


A határolójelek kulcsfontosságú szerepet töltenek be az adatfeldolgozásban. Ezek a speciális karakterek vagy karaktersorozatok szolgálnak az adatok elkülönítésére, ezáltal lehetővé téve a strukturált adatok hatékony tárolását és feldolgozását. Képzeljünk el egy táblázatot, ahol minden oszlopot egy határolójel választ el egymástól. Enélkül a jelölés nélkül az adatok egyetlen, értelmezhetetlen szöveggé olvadnának össze.
A határolójelek használata különösen fontos a szöveges fájlokban, mint például a CSV (Comma Separated Values) fájlokban, ahol a vessző (,) a leggyakoribb határolójel. De a határolójel lehet más karakter is, például pontosvessző (;), tabulátor (\t) vagy akár egyedi karaktersorozat is. A lényeg, hogy egyértelműen és következetesen jelölje az adatok határait.
A határolójelek lehetővé teszik, hogy az adatok könnyen importálhatók és exportálhatók legyenek különböző rendszerek között.
A különböző adatbázis-kezelő rendszerek (DBMS) és programozási nyelvek mind rendelkeznek beépített mechanizmusokkal a határolójelekkel tagolt adatok kezelésére. Ezek a mechanizmusok lehetővé teszik az adatok könnyű beolvasását, feldolgozását és tárolását.
A helytelenül megválasztott vagy nem megfelelően kezelt határolójelek komoly problémákat okozhatnak az adatfeldolgozás során. Például, ha egy adatmezőben is szerepel a használt határolójel, akkor az adatot a rendszer tévesen több részre bonthatja, ami adatvesztéshez vagy hibás eredményekhez vezethet. Éppen ezért a határolójelek megválasztásánál figyelembe kell venni az adatok jellegét és a potenciális ütközéseket.
Az adatfeldolgozás során gyakran találkozhatunk olyan helyzetekkel, amikor az adatok hierarchikus struktúrában vannak jelen. Ilyenkor a határolójelek mellett más módszerekre is szükség lehet az adatok megfelelő strukturálására és feldolgozására. Például a JSON (JavaScript Object Notation) formátum, bár nem használ hagyományos határolójeleket, hasonló elven működik, kulcs-érték párokat és tömböket használva az adatok strukturálására.
Összefoglalva, a határolójelek nélkülözhetetlenek az adatfeldolgozásban, mivel lehetővé teszik az adatok strukturált tárolását és hatékony feldolgozását. A megfelelő határolójel megválasztása és helyes kezelése elengedhetetlen a megbízható és pontos adatok eléréséhez.
A határolójel definíciója és alapvető funkciói
A határolójel (delimiter) egy speciális karakter vagy karakterlánc, melynek elsődleges célja az adatok elkülönítése az adatfeldolgozás során. Segítségével az adatok strukturált formában tárolhatók és kezelhetők, ami elengedhetetlen a hatékony adatbázis-kezeléshez, fájlfeldolgozáshoz és kommunikációs protokollokhoz.
A határolójelek használata lehetővé teszi, hogy egyetlen adatfolyamban több különálló adatértéket helyezzünk el. Ezek az értékek lehetnek például nevek, címek, számok vagy bármilyen más típusú adat. A határolójel egyértelműen jelzi, hol ér véget az egyik adatérték és hol kezdődik a következő.
A határolójel alapvető funkciója az, hogy egyértelműen elválassza egymástól az adatokat, lehetővé téve azok pontos értelmezését és feldolgozását.
Gyakori példák határolójelekre: a vessző (,) a CSV fájlokban, a tabulátor (\t) szöveges adatok rendezésénél, a kettőspont (:) konfigurációs fájlokban, vagy akár egyedi karakterláncok is. A választott határolójelnek egyedinek kell lennie, azaz nem fordulhat elő magukban az adatokban, különben hibás értelmezéshez vezethet.
