

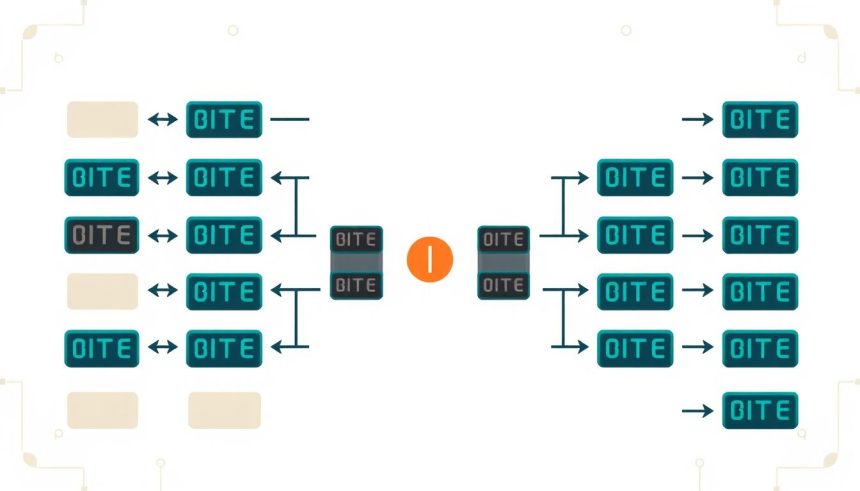
Mi is az Endianness, avagy a Bájt Sorrendiség?
A számítástechnika mélyebb rétegeibe merülve számos olyan alapvető koncepcióval találkozhatunk, amelyek a mindennapi felhasználók számára láthatatlanok maradnak, mégis kulcsfontosságúak a rendszerek működéséhez és az adatok integritásához. Az egyik ilyen alapvető, mégis gyakran félreértett vagy figyelmen kívül hagyott fogalom az endianness, vagy magyarul a bájt sorrendiség. Ez a jelenség azt írja le, hogy egy számítógépes rendszer hogyan tárolja a több bájtos adatokat – például egész számokat, lebegőpontos számokat vagy memóriacímeket – a memóriájában.
Amikor egyetlen bájtnyi adatot kezelünk, a sorrendiség kérdése irreleváns, hiszen egy bájt önmagában egy atymai egység. Azonban amint egy adatot több bájttal kell reprezentálni (például egy 16 bites, 32 bites vagy 64 bites számot), azonnal felmerül a kérdés: melyik bájt kerüljön előre a memóriában, és melyik utoljára? A legértékesebb bájt (MSB – Most Significant Byte) vagy a legkevésbé értékes bájt (LSB – Least Significant Byte)? Ez a döntés alapvetően befolyásolja az adatok értelmezését és feldolgozását, különösen akkor, ha különböző architektúrájú rendszerek között történik adatcsere.
Az endianness fogalma a számítógép architektúrájához kötődik, és közvetlenül befolyásolja a processzorok memóriakezelési módját. Két fő típusa létezik, amelyek alapvetően eltérő logikát követnek az adatok tárolásakor és olvasásakor. Ezek a Big-Endian és a Little-Endian sorrendiségek. A különbség megértése elengedhetetlen a rendszerek közötti kompatibilitás biztosításához, a hálózati kommunikáció megfelelő működéséhez, és a bináris fájlok helyes értelmezéséhez.
A Két Fő Típus: Big-Endian és Little-Endian
Az endianness két alapvető formája a számítástechnikában a Big-Endian és a Little-Endian. Mindkettő az adatok bájtsorrendjét határozza meg a memóriában, de ellentétes logikát követnek.
Big-Endian (Nagy-Endián)
A Big-Endian sorrendiség azt jelenti, hogy a legértékesebb bájt (MSB) kerül először a memóriába, a legalacsonyabb memóriacímen. Ez a megközelítés hasonlít ahhoz, ahogyan az emberek általában leírnak egy számot: balról jobbra, a legmagasabb helyiértékkel kezdve. Például az 12345678 (hexadecimális) számot Big-Endian rendszerben a memóriában a következőképpen tárolnák:
- Cím N: 12
- Cím N+1: 34
- Cím N+2: 56
- Cím N+3: 78
Itt a „12” a legértékesebb bájt, és ez van a legalacsonyabb memóriacímen. Ez a sorrend intuitívabb lehet az emberi olvasás szempontjából, mivel a legfontosabb rész van elöl.
Történelmileg számos nagy rendszert, például az IBM System/360, a Motorola 68k sorozat, és a PowerPC processzorok többségét Big-Endianként tervezték. Ezenkívül a hálózati protokollok, mint például a TCP/IP, szinte kivétel nélkül a Big-Endian sorrendet használják, amelyet „hálózati bájt sorrendnek” is neveznek. Ez a konzisztencia kulcsfontosságú a hálózati kommunikáció megbízhatóságához, függetlenül a kommunikáló gépek belső endianness-étől.
