
Egy beteglátogatási ténytábla (tranzakciós) rögzítheti az egyes orvos-beteg találkozókat.
| Oszlop neve | Típus | Leírás |
|---|---|---|
datum_kulcs |
INT | Idegen kulcs a dátum dimenzióhoz |
beteg_kulcs |
INT | Idegen kulcs a beteg dimenzióhoz |
orvos_kulcs |
INT | Idegen kulcs az orvos dimenzióhoz |
klinika_kulcs |
INT | Idegen kulcs a klinika dimenzióhoz |
latogatas_tipus_kulcs |
INT | Idegen kulcs a látogatás típus dimenzióhoz |
latogatas_idotartam_perc |
INT | A látogatás időtartama percben (additív) |
koltseg_osszeg |
DECIMAL | A látogatással járó költség (additív) |
Ez a ténytábla segít elemezni az orvosok leterheltségét, a látogatások típusait, a betegforgalmat klinikánként, vagy a különböző kezelések átlagos költségét.
Gyártás
Egy gyártási rendelés ténytábla (akkumuláló pillanatkép) nyomon követheti egy gyártási rendelés állapotát a különböző fázisokon keresztül.
| Oszlop neve | Típus | Leírás |
|---|---|---|
gyartasi_rendeles_kulcs |
INT | Elsődleges kulcs a gyártási rendeléshez |
termek_kulcs |
INT | Idegen kulcs a termék dimenzióhoz |
rendeles_kezdet_datum_kulcs |
INT | Dátum, amikor a rendelés elkezdődött |
gyartas_kezdet_datum_kulcs |
INT | Dátum, amikor a gyártás elkezdődött |
ellenorzes_kezdet_datum_kulcs |
INT | Dátum, amikor az ellenőrzés elkezdődött |
kesz_datum_kulcs |
INT | Dátum, amikor a rendelés elkészült |
mennyiseg_rendelve |
INT | Rendelt mennyiség (additív) |
mennyiseg_gyartva |
INT | Gyártott mennyiség (additív) |
hibas_mennyiseg |
INT | Hibás mennyiség (additív) |
Ez a ténytábla lehetővé teszi a gyártási átfutási idők, a fázisok közötti késedelmek, a selejtarányok és a gyártási kapacitás kihasználtságának elemzését.
Ezek a példák jól illusztrálják, hogyan adaptálható a ténytábla koncepciója a legkülönfélébb üzleti igényekhez és iparágakhoz, mindig a számszerűsíthető események és azok kontextusa köré épülve.
A ténytáblák jövője: felhő alapú adattárházak és big data
Az adattárházak és velük együtt a ténytáblák koncepciója folyamatosan fejlődik, különösen a felhő alapú adattárházak és a big data technológiák térnyerésével. Bár az alapelvek (dimenziós modellezés, ténytáblák, dimenziótáblák) továbbra is érvényesek, a megvalósítás és a skálázhatóság lehetőségei jelentősen kibővültek.
Felhő alapú adattárházak
A modern felhő alapú adattárházak, mint a Snowflake, Google BigQuery, Amazon Redshift és Microsoft Azure Synapse Analytics, forradalmasították a ténytáblák kezelését. Ezek a platformok skálázható, rugalmas és költséghatékony megoldásokat kínálnak a hatalmas adatmennyiségek tárolására és elemzésére. Főbb előnyök:
- Skálázhatóság: Dinamikusan skálázható számítási és tárolási kapacitás, ami ideális a ténytáblák exponenciális növekedésének kezelésére.
- Teljesítmény: Gyakran oszlopos tárolást, intelligens indexelést és lekérdezési optimalizációkat használnak, ami rendkívül gyors lekérdezéseket eredményez még petabájtos méretű ténytáblák esetén is.
- Költséghatékonyság: Pay-as-you-go modell, ahol csak a ténylegesen felhasznált erőforrásokért kell fizetni, ami csökkenti a kezdeti beruházási költségeket.
- Egyszerűbb adminisztráció: A felhőszolgáltatók kezelik az infrastruktúrát, a patch-elést és a karbantartást, így az adatcsapatok az adatmodellezésre és az elemzésre fókuszálhatnak.
Ezek a platformok lehetővé teszik a szervezetek számára, hogy a ténytáblákat még finomabb granularitással tárolják, és komplexebb elemzéseket végezzenek anélkül, hogy aggódniuk kellene a mögöttes infrastruktúra korlátai miatt.
Big Data technológiák és Data Lake-ek
A big data ökoszisztéma, beleértve a Data Lake-eket és technológiákat, mint a Hadoop, Spark, vagy a NoSQL adatbázisok, kiegészíti az adattárházakat, és új dimenziókat nyit a ténytáblák számára. Bár a Data Lake-ek strukturálatlan és félig strukturált adatokat is tárolhatnak, a ténytáblákhoz hasonló strukturált adatok is gyakran megtalálhatók bennük, vagy abból származtatva.
- Data Lakehouse: Ez egy feltörekvő architektúra, amely ötvözi a Data Lake-ek rugalmasságát az adattárházak struktúrájával és teljesítményével. Lehetővé teszi a ténytáblák és dimenziótáblák tárolását és kezelését a Data Lake-en belül, kihasználva a nyílt forráskódú formátumokat (pl. Delta Lake, Iceberg, Hudi) és a Spark-alapú számítási motorokat.
- Streaming adatok: A valós idejű adatok (streaming data) megjelenésével a ténytáblák is egyre inkább képesek valós idejű vagy közel valós idejű frissítésekre, lehetővé téve a folyamatos üzleti intelligenciát és az azonnali döntéshozatalt.
- Gyakran denormalizált ténytáblák: Egyes big data környezetekben a teljesítmény maximalizálása érdekében a ténytáblákat erősebben denormalizálják, beépítve a dimenzió attribútumokat közvetlenül a ténytáblába, elkerülve az illesztéseket a lekérdezések során. Ez azonban növeli az adatduplikációt és a karbantartás komplexitását.
A jövőben a ténytáblák továbbra is az analitikai rendszerek központi elemei maradnak, de adaptálódniuk kell az egyre növekvő adatmennyiséghez, a valós idejű igényekhez és a felhő alapú technológiák kínálta lehetőségekhez. A hangsúly a rugalmasságon, a skálázhatóságon és a gyors hozzáférésen van, miközben megőrzik a dimenziós modellezés alapvető előnyeit az üzleti elemzések számára.