A határolójelek használata kritikus fontosságú az adatok parsálásához és szétválasztásához. A megfelelő határolójel kiválasztása és következetes alkalmazása biztosítja az adatok integritását és a feldolgozó rendszerek megbízható működését.
A határolójelek története és fejlődése az informatikában
A határolójelek, vagy delimiterek, az adatfeldolgozásban kulcsfontosságú szerepet töltenek be az adatok strukturálásában és elkülönítésében. Történetük szorosan összefonódik az adathordozók és adatformátumok fejlődésével.
A legkorábbi példák között említhetjük a lyukkártyákat, ahol a lyukak elhelyezkedése és a kártya szélei szolgáltak határolójelként, meghatározva az egyes adatok helyét. Később, a mágnesszalagok korában, speciális rekordjelző karakterek funkcionáltak delimiterekként, jelezve a rekordok kezdetét és végét.
A szöveges adatok elterjedésével a vessző (CSV formátum), a tabulátor és a pontosvessző váltak a leggyakrabban használt határolójelekké. Ezek egyszerű, de hatékony eszközök voltak az adatok táblázatos formában történő tárolására és cseréjére.
A webes technológiák megjelenésével a határolójelek szerepe tovább bővült. A HTML és XML formátumok tag-ekkel határolják el az adatelemeket, lehetővé téve komplex, hierarchikus adatszerkezetek létrehozását.
A JSON (JavaScript Object Notation) formátum, amely mára az egyik legelterjedtebb adatformátum a webes alkalmazásokban, a kapcsos zárójeleket ({}) és a szögletes zárójeleket ([]) használja az objektumok és tömbök határolására. Ez a formátum különösen népszerűvé vált a könnyű olvashatósága és a legtöbb programozási nyelv általi egyszerű feldolgozhatósága miatt.
Az adatbázisok területén a SQL nyelv is használ határolójeleket, például az idézőjeleket a szöveges értékek, vagy a pontosvesszőt az utasítások elválasztására.
Napjainkban, a big data és a NoSQL adatbázisok korában, a határolójelek szerepe továbbra is kritikus. Bár sok rendszer kevesebb hangsúlyt fektet a szigorú formázásra, a megfelelő adatelkülönítés továbbra is elengedhetetlen a hatékony adatfeldolgozáshoz.
Gyakori határolójelek típusai és jellemzőik: vessző, pontosvessző, tabulátor, szóköz, újsor
A határolójelek (delimiterek) kulcsfontosságú szerepet töltenek be az adatfeldolgozásban. Segítségükkel tudjuk elkülöníteni az adatokat egymástól, így a számítógépek képesek értelmezni a különböző mezőket és értékeket. Nézzük meg a leggyakoribb határolójelek típusait és azok jellemzőit.
A vessző (,) talán a legismertebb határolójel. Gyakran használják CSV (Comma Separated Values) fájlokban, ahol minden sor egy adatrekordot, a vesszők pedig a mezőket választják el egymástól. Egyszerűsége miatt széles körben elterjedt, de problémát okozhat, ha a mezők maguk is tartalmaznak vesszőt. Ebben az esetben a mezőket idézőjelekkel kell körbevenni.
A pontosvessző (;) a vessző alternatívája, különösen azokban a nyelvekben és kultúrákban, ahol a vesszőt tizedespontként használják. Hasonlóan a vesszőhöz, egyszerűen implementálható, de a mezőkben előforduló pontosvesszők ugyanazt a problémát vetik fel, mint a vessző esetében.
A tabulátor (\t) egy speciális karakter, amely vízszintes térközt hoz létre. Gyakran használják szövegszerkesztőkben és táblázatkezelő programokban az adatok oszlopokba rendezésére. A tabulátor előnye, hogy ritkábban fordul elő magukban az adatokban, mint a vessző vagy a pontosvessző, így kisebb a valószínűsége annak, hogy összekeveredik a tényleges adatokkal.