Little-Endian (Kis-Endián)
Ezzel szemben a Little-Endian sorrendiség azt jelenti, hogy a legkevésbé értékes bájt (LSB) kerül először a memóriába, a legalacsonyabb memóriacímen. Ez a megközelítés kevésbé intuitívnak tűnhet az emberi olvasás szempontjából, de bizonyos hardverarchitektúrák számára hatékonyabb lehet.
Ugyanazt az 12345678 (hexadecimális) számot Little-Endian rendszerben a memóriában a következőképpen tárolnák:
- Cím N: 78
- Cím N+1: 56
- Cím N+2: 34
- Cím N+3: 12
Itt a „78” a legkevésbé értékes bájt, de ez van a legalacsonyabb memóriacímen. A „12” a legértékesebb bájt, és ez van a legmagasabb címen.
A Little-Endian sorrendet az Intel x86 architektúra népszerűsítette, amely a modern személyi számítógépek és szerverek domináns processzora. Ennek következtében a legtöbb asztali számítógép és számos szerver Little-Endian rendszert használ. Ennek egyik feltételezett előnye, hogy a memóriában történő inkrementális hozzáférés (pl. bájt-bájtonkénti olvasás) egyszerűbbé válik, mivel a legkevésbé értékes bájt azonnal elérhető. Ez leegyszerűsítheti a változó hosszúságú számok kezelését vagy a típuskonverziót.
Miért Két Különböző Típus?
A két különböző bájt sorrendiség kialakulásának okai a számítógép-tervezés korai szakaszára nyúlnak vissza. Nincs egyértelműen „jobb” vagy „rosszabb” sorrendiség; mindkettőnek megvannak a maga technikai előnyei és hátrányai, attól függően, hogy a processzor tervezői milyen optimalizációkat tartottak fontosnak.
A Little-Endian architektúrákban könnyebb a memóriában lévő számokhoz hozzáférni és velük aritmetikai műveleteket végezni, ha a processzor a legkevésbé jelentős bájttal kezdi az olvasást. Például, ha egy 32 bites számot 16 bites regiszterekbe töltünk be, a Little-Endian rendszerben egyszerűen olvasható a szám alsó 16 bitje anélkül, hogy a felső 16 bitet is be kellene olvasni. Ez egyes műveleteknél, például a címek inkrementális számításánál, hatékonyabb lehet.
A Big-Endian architektúrák viszont a hálózati kommunikációban és a fájlformátumokban bizonyultak előnyösnek, mivel az emberi olvasáshoz hasonló sorrend miatt könnyebb a hibakeresés és az adatok interpretálása bináris dumpokban. Ez a „természetesebb” sorrend segíti a protokollok szabványosítását.
Az endianness alapvető jelentősége abban rejlik, hogy meghatározza a több bájtos adatok memóriabeli reprezentációját, és ezáltal kritikus a különböző rendszerek közötti adatcsere, a hálózati kommunikáció, valamint a bináris fájlok helyes értelmezése szempontjából. Ennek figyelmen kívül hagyása súlyos adatkorrupcióhoz vagy programhibákhoz vezethet.
Az Endianness Történelmi Gyökerei és Eredete
Az „endianness” kifejezés meglepő módon nem a számítástechnikából, hanem az irodalomból származik. Jonathan Swift 1726-ban írt szatirikus regényéből, a Gulliver utazásaiból ered, pontosabban a Lilliput és Blefuscu közötti háborúból, amely azon alapult, hogy az emberek melyik végén törjék fel a főtt tojást: a „Big-Endians” a nagy végén, a „Little-Endians” a kis végén. Ezt a metaforát Daniel Cohen 1980-ban alkalmazta a számítástechnikára, hogy leírja a bájtok sorrendjével kapcsolatos vitát.
A számítógépek hajnalán, amikor a különböző architektúrák kialakultak, nem volt egyetemes szabvány az adatok memóriabeli tárolására. Minden tervezőcsapat a saját belátása szerint döntötte el, hogy a processzoruk hogyan kezelje a több bájtos adatokat. Ez a független fejlődés vezetett a Big-Endian és Little-Endian rendszerek párhuzamos létezéséhez.
Korai Architektúrák és Döntések
- Big-Endian dominancia: Az első számítógépek, mint például az IBM 360 család, a PDP-10, és később a Motorola 68k sorozat, mind Big-Endian architektúrát használtak. Ezek a rendszerek gyakran nagy, mainframe és minicomputer környezetekben működtek, ahol a hálózati kommunikáció és a külső eszközökkel való adatcsere már korán kulcsfontosságúvá vált. A Big-Endian sorrend „hálózati bájt sorrendként” való elfogadása is hozzájárult a dominanciájához ezen a területen.
