


Az ajánlórendszerek alapvető definíciója és jelentősége
A modern digitális korban, ahol az információ és a termékek végtelen áradata zúdul ránk, az egyéni figyelem a legértékesebb valuta. Ezt a kihívást hivatottak kezelni az ajánlórendszerek, más néven recommendation engine-ek. Lényegükben olyan szoftveres algoritmusok és technológiák összességei, amelyek célja, hogy személyre szabott javaslatokat tegyenek a felhasználók számára, legyen szó termékekről, szolgáltatásokról, tartalmakról vagy akár emberekről.
Az ajánlórendszerek a mesterséges intelligencia (MI) és a gépi tanulás (ML) területének kulcsfontosságú alkalmazásai. Működésük alapja a felhasználók korábbi viselkedésének, preferenciáinak, valamint a hasonló felhasználók vagy elemek jellemzőinek elemzése. Az általuk nyújtott javaslatok jelentősen javítják a felhasználói élményt, miközben a vállalkozások számára is óriási üzleti előnyökkel járnak.
Képzeljük el, hogy egy online áruházban böngészünk, és a rendszer automatikusan olyan termékeket ajánl, amelyek pontosan megfelelnek az ízlésünknek. Vagy egy streaming szolgáltatásban azonnal megtaláljuk a következő filmet vagy sorozatot, ami garantáltan leköt minket. Ezek a mindennapi tapasztalatok az ajánlórendszerek kifinomult működésének köszönhetők. Nem csupán kényelmet biztosítanak, hanem segítenek eligazodni a túlzott információáradatban, csökkentve a döntéshozatali terhet és növelve az elégedettséget.
Az ajánlórendszerek evolúciója az egyszerű, népszerűségi alapú listáktól (pl. „legjobban eladott termékek”) a rendkívül komplex, mélytanuláson alapuló, kontextustudatos rendszerekig terjed. A kezdeti, statikus megoldások helyét mára dinamikus, valós idejű, folyamatosan tanuló algoritmusok vették át, amelyek képesek alkalmazkodni a felhasználói preferenciák változásaihoz és az új adatokhoz.
Az ajánlórendszerek nem csak a fogyasztói oldalon mutatják meg erejüket. Az üzleti szektorban is kulcsszerepet játszanak a bevétel növelésében, az ügyfélhűség erősítésében és a működési hatékonyság javításában. Segítségükkel a vállalatok jobban megérthetik ügyfeleiket, optimalizálhatják kínálatukat és személyre szabott marketing kampányokat indíthatnak.
Az ajánlórendszerek a digitális gazdaság motorjai, amelyek a személyre szabás erejével alakítják át a felhasználói élményt és a kereskedelmi stratégiákat, hidalva át az információbőség és a releváns tartalom közötti szakadékot.
A technológia fejlődésével párhuzamosan az ajánlórendszerek is egyre kifinomultabbá válnak, képesek komplex mintázatokat felismerni az adatokban, és olyan javaslatokat tenni, amelyek sokszor meglepően pontosak, sőt, olykor még a felhasználó saját tudatos preferenciáin is túlmutatnak, új érdeklődési területeket nyitva meg.
Az ajánlórendszerek működésének alapelvei: Adatgyűjtés és feldolgozás
Az ajánlórendszerek működésének gerincét az adatok képezik. Nélkülük a rendszer vakon tapogatózna, és képtelen lenne értelmes javaslatokat tenni. Az adatok gyűjtése és megfelelő előkészítése kritikus lépés a hatékony ajánlások létrehozásához. Két fő kategóriába sorolhatjuk a gyűjtött adatokat: az explicit és az implicit adatokra.
Az explicit adatok azok, amelyeket a felhasználó tudatosan és közvetlenül ad meg. Ezek közé tartoznak például:
- Értékelések (Ratings): Csillagos értékelések filmekhez, termékekhez (pl. 1-től 5-ig).
- Vélemények (Reviews): Írásos visszajelzések, amelyek részletesebb információt nyújtanak.
- Lájkok és nemtetszések (Likes/Dislikes): Egyszerű bináris visszajelzések.
- Kívánságlisták (Wishlists): A felhasználó által megjelölt, jövőbeni érdeklődésre számot tartó elemek.
- Felmérések (Surveys): Közvetlen kérdések a preferenciákról.
Ezek az adatok rendkívül értékesek, mert közvetlenül tükrözik a felhasználó szándékát és véleményét. Azonban gyakran ritkásak, mivel a felhasználók nem mindig hajlandók vagy van idejük explicit módon visszajelzést adni minden interakcióról.
Az implicit adatok ezzel szemben a felhasználó viselkedéséből, anélkül, hogy tudatosan visszajelzést adna, gyűjtött információk. Ezek sokkal bőségesebbek és folyamatosan keletkeznek:
- Megtekintések (Views): Melyik terméket, cikket, videót nézte meg a felhasználó.