A tabulátor használata egyszerűbb adatok esetén hatékony, de komplex adatszerkezeteknél kevésbé rugalmas.
A szóköz ( ) egy egyszerű, de néha félrevezető határolójel. Bár könnyen használható, nem mindig egyértelmű, hogy hány szóköz választja el a mezőket egymástól. Ez problémákat okozhat az adatok helyes értelmezésében, különösen akkor, ha a mezők maguk is tartalmaznak szóközöket. Ezért ritkábban használják önálló határolójelként, inkább más jelekkel kombinálva alkalmazzák.
Az újsor (\n vagy \r\n) a sorok végét jelzi, és gyakran használják szöveges fájlokban az egyes rekordok elkülönítésére. Minden sor egy új adatot vagy egy adatcsoportot képvisel. Az újsor karakter használata elengedhetetlen, amikor több sornyi adatot szeretnénk tárolni és feldolgozni. Fontos, hogy a különböző operációs rendszerek (Windows, Linux, macOS) eltérő újsor karaktereket használhatnak.
Az egyes határolójelek kiválasztása az adatstruktúra komplexitásától, a használt szoftverektől és a feldolgozási követelményektől függ.
Egyedi határolójelek és használatuk speciális esetekben
A határolójelek alapvető szerepet töltenek be az adatfeldolgozásban, lehetővé téve az adatok strukturált elválasztását. Bizonyos esetekben, amikor a hagyományos határolójelek (például vessző, pontosvessző, tabulátor) maguk is előfordulnak az adatokban, egyedi határolójelekre van szükség.
Ilyenkor gyakran olyan karakterláncokat választunk, amelyek nagyon valószínű, hogy nem szerepelnek magukban az adatokban. Például, ha egy szövegfájlban vesszővel elválasztott értékek vannak, de egyes értékek maguk is tartalmaznak vesszőt, akkor egy kevésbé gyakori karaktert, például a ‘|’ (függőleges vonal) karaktert használhatjuk határolójelként.
A reguláris kifejezések használata is elterjedt az egyedi határolójelek definiálására. Ezzel bonyolultabb mintákat is meghatározhatunk, amelyek elválasztják az adatokat. Például, egy reguláris kifejezés definiálhatja, hogy az adatok két sor közötti szakaszokként vannak elválasztva.
Az egyedi határolójelek alkalmazása elengedhetetlen a pontos és hibamentes adatfeldolgozáshoz, amikor a standard határolójelek ütköznek az adatok tartalmával.
Néhány speciális esetben, mint például a hierarchikus adatok (pl. JSON, XML) feldolgozásakor, a határolójelek rendszere sokkal komplexebb lehet. Itt a nyitó és záró címkék (pl. <tag> és </tag> az XML-ben) vagy a kapcsos zárójelek és szögletes zárójelek (JSON-ben) határozzák meg az adatok szerkezetét és elválasztását.
A helytelenül megválasztott vagy hibásan kezelt határolójelek adatvesztéshez, adatsérüléshez vagy helytelen értelmezéshez vezethetnek. Ezért a határolójel kiválasztása és a feldolgozási logika helyessége kritikus fontosságú.
A CSV (Comma Separated Values) formátum részletes bemutatása
A CSV (Comma Separated Values), vagyis vesszővel elválasztott értékek formátum egy széles körben használt szöveges adatformátum, melynek alapvető célja táblázatos adatok egyszerű és univerzális tárolása. A CSV lényegében egy egyszerű szövegfájl, ahol az adatok sorokba rendeződnek, és az egyes sorokon belüli értékeket egy meghatározott határolójel (delimiter) választja el egymástól. Leggyakrabban a vessző (,) szolgál határolójelként, de más karakterek, például a pontosvessző (;), tabulátor (\t) vagy akár a függőleges vonal (|) is használhatóak.