- Little-Endian felemelkedése: Az Intel x86 architektúra megjelenésével és elterjedésével a Little-Endian sorrendiség rendkívül népszerűvé vált. Az x86-os processzorok a személyi számítógépek forradalmának motorjai voltak, és az elmúlt évtizedekben uralták a piacot. Az Intel döntése a Little-Endian mellett valószínűleg a processzor belső működésének optimalizálásán alapult, különösen a címek és a mutatók kezelésénél, ahol a legkevésbé értékes bájthoz való gyors hozzáférés előnyt jelenthetett.
A kétféle sorrendiség közötti választás gyakran a mérnöki kompromisszumok eredménye volt. Egyesek szerint a Big-Endian „természetesebb” és könnyebben debugolható, míg mások a Little-Endian belső hatékonyságát hangsúlyozták. Az eredmény egy olyan heterogén világ lett, ahol a szoftverfejlesztőknek és rendszeradminisztrátoroknak folyamatosan figyelembe kell venniük ezt a különbséget, amikor adatokkal dolgoznak különböző platformokon.
Bi-Endian vagy Mixed-Endian Processzorok
Az idő múlásával és a rendszerkompatibilitási igények növekedésével megjelentek olyan processzorok is, amelyek képesek voltak mindkét bájt sorrendiséget kezelni. Ezeket Bi-Endian vagy Mixed-Endian processzoroknak nevezik. Például a PowerPC architektúra, az ARM, a MIPS és a RISC-V is támogatja mindkét módot, és a rendszerindításkor vagy futásidőben konfigurálható, hogy Big-Endian vagy Little-Endian módban működjön.
Ez a rugalmasság különösen hasznos a beágyazott rendszerek és a hálózati eszközök fejlesztésében, ahol gyakran kell kommunikálni Big-Endian hálózati protokollokkal és Little-Endian perifériákkal. A Bi-Endian képesség lehetővé teszi a fejlesztők számára, hogy a processzort a legmegfelelőbb módba állítsák a teljesítmény és a kompatibilitás optimalizálása érdekében, minimalizálva a manuális bájtcserék szükségességét.
Ez a történelmi áttekintés rávilágít arra, hogy az endianness nem egy elavult koncepció, hanem egy mélyen gyökerező aspektusa a számítógép-architektúráknak, amely a mai napig hatással van a szoftverfejlesztésre és a rendszerek közötti adatcserére.
Endianness a Gyakorlatban: Hol Találkozunk Vele?
Az endianness nem csupán elméleti fogalom; a mindennapi számítástechnikai feladatok számos területén megjelenik, gyakran észrevétlenül, amíg valamilyen kompatibilitási probléma nem merül fel. Megértése kulcsfontosságú a robusztus és hordozható szoftverek fejlesztéséhez.
Memória Reprezentáció és CPU Regiszterek
Amikor egy program egy több bájtos változót deklarál (pl. egy 32 bites int), a processzor és az operációs rendszer az adott architektúra endianness-ének megfelelően tárolja azt a memóriában. Ha egy 32 bites számot egy 64 bites regiszterbe töltünk be, a processzor belsőleg a saját endianness-ének megfelelően kezeli a bájtokat. Ez általában transzparens a programozó számára, amíg a program csak az adott rendszeren belül működik. A problémák akkor kezdődnek, ha az adatok átkerülnek egy másik, eltérő endianness-ű rendszerre, vagy ha közvetlenül a memória bájtsorrendjével kell dolgozni.
Például, ha egy Little-Endian rendszeren futó program egy memóriacímet olvas, ahol egy Big-Endian rendszer által írt 32 bites egész szám van, az olvasott érték teljesen hibás lesz. A bájtok fordított sorrendben fognak megjelenni, ami azt eredményezi, hogy a számot teljesen másként értelmezi a processzor.
Adattárolás Fájlokban
A bináris fájlok, mint például a képek (JPEG, TIFF, BMP), hangfájlok (WAV, AIFF), videók, vagy programok futtatható állományai (ELF, PE), gyakran tartalmaznak több bájtos metaadatokat vagy tényleges adatokat (pl. képfelbontás, színmélység, mintavételi frekvencia, fájlméret, mutatók). Ezeknek a fájlformátumoknak szigorúan meg kell határozniuk, hogy milyen bájt sorrendiséggel tárolják az adatokat, hogy a különböző rendszereken is helyesen lehessen őket olvasni.
- TIFF (Tagged Image File Format): A TIFF fájlok különösen érdekesek ebből a szempontból, mivel a fájl fejlécében egy „byte order” mező található, amely jelzi, hogy a fájl Big-Endian vagy Little-Endian sorrendben tárolja-e az adatokat. Ez lehetővé teszi a TIFF fájlok hordozhatóságát különböző rendszerek között, mivel a fájl olvasója dinamikusan alkalmazkodni tud a belső bájt sorrendhez.
- WAV (Waveform Audio File Format): A WAV fájlok általában Little-Endian sorrendben tárolják az adatokat, mivel a Microsoft és az Intel rendszerei domináltak a fejlesztésük idején.