- Kattintások (Clicks): Mely linkekre, hirdetésekre kattintott.
- Vásárlások (Purchases): Milyen termékeket vásárolt.
- Keresési lekérdezések (Search Queries): Milyen kulcsszavakra keresett.
- Időráfordítás (Time Spent): Mennyi időt töltött egy adott oldalon vagy tartalommal.
- Görgetés (Scrolling): Mennyire görgetett le egy oldalon.
- Kosárba helyezés (Add to Cart): Mely termékeket tette a kosárba, még ha nem is vásárolta meg őket.
- Eszközhasználat (Device Usage): Milyen eszközről éri el a szolgáltatást.
- Helyszín (Location): Honnan éri el a szolgáltatást (kontextuális ajánlásokhoz).
Az implicit adatok gyűjtése kevésbé invazív, és sokkal nagyobb mennyiségű információt szolgáltat. Azonban az értelmezésük bonyolultabb lehet, mivel egy kattintás nem feltétlenül jelent pozitív érdeklődést, ahogy egy megtekintés sem feltétlenül elégedettséget.
Adatfeldolgozás és reprezentáció
Az összegyűjtött nyers adatok önmagukban nem elegendőek. Ezeket elő kell készíteni az algoritmusok számára, ami magában foglalja az adat tisztítását, a hiányzó értékek kezelését, a normalizálást és a jellemzők kinyerését (feature engineering). Például, a szöveges véleményekből kulcsszavakat, hangulatot, vagy tematikus kategóriákat lehet kinyerni.
Az adatok gyakran felhasználó-elem mátrixként kerülnek reprezentálásra, ahol a sorok a felhasználókat, az oszlopok az elemeket (termékeket, filmeket stb.) jelölik, a metszéspontok pedig a felhasználó és az elem közötti interakciót (pl. értékelés, vásárlás). Ez a mátrix általában rendkívül ritkás (sparse), mivel egy felhasználó csak az elemek kis töredékével lép interakcióba.
A felhasználók és az elemek jellemzőinek (attribútumainak) kinyerése szintén kulcsfontosságú. Például egy film esetében a műfaj, rendező, színészek, megjelenés éve, kulcsszavak lehetnek fontos jellemzők. Egy felhasználó esetében a demográfiai adatok, korábbi vásárlások kategóriái, vagy böngészési előzmények is relevánsak lehetnek.
A hatékony adatgyűjtés és előkészítés biztosítja, hogy az ajánlórendszer a lehető legpontosabb és legrelevánsabb javaslatokat tudja tenni. A folyamatos adatfrissítés és az új adatok integrálása elengedhetetlen a rendszer adaptivitásához és hosszú távú hatékonyságához.
Az ajánlórendszerek fő típusai és működésük
Az ajánlórendszerek algoritmusainak széles skálája létezik, amelyek különböző megközelítéseket alkalmaznak a javaslatok generálására. A legfontosabb típusok a kollaboratív szűrés, a tartalomalapú szűrés és a hibrid rendszerek.
1. Kollaboratív szűrés (Collaborative Filtering – CF)
A kollaboratív szűrés az egyik legelterjedtebb és leggyakrabban használt ajánlórendszer típus. Alapvetése, hogy ha két felhasználó a múltban hasonlóan viselkedett, akkor valószínűleg a jövőben is hasonlóan fognak reagálni az új elemekre. Hasonlóképpen, ha két elemre a múltban hasonlóan reagáltak a felhasználók, akkor valószínűleg hasonlóak egymáshoz.
Két fő alkategóriája van:
a) Felhasználó-alapú kollaboratív szűrés (User-Based CF)
Ez a módszer az „hasonló felhasználók” elvén alapul. A rendszer megkeresi azokat a felhasználókat, akik a célfelhasználóhoz hasonló ízléssel vagy viselkedéssel rendelkeznek (pl. hasonlóan értékeltek filmeket, hasonló termékeket vásároltak). Amint megtalálta ezeket a „szomszédokat”, a rendszer a célfelhasználónak olyan elemeket ajánl, amelyeket a szomszédok kedveltek, de a célfelhasználó még nem ismer.
- Működése:
- Kiszámítja a hasonlóságot a felhasználók között (pl. Pearson korreláció, koszinusz hasonlóság).
- Kiválasztja a célfelhasználó legközelebbi N szomszédját.
- Javaslatokat generál a szomszédok által kedvelt, de a célfelhasználó által még nem látott elemekből.
- Előnyei: Nem igényel elemjellemzőket, képes meglepő (serendipitous) javaslatokat tenni.
- Hátrányai:
- Hidegindítási probléma (Cold Start): Nehéz új felhasználók számára javaslatokat tenni, akiknek még nincs elegendő interakciójuk.
- Ritkaság (Sparsity): Ha a felhasználó-elem mátrix túl ritkás, nehéz megbízható hasonlóságokat találni.