A CSV formátum népszerűségét az egyszerűségének és a széles körű kompatibilitásának köszönheti. Számos program képes CSV fájlok olvasására és írására, beleértve a táblázatkezelőket (pl. Excel, Google Sheets), adatbázis-kezelő rendszereket, programozási nyelveket (pl. Python, R) és más adatelemző eszközöket. Ezáltal a CSV ideális megoldást jelent az adatok különböző rendszerek közötti cseréjére és tárolására.
A CSV fájlok szerkezete viszonylag egyszerű. Minden sor egy adatrekordot reprezentál, és a soron belüli értékek az adott rekord egyes mezőit képviselik. A fejléc sor, amely az oszlopok neveit tartalmazza, általában az első sorban található. Ha a fejléc sor nincs jelen, a programoknak feltételezniük kell az oszlopok jelentését vagy manuálisan meg kell adniuk azokat.
A határolójel megválasztása kritikus fontosságú. Ha az adatok maguk is tartalmazzák a vesszőt (vagy az alapértelmezett határolójelet), akkor az adatokat idézőjelek közé kell zárni, hogy a programok helyesen tudják értelmezni a fájlt. Például: „Budapest, Magyarország”,12345. Az idézőjelek használata segít a programoknak megkülönböztetni az adatban szereplő vesszőket a határolójelként funkcionáló vesszőktől.
A CSV formátum legnagyobb előnye a platformfüggetlenség és az egyszerűség, ami lehetővé teszi az adatok széles körben történő felhasználását.
A CSV formátum nem definiál adattípusokat. Minden adatot szövegként tárol, ezért az olvasó programnak kell értelmeznie az egyes mezők adattípusát (pl. szám, dátum, szöveg). Ez néha problémákat okozhat, ha az adattípusok nem egyértelműek.
A CSV fájlok kezelése során figyelembe kell venni a karakterkódolást is. A helyes karakterkódolás (pl. UTF-8) biztosítja, hogy a speciális karakterek (pl. ékezetes betűk) helyesen jelenjenek meg. A helytelen karakterkódolás hibás adatokhoz vezethet.
Néhány gyakori probléma a CSV fájlokkal kapcsolatban:
- Hiányzó adatok: Az üres mezők értelmezése eltérő lehet a különböző programokban.
- Változó számú oszlop: Ha a sorokban nem azonos számú mező található, az problémákat okozhat az adatfeldolgozás során.
- Inkonzisztens adatformátumok: Ha az adatformátumok (pl. dátumok) nem egységesek, az nehezítheti az adatok elemzését.
Bár a CSV egyszerű formátum, a megfelelő tervezés és a gondos adatkezelés elengedhetetlen a sikeres adatfeldolgozáshoz. A megfelelő határolójel kiválasztása, az adatok idézőjelekkel történő védelme, a karakterkódolás helyes beállítása és az adatok konzisztenciájának biztosítása mind hozzájárulnak a CSV fájlok megbízható és hatékony használatához.
A TSV (Tab Separated Values) formátum és alkalmazási területei
A TSV (Tab Separated Values), azaz tabulátorral elválasztott értékek formátum egy egyszerű szöveges adatformátum, ahol az adatmezőket tabulátor karakter választja el egymástól. Mivel a tabulátor egy nem látható karakter, ez a formátum különösen hasznos lehet olyan esetekben, amikor a vessző vagy más gyakori elválasztójel előfordulhat magukban az adatokban is, ami problémákat okozhat a CSV (Comma Separated Values) formátumban.
A TSV formátum előnyei közé tartozik a könnyű olvashatóság és szerkeszthetőség egyszerű szövegszerkesztőkkel. Az adatok strukturált módon vannak tárolva, ami megkönnyíti a programok számára az adatok feldolgozását és elemzését. Gyakran használják adatbázisokból történő exportálásra és importálásra, valamint statisztikai szoftverek közötti adatcserére.
A TSV formátum különösen alkalmas nagy mennyiségű adat tárolására, mivel a tabulátor karakter hatékonyan elválasztja az adatmezőket, minimalizálva az értelmezési hibák kockázatát.