- ELF (Executable and Linkable Format): Az ELF futtatható fájlformátum, amelyet Unix-szerű rendszereken használnak, szintén tartalmaz egy mezőt, amely jelzi az endianness-t, lehetővé téve a binárisok futtatását különböző architektúrákon, amennyiben a kód maga is architektúra-független vagy megfelelően fordított.
- Byte Order Mark (BOM): A Unicode szövegfájlok, különösen az UTF-16 és UTF-32 kódolásúak, gyakran tartalmaznak egy speciális karaktersorozatot a fájl elején, az úgynevezett Byte Order Markot (BOM). Ez a speciális bájt sorozat (pl. FE FF az UTF-16 Big-Endian, FF FE az UTF-16 Little-Endian esetén) jelzi a fájl olvasójának, hogy milyen bájt sorrendben kell értelmezni a fájl tartalmát. Az UTF-8 esetében a BOM opcionális és ritkábban használatos, mivel az UTF-8 alapvetően bájt-orientált kódolás, ahol a sorrendiség kevésbé kritikus.
Hálózati Kommunikáció
Talán az endianness legkritikusabb területe a hálózati kommunikáció. Ahhoz, hogy két különböző architektúrájú gép (pl. egy Intel alapú PC és egy PowerPC alapú szerver) sikeresen kommunikáljon egymással, az adatoknak konzisztens formátumban kell utazniuk a hálózaton. Ezt a problémát úgy oldották meg, hogy a hálózati bájt sorrendet (Network Byte Order) szabványosították.
A hálózati bájt sorrendet Big-Endianként határozták meg. Ez azt jelenti, hogy minden több bájtos adatot, amelyet hálózaton keresztül küldenek (pl. IP címek, portszámok, üzenet hossza), Big-Endian formátumban kell elküldeni. A fogadó félnek, függetlenül attól, hogy milyen belső endianness-szel rendelkezik, át kell konvertálnia a bejövő adatokat a saját belső sorrendjére, és fordítva, a kimenő adatokat a hálózati bájt sorrendre kell konvertálnia.
Ezt a konverziót a programozók általában speciális függvényekkel végzik el, mint például a C nyelvben elérhető htons() (host to network short), htonl() (host to network long), ntohs() (network to host short) és ntohl() (network to host long). Ezek a függvények gondoskodnak arról, hogy az adatok helyesen legyenek értelmezve mind a küldő, mind a fogadó oldalon, áthidalva az architektúrák közötti endianness különbségeket.
Programozási Nyelvek és Könyvtárak
A legtöbb magas szintű programozási nyelv (pl. Python, Java, C#, JavaScript) absztrahálja az endianness kérdését a programozók elől a beépített adattípusok és adatáramok kezelése során. Azonban alacsony szintű programozásnál, különösen C/C++ nyelven, az endianness komoly kihívást jelenthet.
-
C/C++: Itt a programozó közvetlenül hozzáférhet a memóriához, és mutatók, valamint
union-ok segítségével manipulálhatja az adatokat. Ez lehetővé teszi az endianness ellenőrzését és a manuális bájtcserét, de rendkívül körültekintő programozást igényel. Amemcpyésmemmovefüggvények nem végeznek bájtcsere konverziót, csak bájtokat másolnak, ahogy vannak. -
Java: A Java Virtual Machine (JVM) alapvetően Big-Endian, ami azt jelenti, hogy a Java programok általában nem kell, hogy foglalkozzanak az endianness-szel, mivel a JVM gondoskodik a konzisztens bájtsorrendről. Azonban ha Java Native Interface (JNI) segítségével natív C/C++ kóddal kommunikálunk, vagy bináris fájlokat olvasunk, akkor az endianness kérdése újra relevánssá válik. A Java
ByteBufferosztálya lehetővé teszi a bájt sorrendiség explicit beállítását (order(ByteOrder.BIG_ENDIAN)vagyorder(ByteOrder.LITTLE_ENDIAN)). -
Python: A Python
structmodulja lehetőséget biztosít a bináris adatok C struktúrákba való konvertálására és vissza, és explicit módon meghatározható a bájt sorrendiség (‘<' Little-Endian, '>‘ Big-Endian, ‘=’ natív endianness). Ez rendkívül hasznos a bináris fájlok feldolgozásához vagy hálózati protokollok implementálásához.
Adatbázisok
Az adatbázisok általában a saját belső formátumukban tárolják az adatokat, és a motor kezeli az endianness-t. Azonban, ha bináris adatokat tárolunk közvetlenül (például BLOB-okat), vagy ha az adatbázis fájljait egyik rendszerről a másikra mozgatjuk (különösen, ha a forrás és cél rendszer eltérő architektúrájú), akkor az endianness problémákhoz vezethet. A legtöbb modern adatbázis-rendszer transzparens módon kezeli ezt a migráció során, de a manuális bináris adatáthelyezésnél figyelembe kell venni.