- Méretezhetőség (Scalability): Nagy felhasználói bázis esetén a hasonlósági számítások rendkívül erőforrásigényesek lehetnek.
b) Elem-alapú kollaboratív szűrés (Item-Based CF)
Ez a módszer az „hasonló elemek” elvén alapul. A rendszer megkeresi azokat az elemeket, amelyek hasonlóak azokhoz az elemekhez, amelyeket a célfelhasználó a múltban kedvelt. Az elemek hasonlóságát az alapján határozzák meg, hogy a felhasználók mennyire hasonlóan reagáltak rájuk.
- Működése:
- Kiszámítja a hasonlóságot az elemek között (pl. koszinusz hasonlóság a felhasználói értékelések alapján).
- A célfelhasználó által kedvelt elemekhez keres hasonló elemeket.
- Javasolja azokat a hasonló elemeket, amelyeket a felhasználó még nem látott.
- Előnyei: Jobb méretezhetőség, mint a felhasználó-alapú CF, mivel az elemek közötti hasonlóság viszonylag stabil, és offline is előre kiszámítható. Kevésbé érzékeny az új felhasználókra.
- Hátrányai:
- Hidegindítási probléma (Cold Start): Nehéz új elemek számára javaslatokat tenni, amiknek még nincsenek interakcióik.
- Kisebb a serendipity esélye, mivel a javaslatok a már kedvelt elemekhez hasonlítanak.
A kollaboratív szűrésnek léteznek memória-alapú (a fenti felhasználó- és elem-alapú megközelítések) és modell-alapú változatai is. A modell-alapú CF (pl. mátrix faktorizáció, SVD, ALS) gépi tanulási modelleket épít az adatokból, hogy rejtett jellemzőket (latent factors) fedezzen fel, amelyek jobban kezelik a ritkaságot és a méretezhetőséget.
2. Tartalomalapú szűrés (Content-Based Filtering – CBF)
A tartalomalapú szűrés a felhasználó korábbi preferenciáiból és az elemek jellemzőiből tanul. Ahelyett, hogy más felhasználókra támaszkodna, ez a módszer egyedi „profilt” épít minden felhasználó számára, amely leírja az érdeklődési körét az általa korábban kedvelt elemek jellemzői alapján.
- Működése:
- Minden elemről kinyeri a jellemzőket (pl. filmeknél: műfaj, rendező, kulcsszavak; termékeknél: kategória, márka, leírás).
- Létrehoz egy felhasználói profilt a korábban kedvelt elemek jellemzőinek aggregálásával (pl. átlagolás, súlyozás).
- Javaslatokat generál olyan elemekből, amelyek jellemzői hasonlítanak a felhasználói profilra.
- Előnyei:
- Nincs hidegindítási probléma új elemekkel: Amint egy új elem jellemzői rendelkezésre állnak, azonnal ajánlható.
- Nincs hidegindítási probléma ritkás adatokkal: Nem függ más felhasználók interakcióitól.
- Képes javaslatokat adni egyedi ízlésű felhasználóknak.
- Könnyen magyarázható, miért ajánlott egy adott elem (pl. „mert szereted a sci-fit és a Christopher Nolan filmeket”).
- Hátrányai:
- Túl-specializáció (Over-specialization): A felhasználó csak a korábbi preferenciáihoz nagyon hasonló elemeket kap, nehéz új dolgokat felfedezni.
- Korlátozott tartalomanalízis: A javaslatok minősége nagyban függ az elemek jellemzőinek gazdagságától és pontosságától.
- „Nincs új elem” probléma új felhasználókkal: Ha egy felhasználónak még nincs elegendő interakciója, nehéz profilt építeni.
3. Hibrid ajánlórendszerek (Hybrid Recommendation Systems)
Ahogy a neve is sugallja, a hibrid rendszerek több ajánlási módszert kombinálnak, hogy kiküszöböljék az egyes megközelítések gyengeségeit és kihasználják az erősségeiket. Ez a megközelítés gyakran jobb teljesítményt nyújt, mint bármelyik önálló módszer.
Néhány gyakori kombinációs stratégia:
- Súlyozott hibrid (Weighted Hybrid): Egyszerűen kombinálja a különböző rendszerek eredményeit súlyozott átlaggal.
- Kapcsoló hibrid (Switching Hybrid): Választ egy módszert a helyzettől függően (pl. ha kevés interakció van, tartalomalapút használ; ha sok, kollaboratívat).
- Vegyes hibrid (Mixed Hybrid): Az eredményeket egymás mellé helyezi, pl. egy listán belül.
- Kaszkád hibrid (Cascade Hybrid): Az egyik rendszer eredményeit bemenetként használja a másik számára.
- Jellemző kiterjesztés (Feature Augmentation): Az egyik rendszer által generált jellemzőket a másik rendszer bemeneteként használja.