A TSV fájlok tipikusan .tsv kiterjesztéssel rendelkeznek, bár előfordulhat a .txt kiterjesztés használata is. Számos program támogatja a TSV formátumot, beleértve a táblázatkezelőket (pl. Excel, Google Sheets), adatbázis-kezelő rendszereket (pl. MySQL, PostgreSQL) és statisztikai szoftvereket (pl. R, SPSS).
Alkalmazási területei rendkívül széleskörűek. Például:
- Bioinformatikai adatok tárolása: Genomikai és proteomikai adatok, ahol a gének és fehérjék azonosítói, valamint a hozzájuk tartozó információk tabulátorokkal vannak elválasztva.
- Logfájlok elemzése: Szerver logfájlok, ahol az események időbélyegei, IP-címek és egyéb releváns adatok TSV formátumban vannak tárolva.
- Kereskedelmi adatok: Termékadatbázisok, ahol a termékek nevei, árai, leírásai és egyéb jellemzői tabulátorokkal vannak elválasztva.
- Nyelvi adatok: Szótárak, korpuszok és más nyelvi erőforrások, ahol a szavak, jelentéseik és egyéb információk TSV formátumban vannak tárolva.
Fontos, hogy a TSV fájlok feldolgozásakor figyeljünk a kódolásra (pl. UTF-8), hogy a speciális karakterek helyesen jelenjenek meg. Továbbá, a sorvégek (pl. \n, \r\n) kezelése is lényeges, hogy a fájl helyesen legyen értelmezve a különböző operációs rendszereken.
Határolójelek használata adatbázisokban: SQL és más adatbázis-kezelő rendszerek

Az adatbázisokban a határolójelek kulcsszerepet töltenek be az adatok strukturálásában és értelmezésében. Ezek a speciális karakterek vagy karaktersorozatok jelzik az adatelemek kezdetét és végét, illetve elválasztják azokat egymástól. Az SQL és más adatbázis-kezelő rendszerek (DBMS) széles körben használják őket a lekérdezések, az adatimportálás és -exportálás, valamint a tárolt eljárások során.
Az SQL-ben a leggyakoribb határolójelek a következők:
- A vessző (,), amely az
INSERTutasításban az értékeket választja el, illetve aSELECTutasításban a kiválasztott oszlopokat. Például:INSERT INTO tabla (oszlop1, oszlop2) VALUES ('érték1', 'érték2'); - Az idézőjelek (egyediek (‘) vagy dupla („)), amelyek a karakterláncokat határolják. A pontos használat a DBMS-től függ. Például:
SELECT * FROM tabla WHERE nev = 'Kovács János'; - A pontosvessző (;), amely az SQL utasításokat választja el egymástól. Ez különösen fontos a tárolt eljárásokban és szkriptekben.
Más adatbázis-kezelő rendszerek is használnak határolójeleket, de a konkrét karakterek és szabályok eltérhetnek. Például a CSV (Comma Separated Values) fájlokban, amelyeket gyakran használnak adatok importálására és exportálására, a vessző a mezőket választja el, és az idézőjelek a karakterláncokat határolják, amelyek vesszőt tartalmaznak.
A határolójelek helyes használata elengedhetetlen az adatbázisok integritásának és konzisztenciájának megőrzéséhez. A helytelenül használt határolójelek adatvesztést, hibás lekérdezési eredményeket vagy akár a teljes adatbázis sérülését is okozhatják.
A határolójelek nem csupán elválasztó karakterek; kulcsfontosságú szerepet töltenek be az adatbázisok nyelvének értelmezésében és az adatok helyes feldolgozásában.
Az adatbázis-kezelő rendszerek gyakran kínálnak eszközöket a határolójelek konfigurálására és testreszabására, különösen az adatimportálás és -exportálás során. Ez lehetővé teszi a felhasználók számára, hogy alkalmazkodjanak a különböző adatforrásokhoz és formátumokhoz.