Összességében az endianness a számítástechnika számos szintjén jelen van, a legalacsonyabb hardveres reprezentációtól egészen a hálózati protokollokig és a fájlformátumokig. A vele kapcsolatos problémák gyakran rejtettek, de súlyos következményekkel járhatnak, ha nem kezelik őket megfelelően.
Kihívások és Hibalehetőségek
Az endianness különbségek számos kihívást és hibalehetőséget rejtenek magukban, különösen a rendszerek közötti interoperabilitás és a hordozható szoftverek fejlesztése során. A leggyakoribb problémák közé tartozik az adatkorrupció, a nehezen debugolható hibák és a teljesítményromlás.
Adatkorrupció és Inkorrekt Értelmezés
Ez a legnyilvánvalóbb és leggyakoribb probléma. Ha egy Big-Endian rendszer által írt több bájtos adatot egy Little-Endian rendszer olvas be anélkül, hogy a bájt sorrendet korrigálná, az adat teljesen hibásan lesz értelmezve. Például, ha a hexadecimális 0x12345678 számot egy Big-Endian rendszer írja: [12][34][56][78]. Egy Little-Endian rendszer ezt 0x78563412-ként fogja olvasni, ami teljesen más érték.
Ez adatbázisokban, fájlokban, vagy hálózati üzenetekben tárolt numerikus értékek, memóriacímek, vagy akár karakterláncok (ha azok több bájtos kódolást használnak) esetében is előfordulhat. Az eredmény lehet hibás számítás, rossz memóriacímre való ugrás, vagy olvashatatlan szöveg, ami akár rendszerösszeomláshoz is vezethet.
Portabilitási Problémák
A szoftverek portabilitása, azaz a képesség, hogy különböző hardverarchitektúrákon és operációs rendszereken is futtathatók legyenek, alapvető cél a modern szoftverfejlesztésben. Az endianness különbségek azonban komolyan alááshatják ezt a célt. Egy olyan program, amely feltételezi a natív endianness-t, hibásan fog működni, ha egy másik endianness-ű platformra portolják anélkül, hogy a bájtsorrend konverziókról gondoskodnának.
Ez különösen igaz azokra az alkalmazásokra, amelyek alacsony szintű memória-hozzáférést használnak, bináris fájlokat olvasnak/írnak, vagy közvetlenül hálózati socketekkel kommunikálnak. A programozóknak tudatosan kell megírniuk a kódot úgy, hogy az architektúra-független legyen, vagy explicit bájtcsere rutinokat kell használniuk.
Debugging Nehézségek
Az endianness hibák gyakran rendkívül nehezen debugolhatók, mert a probléma gyökere nem feltétlenül az algoritmusban vagy a logikában van, hanem az adatok memóriabeli reprezentációjában. Amikor egy programozó memóriadumpot vizsgál, vagy egy debuggerben nézi a változók értékeit, a bájtok sorrendje zavaró lehet, ha nem érti az adott rendszer endianness-ét.
Például, egy Little-Endian rendszeren, ha egy int változó értéke 0x12345678, és a memóriadumpban 78 56 34 12-t látunk, az tapasztalatlan programozók számára félrevezető lehet. A probléma akkor válik igazán bonyolulttá, ha az adatok egy részét helyesen, egy részét pedig hibásan kezelik a bájtsorrend miatt, ami nehezen reprodukálható, szaggatott hibákhoz vezethet.
Teljesítmény Problémák
Bár a modern processzorok és fordítók gyakran optimalizálják a bájtcsere műveleteket, a nagyszámú adatáramlás során történő folyamatos konverzió (különösen hálózati kommunikációban vagy nagy bináris fájlok feldolgozásakor) teljesítménycsökkenést okozhat. Minden bájtcsere egy extra CPU ciklust igényel, ami nagy mennyiségű adat esetén jelentős terhelést jelenthet.
Ezért fontos, hogy a fejlesztők mérlegeljék, mikor van valóban szükség bájtcsere konverzióra, és mikor lehet elkerülni azt például a fájlformátumok vagy a protokollok gondos tervezésével. Egyes esetekben a Bi-Endian processzorok képességeinek kihasználása segíthet minimalizálni a konverziók számát.
Biztonsági Sebezhetőségek
Bár ritkán fordul elő közvetlenül, az endianness hibák közvetve biztonsági sebezhetőségekhez is vezethetnek. Például, ha egy hálózati protokoll rosszul értelmezi egy üzenet hosszát az endianness különbségek miatt, az buffer túlcsorduláshoz vagy más memóriakezelési hibákhoz vezethet, amelyeket rosszindulatú támadók kihasználhatnak.
Hasonlóképpen, ha egy fájlrendszer vagy egy alkalmazás hibásan értelmez egy bináris fájlban tárolt mutatót vagy offsetet, az jogosulatlan memóriaterületekhez való hozzáférést vagy kódvégrehajtást eredményezhet. Ezért a biztonságkritikus rendszerek fejlesztése során különös figyelmet kell fordítani az endianness helyes kezelésére.