A hibrid rendszerek képesek kezelni a hidegindítási problémát (pl. új felhasználóknak tartalomalapú ajánlásokat adnak, új elemeknek pedig a tartalmuk alapján), és javítják a javaslatok minőségét és sokféleségét.
4. Tudásalapú rendszerek (Knowledge-Based Systems)
Ezek a rendszerek explicit domain tudásra és a felhasználó igényeinek pontos megértésére támaszkodnak. Nem a felhasználói viselkedést elemzik, hanem a felhasználó által megadott preferenciákat (pl. „keresek egy 3 hálószobás lakást a belvárosban, 1000 euró alatt”).
- Előnyei: Kezeli a hidegindítási problémát, magyarázható javaslatokat ad.
- Hátrányai: Nehéz a tudásbázis felépítése és karbantartása, a felhasználóknak sok információt kell megadniuk.
5. Demográfiai alapú rendszerek (Demographic-Based Systems)
Ez a típus a felhasználó demográfiai jellemzői (kor, nem, földrajzi hely, foglalkozás stb.) alapján ad javaslatokat. Feltételezi, hogy a hasonló demográfiai jellemzőkkel rendelkező felhasználók hasonló preferenciákkal rendelkeznek.
- Előnyei: Egyszerű implementáció, kezeli a hidegindítási problémát.
- Hátrányai: Túlzottan leegyszerűsítő, nem biztosít személyre szabott ajánlásokat, adatvédelmi aggályok merülhetnek fel.
A gyakorlatban a legtöbb modern ajánlórendszer valamilyen hibrid megközelítést alkalmaz, gyakran mélytanulási technikákkal kiegészítve, hogy a lehető legpontosabb és legrelevánsabb javaslatokat nyújtsa.
Az ajánlórendszerek életciklusa és kulcsfontosságú komponensei
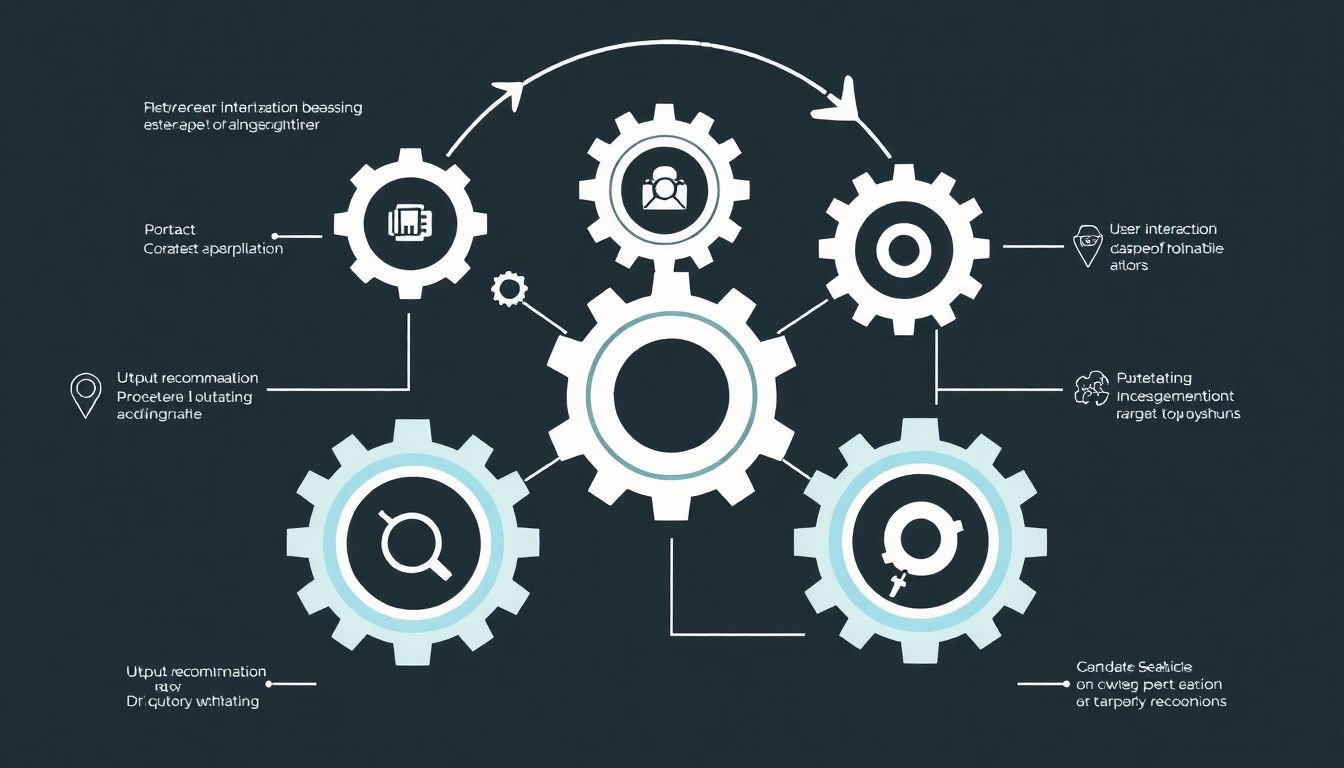
Egy robusztus ajánlórendszer fejlesztése és üzemeltetése nem egy egyszeri feladat, hanem egy folyamatos ciklus, amely több szakaszból áll. Az alábbiakban bemutatjuk az ajánlórendszer életciklusát és a benne részt vevő kulcsfontosságú komponenseket.