Például, ha egy CSV fájlban a mezők elválasztására nem vesszőt, hanem pontosvesszőt használnak, akkor az importáló eszközben be kell állítani a megfelelő határolójelet. Hasonlóképpen, a karakterláncok határolására is lehetőség van más karaktereket (pl. aposztrófokat) használni, ha a default beállítás nem megfelelő.
A reguláris kifejezések is használhatók összetettebb határolási minták kezelésére, különösen az adatvalidálás és -tisztítás során. Ezek lehetővé teszik a felhasználók számára, hogy bonyolultabb szabályokat definiáljanak az adatok elválasztására és értelmezésére.
Határolójelek szerepe a szöveges fájlok feldolgozásában
A határolójelek kulcsfontosságúak a szöveges adatok feldolgozásában. Ezek a speciális karakterek vagy karaktersorozatok szolgálnak arra, hogy elkülönítsék az adatmezőket egymástól egy szöveges fájlban. A határolójelek teszik lehetővé a gépek számára, hogy értelmezzék a strukturálatlan szöveget és azonosítsák az egyes adatpontokat.
Gyakori határolójelek közé tartozik a vessző (,), a pontosvessző (;), a tabulátor (\t) és a szóköz. A választott határolójelnek egyedinek kell lennie az adatokon belül, hogy ne okozzon félreértést a feldolgozás során. Például, egy CSV (Comma Separated Values) fájlban a vessző határolja el az oszlopokat, míg az új sor karakter a sorokat.
A határolójelek használata elengedhetetlen az adatok importálásához és exportálásához különböző alkalmazások között. Ha egy adatbázisból exportálunk adatokat, a határolójelek segítségével formázhatjuk azokat egy szöveges fájlba, amelyet egy másik alkalmazás képes beolvasni. Fordítva is igaz, egy szöveges fájlból beolvasott adatok határolójelek alapján kerülnek felosztásra és tárolásra egy adatbázisban.
A helytelenül megválasztott vagy rosszul kezelt határolójel hibás adatfeldolgozáshoz vezethet, ami komoly problémákat okozhat az adatok elemzésében és felhasználásában.
Bizonyos esetekben, ha az adatmezők maguk is tartalmazzák a határolójelet, escape szekvenciákat vagy idézőjeleket használnak a helyes értelmezés érdekében. Például, ha egy CSV fájlban egy mező vesszőt tartalmaz, akkor azt idézőjelek közé kell tenni, hogy a program ne tekintse oszlopelválasztónak.
A reguláris kifejezések használata is elterjedt a komplexebb határolójelek kezelésére, amelyek nem egyszerű karakterek, hanem minták alapján azonosítják az adatmezőket.
Határolójelek a programozási nyelvekben: stringek felosztása és kezelése
A határolójelek (delimiter) kulcsfontosságú szerepet játszanak a programozási nyelvekben, különösen a stringek felosztásában és kezelésében. Lényegében olyan karakterek vagy karaktersorozatok, amelyek adatokat, adatelemeket vagy stringeket választanak el egymástól.
A stringek felosztása (splitting) egy gyakori művelet, amely során egy hosszabb stringet kisebb részekre bontunk. Ez a folyamat a határolójelek segítségével történik. Például, egy vesszővel elválasztott értékeket tartalmazó string (CSV fájlban) a vessző (,) határolójel segítségével különálló értékekre bontható.
Számos programozási nyelv kínál beépített függvényeket vagy metódusokat a stringek felosztására. Ezek a függvények általában egy stringet és egy határolójelet várnak bemenetként, és visszaadnak egy tömböt vagy listát, amely a felosztott stringeket tartalmazza.
Példák a határolójelek használatára:
- CSV fájlok: A vessző (,) a leggyakoribb határolójel, de más karakterek is használhatók, például a pontosvessző (;).