Ezek a kihívások hangsúlyozzák az endianness mélyreható megértésének fontosságát, és rávilágítanak arra, hogy miért elengedhetetlen a megfelelő tervezés és implementáció a robusztus és megbízható szoftverrendszerek létrehozásához.
Endianness Detektálása és Konverziója
Mivel a különböző rendszerek eltérő endianness-t használhatnak, létfontosságú, hogy a programok képesek legyenek felismerni a natív bájt sorrendiséget, és szükség esetén konvertálni az adatokat. Számos módszer és eszköz létezik erre a célra.
Programozott Detektálás (C/C++ példával)
A C/C++ nyelvben viszonylag egyszerűen ellenőrizhető a rendszer endianness-e futásidőben, a union típus segítségével. A union lehetővé teszi, hogy ugyanazt a memóriaterületet különböző adattípusokként értelmezzük.
#include <stdio.h>
#include <stdint.h> // For uint32_t
int main() {
union {
uint32_t i;
char c[4];
} test_value;
test_value.i = 0x01020304; // Hexadecimális érték: 0x01 a legértékesebb bájt, 0x04 a legkevésbé értékes
if (test_value.c[0] == 0x04) {
printf("A rendszer Little-Endian.\n");
} else if (test_value.c[0] == 0x01) {
printf("A rendszer Big-Endian.\n");
} else {
printf("Ismeretlen endianness vagy hibás érték.\n");
}
printf("A bájtok sorrendje a memóriában: %02X %02X %02X %02X\n",
(unsigned char)test_value.c[0],
(unsigned char)test_value.c[1],
(unsigned char)test_value.c[2],
(unsigned char)test_value.c[3]);
return 0;
}
Magyarázat: A test_value.i = 0x01020304; utasítással egy 32 bites egész számot tárolunk.
- Ha a rendszer Little-Endian, a legkevésbé értékes bájt (
0x04) kerül a legalacsonyabb memóriacímre, azaztest_value.c[0]-ba. - Ha a rendszer Big-Endian, a legértékesebb bájt (
0x01) kerül a legalacsonyabb memóriacímre, azaztest_value.c[0]-ba.
Ezzel a módszerrel futásidőben megállapítható a rendszer bájtsorrendje, és ennek megfelelően lehet adatkonverziókat végezni.
Bájt Sorrend Konverziós Függvények
A leggyakoribb megközelítés az adatok endianness konverziójára a speciális függvények használata. Ezek a függvények a bájtok sorrendjét megfordítják egy több bájtos értékben.
Hálózati Bájt Sorrend Függvények (BSD Sockets API)
A hálózati programozásban standardizált függvények állnak rendelkezésre, amelyek konvertálnak a „host byte order” (a gép natív endianness-e) és a „network byte order” (Big-Endian) között. Ezek a függvények a <arpa/inet.h> (Unix/Linux) vagy <winsock2.h> (Windows) fejlécfájlokban találhatók:
htons(): host to network short (16 bites)htonl(): host to network long (32 bites)ntohs(): network to host short (16 bites)ntohl(): network to host long (32 bites)
Ezek a függvények intelligensek: ha a gép natív endianness-e már Big-Endian, akkor nem végeznek tényleges bájtcserét, hanem csak visszaadják az eredeti értéket, ami optimalizálja a teljesítményt.
#include <stdio.h>
#include <arpa/inet.h> // For htons, htonl, etc.
int main() {
uint16_t host_short = 0x1234;
uint32_t host_long = 0x12345678;
uint16_t net_short = htons(host_short);
uint32_t net_long = htonl(host_long);
printf("Host short: 0x%04X, Network short: 0x%04X\n", host_short, net_short);
printf("Host long: 0x%08X, Network long: 0x%08X\n", host_long, net_long);
// Képzeletbeli bejövő hálózati adatok konvertálása vissza
uint16_t received_net_short = 0x1234; // Tegyük fel, hogy ez jött a hálózatról
uint32_t received_net_long = 0x12345678; // Tegyük fel, hogy ez jött a hálózatról
uint16_t converted_host_short = ntohs(received_net_short);
uint32_t converted_host_long = ntohl(received_net_long);
printf("Received net short: 0x%04X, Converted host short: 0x%04X\n", received_net_short, converted_host_short);
printf("Received net long: 0x%08X, Converted host long: 0x%08X\n", received_net_long, converted_host_long);
return 0;
}
Manuális Bájtcsere (Bitwise Műveletekkel)
Ha nincs elérhető standard függvény, vagy specifikus igények merülnek fel, a bájtok manuálisan is cserélhetők bitwise műveletekkel. Ez különösen hasznos lehet beágyazott rendszerekben vagy olyan környezetekben, ahol a standard könyvtárak korlátozottak.