1. Adatgyűjtés
Ez az első és talán legfontosabb lépés. Ahogy korábban tárgyaltuk, az ajánlórendszerek a felhasználói interakciókból, elemjellemzőkből és kontextuális adatokból táplálkoznak. Ennek a fázisnak magában kell foglalnia az explicit és implicit adatok megbízható és skálázható gyűjtését. Ez történhet weboldalanalitikán keresztül, adatbázisokból, API-kon keresztül, vagy akár közvetlen felhasználói bevitel útján.
- Adatforrások:
- Felhasználói profilok (demográfiai adatok, preferenciák)
- Interakciós adatok (kattintások, nézések, vásárlások, értékelések, keresések)
- Elemek attribútumai (műfaj, kategória, leírás, ár, márka)
- Kontextuális adatok (idő, helyszín, eszköz)
- Technológiák: Adatbázisok (SQL, NoSQL), adatfolyam feldolgozó rendszerek (Kafka), adatgyűjtő szkriptek.
2. Adat előfeldolgozás és jellemzők kinyerése (Feature Engineering)
A nyers adatok ritkán alkalmasak közvetlenül az algoritmusok számára. Ez a szakasz magában foglalja az adatok tisztítását, transzformálását és strukturálását. Ide tartozik a hiányzó értékek kezelése, a zaj szűrése, az adatok normalizálása, és a releváns jellemzők kinyerése.
- Feladatok:
- Adattisztítás (duplikátumok, hibás bejegyzések eltávolítása)
- Hiányzó adatok pótlása vagy kezelése
- Adat normalizálás/skálaillesztés
- Szöveges adatok feldolgozása (NLP: tokenizálás, stemming, lemmatizálás, TF-IDF, word embeddings)
- Kategóriás változók kódolása (one-hot encoding)
- Új, releváns jellemzők létrehozása meglévő adatokból.
- Kimenet: Modellre alkalmas, tiszta és strukturált adathalmaz.
3. Modellkiválasztás és képzés
Ebben a fázisban választják ki a megfelelő ajánló algoritmust (vagy algoritmusokat hibrid rendszerek esetén), majd betanítják azt az előkészített adatokon. A modell „tanulja” a mintázatokat a felhasználói interakciókból és az elemek jellemzőiből, hogy képes legyen predikciókat tenni.
- Algoritmusok:
- Kollaboratív szűrés (felhasználó-alapú, elem-alapú, mátrix faktorizáció)
- Tartalomalapú szűrés (koszinusz hasonlóság, gépi tanulási besorolók)
- Hibrid megközelítések
- Mélytanulási modellek (RNN, CNN, GNN, Transformer alapú modellek)
- Képzési folyamat:
- Adathalmaz felosztása képzési, validációs és tesztelési halmazokra.
- Modell paramétereinek hangolása (hyperparameter tuning).
- Az optimalizációs algoritmus kiválasztása.
4. Ajánlásgenerálás és rangsorolás
Miután a modell betanult, képes javaslatokat generálni. Ez magában foglalja a felhasználó és az elemek közötti pontszámok predikcióját, majd ezen pontszámok alapján a legrelevánsabb elemek kiválasztását és rangsorolását.
- Predikció: Becsült értékelés vagy valószínűség, hogy a felhasználó interakcióba lép egy adott elemmel.
- Rangsorolás: A predikált pontszámok alapján az elemek sorba rendezése a felhasználó számára.
- Szűrés: Már látott vagy nem releváns elemek kiszűrése.
- Diverzitás és újdonság: Az ajánlások sokféleségének és újdonságának figyelembe vétele a relevancián túl.
5. Szolgáltatásba állítás (Deployment)
A betanított modell integrálása az élő rendszerbe, például egy weboldalba, mobilalkalmazásba vagy API-ba. Ez a fázis biztosítja, hogy a valós idejű felhasználói interakciók alapján azonnal elérhetőek legyenek az ajánlások.
- Technológiák: Felhőalapú platformok (AWS, Google Cloud, Azure), konténerizáció (Docker, Kubernetes), API Gateway-ek.
- Valós idejű ajánlások: Képesnek kell lennie gyorsan reagálni az új felhasználói adatokra.