- URL-ek: A perjel (/) és a kérdőjel (?) határolójelként szolgálnak az URL különböző részeinek elkülönítésére.
- Dátumok: A pont (.), a kötőjel (-) vagy a perjel (/) használható a nap, hónap és év elválasztására.
- Időpontok: A kettőspont (:) elválasztja az órákat, perceket és másodperceket.
A határolójelek helyes használata elengedhetetlen az adatok pontos és hatékony feldolgozásához.
A határolójel kiválasztásakor figyelembe kell venni, hogy az ne szerepeljen magukban az adatokban. Ha a határolójel is része lehet az adatoknak, akkor speciális technikákat kell alkalmazni, például a határolójelet escape-elni (védetté tenni), vagy más, kevésbé valószínű karaktert választani határolójelnek.
A stringek felosztásakor fontos figyelni a üres stringekre is. Ha a határolójelek egymás mellett helyezkednek el, vagy a string elején vagy végén találhatók, akkor üres stringek keletkezhetnek a felosztott tömbben. A programozási nyelvek függvényei általában kínálnak lehetőséget az üres stringek eltávolítására.
A határolójelek nem csak stringek felosztására használhatók, hanem más adatszerkezetekben is, például listákban vagy tömbökben. Ebben az esetben a határolójel egy index lehet, amely az adatelemek elhelyezkedését jelöli.
Egyes programozási nyelvek reguláris kifejezéseket is támogatnak határolójelként. Ez lehetővé teszi összetettebb minták alapján történő felosztást.
A split() függvény, mely szinte minden programozási nyelvben megtalálható, a határolójelek mentén szeparálja a stringet, létrehozva egy string tömböt. Például a Pythonban: "alma,körte,banán".split(",") eredménye ['alma', 'körte', 'banán'] lesz.
Reguláris kifejezések (regex) és a határolójelek kapcsolata
A reguláris kifejezések (regex) és a határolójelek szorosan összefonódnak az adatfeldolgozás során. A regexek mintaminták, melyek szövegekben keresnek bizonyos karakterláncokat, míg a határolójelek az adatok strukturálására és elválasztására szolgálnak.
A határolójelek, mint például a vessző (,), pontosvessző (;), vagy tabulátor (\t), gyakran használatosak CSV (Comma Separated Values) fájlokban, ahol az egyes mezőket választják el egymástól. A regexek itt jönnek a képbe, amikor a határolójelekkel határolt adatokból szeretnénk bizonyos mintákat kivonni, vagy éppen validálni a formátumot.
Például, képzeljünk el egy CSV fájlt, melyben a telefonszámok formátuma nem egységes. A regex segítségével megkereshetjük az összes érvénytelen formátumú telefonszámot, vagy éppen átalakíthatjuk őket egy egységes formátumba. A határolójel (vessző) itt a telefonszámokat választja el a többi adattól, a regex pedig magával a telefonszámok tartalmával dolgozik.
A regexek lehetővé teszik a határolójelek dinamikus kezelését és a komplex minták keresését a határolt adatokban.
A regexek használata során gyakran szükség van a határolójelek „escape”-elésére, azaz speciális karakterekké alakítására, hogy a regex motor megfelelően értelmezze őket. Például, ha a pont (.) karaktert akarjuk keresni (mely a regexben bármilyen karaktert jelöl), akkor azt \. formában kell megadnunk.
A regexek és a határolójelek együttes alkalmazása rendkívül hatékony eszköz az adatok tisztítására, validálására és átalakítására. A megfelelő regex kiválasztása és a határolójel helyes értelmezése kulcsfontosságú a sikeres adatfeldolgozáshoz.
Hibák és problémák a határolójelek helytelen használata esetén

A határolójelek helytelen használata komoly problémákat okozhat az adatfeldolgozás során. Ha a határolójel nem megfelelő, a program nem tudja helyesen értelmezni az adatokat, ami hibás eredményekhez vezethet.