#include <stdio.h>
#include <stdint.h>
// 16 bites érték bájtcseréje
uint16_t swap_endian_16(uint16_t val) {
return (val << 8) | (val >> 8);
}
// 32 bites érték bájtcseréje
uint32_t swap_endian_32(uint32_t val) {
return ((val << 24) & (0xFF000000)) |
((val << 8) & (0x00FF0000)) |
((val >> 8) & (0x0000FF00)) |
((val >> 24) & (0x000000FF));
}
// 64 bites érték bájtcseréje (modern GCC/Clang támogatja a __builtin_bswap64-et)
uint64_t swap_endian_64(uint64_t val) {
return ((val << 56) & (0xFF00000000000000ULL)) |
((val << 40) & (0x00FF000000000000ULL)) |
((val << 24) & (0x0000FF0000000000ULL)) |
((val << 8) & (0x000000FF00000000ULL)) |
((val >> 8) & (0x00000000FF000000ULL)) |
((val >> 24) & (0x0000000000FF0000ULL)) |
((val >> 40) & (0x000000000000FF00ULL)) |
((val >> 56) & (0x00000000000000FFULL));
}
int main() {
uint16_t val16 = 0x1234;
uint32_t val32 = 0x12345678;
uint64_t val64 = 0x0102030405060708ULL;
printf("Original 16-bit: 0x%04X, Swapped: 0x%04X\n", val16, swap_endian_16(val16));
printf("Original 32-bit: 0x%08X, Swapped: 0x%08X\n", val32, swap_endian_32(val32));
printf("Original 64-bit: 0x%016llX, Swapped: 0x%016llX\n", val64, swap_endian_64(val64));
return 0;
}
Modern fordítók, mint a GCC és a Clang, beépített funkciókat (__builtin_bswap16, __builtin_bswap32, __builtin_bswap64) is biztosítanak a bájtcserére, amelyek gyakran hardveres utasításokra fordulnak le, így rendkívül hatékonyak.
Fájlformátumok és Protokollok Tervezése
A legjobb megközelítés gyakran az, ha a fájlformátumokat és hálózati protokollokat eleve úgy tervezik meg, hogy az endianness probléma minimalizálódjon. Ez megtehető a következő módokon:
- Explicit bájt sorrend megadása: A formátum specifikációjában rögzíteni kell, hogy az adatok Big-Endian vagy Little-Endian sorrendben vannak-e tárolva. A TIFF fájlok például ezt teszik a fejlécben.
- „Marker” bájtok vagy BOM használata: Speciális bájt sorozatok beillesztése a fájl elejére, amelyek jelzik a bájt sorrendet (pl. UTF-16 BOM).
- Standard hálózati bájt sorrend használata: Minden hálózati kommunikációban a Big-Endian (hálózati bájt sorrend) használata.
- Adat absztrakció: Magasabb szintű formátumok (pl. XML, JSON, Protobuf) használata, amelyek szövegesen vagy platformfüggetlen bináris formában ábrázolják az adatokat, így az endianness problémák a mögöttes könyvtárakra hárulnak, és a fejlesztőnek nem kell közvetlenül foglalkoznia velük.
Eszközök és Könyvtárak
Számos programozási nyelv és keretrendszer kínál beépített vagy külső könyvtárakat az endianness kezelésére. A Python struct modulja, a Java ByteBuffer osztálya, vagy a Boost Endian könyvtár C++-ban mind olyan eszközök, amelyek megkönnyítik a fejlesztők dolgát a bájtsorrend konverziók terén.
Az endianness detektálása és konverziója elengedhetetlen a modern, heterogén számítástechnikai környezetben. A megfelelő stratégiák és eszközök alkalmazása biztosítja az adatok integritását és a rendszerek közötti zökkenőmentes kommunikációt.
Best Practices és Jövőbeli Trendek
Az endianness kezelése a szoftverfejlesztésben a megbízhatóság és a hordozhatóság kulcsfontosságú aspektusa. Ahhoz, hogy elkerüljük az ebből adódó problémákat, bizonyos legjobb gyakorlatokat érdemes követni, és érdemes figyelemmel kísérni a jövőbeli trendeket is.
Bevált Gyakorlatok (Best Practices)
- Mindig definiáljunk egy standard bájt sorrendet az adatcseréhez: Legyen szó fájlformátumról vagy hálózati protokollról, a specifikációnak egyértelműen rögzítenie kell a használt bájt sorrendet. A hálózati kommunikációban ez a Big-Endian (hálózati bájt sorrend). Fájlok esetében választhatunk Big-Endian-t (gyakran a „network byte order” miatt) vagy Little-Endian-t, de a lényeg a konzisztencia és a dokumentáció.
- Használjunk platformfüggetlen adatátviteli formátumokat: Amennyiben lehetséges, kerüljük a nyers bináris adatok közvetlen átvitelét, ha az endianness problémát okozhat. Helyette használjunk önleíró, szöveges formátumokat, mint a JSON, XML, vagy platformfüggetlen bináris szerializációs protokollokat, mint a Protocol Buffers vagy Apache Avro. Ezek a formátumok absztrahálják az endianness kérdését, mivel a beépített könyvtárak gondoskodnak a helyes értelmezésről.