6. Értékelés és monitoring
Az ajánlórendszer teljesítményének folyamatos nyomon követése és értékelése elengedhetetlen a hatékonyság biztosításához és a jövőbeni fejlesztések irányának meghatározásához. Ez történhet offline metrikák (precízió, recall, RMSE) és online A/B tesztek segítségével.
- Offline metrikák:
- Precizitás (Precision): Hány ajánlott elem volt releváns.
- Recall (Visszahívás): A releváns elemek hány százalékát ajánlotta a rendszer.
- F1-score: A precízió és a recall harmonikus átlaga.
- RMSE (Root Mean Squared Error): Az előrejelzési hibák mértéke értékelési rendszereknél.
- MAP (Mean Average Precision): Rangsorolt listák értékelésére.
- NDCG (Normalized Discounted Cumulative Gain): A releváns elemek pozícióját is figyelembe veszi.
- Online metrikák (A/B tesztelés):
- Átkattintási arány (Click-Through Rate – CTR): Hányan kattintottak az ajánlásokra.
- Konverziós arány (Conversion Rate): Hányan vásároltak vagy hajtottak végre kívánt műveletet az ajánlás alapján.
- Időráfordítás: Mennyivel több időt töltenek a felhasználók a platformon.
- Kosár mérete: Nőtt-e az átlagos kosárérték.
- Felhasználói elégedettség: Közvetlen visszajelzések alapján.
- Folyamatos tanulás és frissítés: Az új adatokkal a modell folyamatosan újra betanítható (retraining) vagy adaptálható (online learning).
Ez a ciklus iteratív jellegű. Az értékelés során szerzett tapasztalatok visszajelzést adnak a korábbi fázisoknak, lehetővé téve az adatok gyűjtésének, az előfeldolgozásnak, az algoritmusoknak és a rendszer egészének folyamatos optimalizálását.
Kihívások és korlátok az ajánlórendszerekben
Bár az ajánlórendszerek rendkívül hatékonyak, számos kihívással és korláttal szembesülnek, amelyek befolyásolhatják teljesítményüket és a felhasználói élményt.
1. Hidegindítási probléma (Cold Start Problem)
Ez az egyik leggyakoribb kihívás, amely két fő formában jelentkezik:
- Új felhasználó hidegindítása (New User Cold Start): Amikor egy új felhasználó csatlakozik a rendszerhez, még nincs elegendő interakciós adata ahhoz, hogy a kollaboratív szűrés releváns javaslatokat tegyen.
- Új elem hidegindítása (New Item Cold Start): Amikor egy új termék vagy tartalom kerül be a rendszerbe, még nincs elegendő felhasználói interakciója ahhoz, hogy a kollaboratív szűrés javasolja.
Megoldások:
- Népszerűségi alapú ajánlások: Kezdetben a legnépszerűbb vagy legújabb elemek ajánlása.
- Demográfiai alapú ajánlások: A felhasználó demográfiai adatai alapján.
- Tartalomalapú szűrés: Új elemek esetén a jellemzőik (pl. műfaj, leírás) alapján.
- Hibrid rendszerek: Kombinálva a különböző megközelítéseket.
- Explicit visszajelzés kérése: Regisztrációkor kérdezze meg a felhasználó preferenciáit.
2. Adatritkaság (Sparsity)
A felhasználó-elem interakciós mátrixok általában rendkívül ritkásak, ami azt jelenti, hogy a felhasználók az összes elemnek csak töredékével lépnek interakcióba. Ez megnehezíti a megbízható mintázatok felfedezését, különösen a kollaboratív szűrési algoritmusok számára.
Megoldások:
- Mátrix faktorizációs technikák: Rejtett jellemzők felfedezésével sűrítik a mátrixot.
- Dimenziócsökkentés: Az adatok relevánsabb és sűrűbb reprezentációjának létrehozása.
- Implicit visszajelzések felhasználása: A kattintások, nézések, görgetések stb. mint interakciók figyelembevétele.
3. Méretezhetőség (Scalability)
Nagy felhasználói bázisok és hatalmas elemkatalógusok esetén az ajánlórendszereknek képesnek kell lenniük valós időben, nagy mennyiségű adatot feldolgozni és javaslatokat generálni. A hagyományos algoritmusok számítási költségei exponenciálisan növekedhetnek.
Megoldások:
- Elosztott számítási rendszerek: Hadoop, Spark.
- Hatékony algoritmusok: Modell-alapú kollaboratív szűrés, mélytanulási modellek.
- Offline előszámítás: A javaslatok egy részének vagy a modellnek az előzetes kiszámítása.
- Inkrementális tanulás: A modell folyamatos frissítése új adatokkal, anélkül, hogy az egészet újra kellene tanítani.
4. Diverzitás, újdonság és serendipity
Egy hatékony ajánlórendszernek nemcsak releváns, hanem változatos (diverz), új (novel) és meglepő (serendipitous) ajánlásokat is kell tennie. A túlzottan releváns ajánlások „szűrőbuborékokhoz” vezethetnek, ahol a felhasználó csak a már ismert preferenciái megerősítését kapja.
- Diverzitás: Az ajánlott elemek közötti különbség mértéke.
- Újdonság: Olyan elemek ajánlása, amelyeket a felhasználó valószínűleg még nem ismer.
- Serendipity (Meglepetés): Olyan elemek ajánlása, amelyek a felhasználó számára érdekesek, de nem feltétlenül illeszkednek a korábbi preferenciáihoz.
Megoldások:
- Véletlenszerűség bevezetése: Kis mértékű véletlenszerűség a rangsorolásban.
- Többféle algoritmus kombinálása: Hibrid rendszerek.
- Diverzitás metrikák optimalizálása: A relevancia mellett a diverzitást is figyelembe vevő rangsorolás.
5. Magyarázhatóság (Explainability)
A felhasználók gyakran szeretnék tudni, hogy miért kaptak egy adott ajánlást. A „fekete doboz” algoritmusok, különösen a mélytanulási modellek, nehezen magyarázhatók. A magyarázhatóság növeli a felhasználói bizalmat és elégedettséget.
Megoldások:
- Jellemző alapú magyarázatok: „Ez a film azért ajánlott, mert szereted a sci-fit és a rendező Christopher Nolan.”
- Hasonló felhasználók: „Azok a felhasználók is kedvelték, akik hasonlóan értékeltek más filmeket.”
- Interaktív felületek: Lehetővé teszik a felhasználóknak, hogy finomhangolják preferenciáikat.
6. Adatvédelmi aggályok és etikai kérdések
Az ajánlórendszerek nagymennyiségű felhasználói adatot gyűjtenek és elemeznek, ami komoly adatvédelmi és etikai aggályokat vet fel. A felhasználók bizalma elveszhet, ha úgy érzik, hogy adataikat nem megfelelően kezelik, vagy manipulálják őket.
- Személyes adatok védelme: GDPR és más adatvédelmi szabályozások betartása.
- Algoritmikus torzítás (Bias): Az adatokban meglévő torzítások felerősítése, ami igazságtalan vagy diszkriminatív ajánlásokhoz vezethet.
- Visszacsatolási hurkok (Feedback Loops): A rendszer önmagát erősítő hurokba kerülhet, ahol csak azokat az elemeket ajánlja, amelyek már népszerűek, és ezzel tovább növeli népszerűségüket.
- Manipuláció és „shilling” támadások: Rosszindulatú felhasználók megpróbálhatják manipulálni az értékeléseket.
Megoldások:
- Adatminimalizálás és anonimizálás.
- Torzítás detektálása és korrekciója az adatokban és algoritmusokban.
- Transzparencia a felhasználói adatok kezelésében.
- Robusztus algoritmikus védelem a csalások ellen.
Ezeknek a kihívásoknak a kezelése folyamatos kutatást és fejlesztést igényel az ajánlórendszerek területén, hogy a rendszerek ne csak hatékonyak, hanem etikusan és felelősségteljesen is működjenek.
Fejlett technikák és a jövő trendjei az ajánlórendszerekben
Az ajánlórendszerek területe dinamikusan fejlődik, folyamatosan jelennek meg új algoritmusok és megközelítések. A mélytanulás, a kontextustudatos rendszerek és az etikai megfontolások egyre inkább előtérbe kerülnek.
1. Mélytanulás az ajánlórendszerekben (Deep Learning for Recommender Systems)
A mélytanulási modellek, különösen a neurális hálózatok, forradalmasították az ajánlórendszereket azáltal, hogy képesek komplex, nemlineáris mintázatokat felismerni hatalmas és ritkás adathalmazokban. Képesek automatikusan jellemzőket kinyerni, és felülmúlják a hagyományos módszereket bizonyos feladatokban.
- Főbb mélytanulási architektúrák:
- Többrétegű perceptronok (MLP): Rejtett rétegekkel képesek komplex interakciókat modellezni.
- Rekurrens neurális hálózatok (RNN) és Long Short-Term Memory (LSTM): Időfüggő adatokhoz, például szekvenciális felhasználói viselkedés modellezéséhez (pl. session-alapú ajánlások).
- Konvolúciós neurális hálózatok (CNN): Képek, szövegek és más strukturált adatok jellemzőinek kinyerésére használhatók az elemekről.
- Grafikus neurális hálózatok (GNN): A felhasználó-elem interakciókat gráfként modellezik, és képesek a felhasználók és elemek közötti komplex kapcsolatok feltárására.
- Transzformerek (Transformers): Természetes nyelvi feldolgozásból (NLP) adaptálva, kiválóan alkalmasak szekvenciális adatok, például felhasználói böngészési előzmények modellezésére.