-
Alkalmazzunk explicit konverziós rutinokat: Amikor elkerülhetetlen a bináris adatok közvetlen kezelése (pl. hálózati programozás, alacsony szintű illesztőprogramok, beágyazott rendszerek), mindig használjunk explicit konverziós függvényeket (pl.
htons,ntohlvagy manuális bájtcsere rutinok). Ezeket a konverziókat a lehető legközelebb kell elhelyezni az I/O műveletekhez. - Absztraháljuk az endianness-t az alkalmazás logikájában: A magas szintű alkalmazáslogikának nem szabadna tudnia vagy törődnie az endianness-szel. Az adatoknak már a natív formátumban kell lenniük, amikor az alkalmazás kódja feldolgozza őket. A konverziókat egy alacsonyabb szintű rétegnek kell kezelnie (pl. egy adatátviteli rétegnek vagy egy fájlkezelő modulnak).
-
Használjunk szabványos könyvtárakat és keretrendszereket: A legtöbb modern programozási nyelv vagy keretrendszer beépített mechanizmusokat vagy könyvtárakat kínál az endianness kezelésére (pl. Java
ByteBuffer, Pythonstruct, C++ Boost.Endian). Ezek használata nemcsak megbízhatóbb, de hatékonyabb is, mivel gyakran optimalizált, hardveresen gyorsított műveleteket használnak. - Alapos tesztelés különböző architektúrákon: A portolhatóság biztosításához elengedhetetlen a szoftver tesztelése különböző endianness-ű rendszereken. Ez magában foglalhatja virtuális gépek, emulátorok használatát, vagy fizikai hozzáférést a célhardverekhez.
- Dokumentáció: A projekt dokumentációjában egyértelműen rögzíteni kell minden olyan területet, ahol az endianness releváns, és hogyan kezeli azt a szoftver.
Jövőbeli Trendek és Az Endianness Szerepe
Bár az endianness egy alapvető hardverkoncepció, a szoftverfejlesztés változó tájképe befolyásolja a vele való interakciónkat.
- Növekvő absztrakciós szintek: A modern szoftverfejlesztés egyre inkább magasabb absztrakciós szintekre helyezi a hangsúlyt. A felhőalapú számítástechnika, a konténerizáció (Docker, Kubernetes) és a mikroszolgáltatások mind hozzájárulnak ahhoz, hogy a fejlesztőknek egyre kevésbé kelljen közvetlenül foglalkozniuk a mögöttes hardveres részletekkel, így az endianness kérdése is háttérbe szorul. A virtuális gépek és konténerek egységes környezetet biztosítanak, amely elrejti a fizikai hardver endianness-ét.
- Szoftveres vezérlésű hálózatok (SDN) és adatközpontok: Bár az alapvető hálózati protokollok továbbra is Big-Endianek maradnak, az SDN-ek és a szoftveresen definiált adatközpontok lehetővé tehetik az intelligensebb adatkezelést a hálózati rétegben, potenciálisan automatizálva az endianness konverziókat, vagy optimalizálva az adatfolyamokat a heterogén környezetekben.
- Heterogén számítástechnika: A speciális hardverek, mint a GPU-k, FPGA-k és AI gyorsítók térnyerése új kihívásokat hozhat. Bár ezek az eszközök gyakran a CPU-val azonos endianness-t követik, vagy saját belső adatkezelési logikájuk van, az adatok CPU és gyorsító közötti mozgatásakor továbbra is figyelni kell a bájtsorrendre.
- RISC-V és nyílt architektúrák: A RISC-V egy nyílt forráskódú utasításkészlet-architektúra (ISA), amely rugalmasan kezeli az endianness-t, lehetővé téve a tervezők számára, hogy Big-Endian vagy Little-Endian módot válasszanak. Ez a rugalmasság tovább erősítheti a heterogén környezetek létét, és hangsúlyozza a szoftveres megoldások fontosságát a kompatibilitás biztosításában.
- Standardizálás és protokollok evolúciója: A jövőben várhatóan tovább folytatódik a protokollok és fájlformátumok standardizálása, amelyek beépítik az endianness kezelését, vagy olyan formátumokat részesítenek előnyben, amelyek eleve függetlenek ettől a problémától.
Az endianness, bár technikailag részletes és alacsony szintű téma, továbbra is releváns marad a számítástechnika alapjaiban. A modern fejlesztési megközelítések és a növekvő absztrakció ellenére a fejlesztőknek és rendszeradminisztrátoroknak tisztában kell lenniük a létezésével és a lehetséges következményeivel. A legjobb gyakorlatok követése és a megfelelő eszközök használata biztosítja, hogy a bájt sorrendiséggel kapcsolatos problémák ne akadályozzák a megbízható és interoperábilis rendszerek létrehozását.