- Előnyök:
- Jobb pontosság és relevancia.
- Képesek automatikusan tanulni a jellemzőket (feature learning).
- Hatékonyabbak a ritkaság és a hidegindítási probléma kezelésében bizonyos esetekben.
- Hátrányok:
- Magas számítási igény.
- Nehezebben magyarázható „fekete doboz” modellek.
- Nagyobb adathalmazt igényelnek a hatékony tanuláshoz.
2. Kontextustudatos ajánlórendszerek (Context-Aware Recommender Systems – CARS)
A hagyományos ajánlórendszerek gyakran figyelmen kívül hagyják a felhasználó és az elem közötti interakció kontextusát (pl. napszak, helyszín, eszköz, hangulat, időjárás, társaság). A kontextustudatos rendszerek figyelembe veszik ezeket a tényezőket, hogy pontosabb és relevánsabb javaslatokat tegyenek.
- Példák kontextusra:
- Idő: Reggel híreket, este filmeket ajánl.
- Helyszín: Étterem ajánlása a közelben.
- Társaság: Film ajánlása barátokkal nézve vs. egyedül.
- Eszköz: Mobilról böngészve más ajánlatok, mint asztali gépről.
- Módszerek: Kontextuális adatok beépítése a jellemzőkbe, vagy külön kontextuális modellek alkalmazása.
3. Szekvencia-alapú és munkamenet-alapú ajánlások (Session-Based Recommendations)
Ezek a rendszerek a felhasználó aktuális munkamenetét (session) elemzik, nem feltétlenül a teljes előzményét. Különösen hasznosak, ha a felhasználónak nincs hosszú története, vagy ha a preferenciák gyorsan változnak egy munkamenet során (pl. online vásárlás, hírolvasás).
- Modellek: Gyakran használnak RNN-eket vagy transzformereket a munkameneten belüli sorrendi információk rögzítésére.
- Alkalmazások: E-kereskedelem („Ön is megtekintette…”), híroldalak („Olvassa el ezeket is…”).
4. Megerősítő tanulás az ajánlórendszerekben (Reinforcement Learning – RL)
A megerősítő tanulás egy olyan gépi tanulási paradigma, ahol egy „ügynök” interakcióba lép egy „környezettel”, és a cselekvéseiért jutalmat vagy büntetést kap. Az ajánlórendszerekben ez azt jelenti, hogy a rendszer „ügynökként” funkcionál, amely ajánlásokat tesz (cselekvések), és a felhasználói visszajelzések (kattintás, vásárlás) alapján „jutalmat” kap. Ez a megközelítés lehetővé teszi a rendszer számára, hogy folyamatosan tanuljon és alkalmazkodjon a felhasználói viselkedéshez valós időben, maximalizálva a hosszú távú jutalmat (pl. felhasználói elkötelezettség).
- Előnyök: Optimalizálja a hosszú távú felhasználói élményt, képes felfedezni (explore) új elemeket a kizsákmányolás (exploit) mellett.
- Kihívások: Komplex modellek, nagy számítási igény, a jutalomfüggvény meghatározása.
5. Etikai AI és torzításmentes ajánlások (Fairness and Bias in Recommender Systems)
Ahogy az ajánlórendszerek egyre nagyobb hatással vannak mindennapi életünkre, egyre fontosabbá válik az algoritmusok etikai aspektusa. A torzítás (bias) megjelenhet az adatokban (pl. történelmi előítéletek), az algoritmusban (pl. bizonyos csoportok alulreprezentálása), vagy a felhasználói interakciókban (pl. a népszerű elemek további felerősítése). A cél a méltányos, inkluzív és átlátható ajánlórendszerek fejlesztése.
- Kutatási területek: Torzítás detektálása és mérséklése, méltányosság metrikák, magyarázható AI (XAI).
- Cél: Elkerülni a „szűrőbuborékok” és az „echo chambers” kialakulását, amelyek korlátozzák a felhasználók nézőpontját és potenciálisan polarizálhatják a véleményeket.
6. Kereshető és interaktív ajánlórendszerek
A jövő ajánlórendszerei valószínűleg nem csak javaslatokat tesznek, hanem lehetővé teszik a felhasználók számára, hogy aktívan finomhangolják a keresést és az ajánlásokat. Ez magában foglalhatja a természetes nyelvi interakciót, ahol a felhasználók elmondhatják preferenciáikat, vagy visszajelzést adhatnak az ajánlásokról.
Az ajánlórendszerek folyamatosan fejlődnek, integrálva az MI, a gépi tanulás és az adatfeldolgozás legújabb vívmányait. A cél továbbra is az, hogy a felhasználók számára a lehető legrelevánsabb, legváltozatosabb és legélvezetesebb élményt nyújtsák, miközben az üzleti célokat is hatékonyan szolgálják.