Például, egy CSV fájlban a vessző (,) a leggyakoribb határolójel. Ha egy mezőben is szerepel vessző, de nincs megfelelően kezelve (pl. idézőjelekkel), akkor a program két külön mezőnek fogja értelmezni a valójában egy mezőbe tartozó adatot.
Ez adatvesztéshez, félreértelmezéshez és a feldolgozási folyamat teljes összeomlásához vezethet.
További problémák:
- Adatkorrupció: A rosszul értelmezett adatok helytelenül kerülnek tárolásra, ami hosszú távon is káros lehet.
- Feldolgozási hibák: A program váratlanul leállhat, vagy hibás műveleteket végezhet.
- Biztonsági kockázatok: Bizonyos esetekben a rosszul kezelt határolójelek lehetővé tehetik a kódinjektálást, ami súlyos biztonsági réseket eredményezhet.
A határolójelek helytelen használata nem csak technikai problémákat okozhat, hanem üzleti szempontból is jelentős károkat okozhat, például hibás jelentések, rossz döntések és elégedetlen ügyfelek formájában.
A határolójelek biztonsági vonatkozásai: SQL injection és más támadások
A határolójelek, bár az adatfeldolgozás alapvető elemei, komoly biztonsági kockázatokat is hordoznak magukban. A nem megfelelő kezelésük sebezhetővé teheti a rendszereket különböző támadásokkal szemben.
Az egyik leggyakoribb probléma az SQL injection. Ha egy felhasználó által bevitt adatot, amely határolójeleket (például aposztrófokat) tartalmaz, közvetlenül beillesztik egy SQL lekérdezésbe, a támadó képes lehet a lekérdezés szerkezetének megváltoztatására. Ezáltal érzékeny adatokhoz férhet hozzá, módosíthatja azokat, vagy akár törölheti is őket.
A határolójelek helytelen kezelése egyenes út a biztonsági incidensekhez.
Más támadások is kihasználhatják a gyenge határolójel-kezelést. Például, a Cross-Site Scripting (XSS) támadások során a támadó rosszindulatú szkripteket injektál a weboldalra, amelyek a felhasználók böngészőjében futnak le. Ha a bemeneti adatokban szereplő HTML tagek (például a <script> tag) nincsenek megfelelően kódolva vagy szűrve, a támadó képes lehet XSS támadások indítására.
A védekezés kulcsa a megfelelő validálás és kódolás. Minden felhasználó által bevitt adatot ellenőrizni kell, hogy nem tartalmaz-e rosszindulatú karaktereket vagy kódokat. A határolójeleket megfelelően kell kódolni (például HTML entitásokká alakítani), mielőtt azokat adatbázisba mentenénk vagy a weboldalon megjelenítenénk. Emellett a paraméterezett lekérdezések használata is hatékonyan védi az adatbázist az SQL injection támadásoktól, mivel a felhasználó által bevitt adatokat külön kezeli a lekérdezés szerkezetétől.
Határolójelek kezelése különböző operációs rendszerekben: Windows, Linux, macOS
A határolójelek, mint például a vessző (,) vagy pontosvessző (;), kulcsszerepet játszanak az adatfeldolgozásban, különösen a strukturált adatok, mint a CSV fájlok kezelésében. Azonban a különböző operációs rendszerek eltérően kezelhetik ezeket, ami kompatibilitási problémákhoz vezethet.
Windows operációs rendszerekben gyakran találkozunk a vesszővel (,) mint határolójel, de a listaelválasztó beállítások befolyásolhatják ezt. A Linux rendszerekben a vessző és a pontosvessző is elterjedt, de a pontosvessző használata gyakran előnyben részesül a lokalizációs problémák elkerülése érdekében. macOS rendszerekben a helyzet hasonló a Linuxhoz, a rendszer beállításai itt is fontosak a helyes értelmezéshez.
A fájlok közötti átjárhatóság érdekében kritikus, hogy tisztában legyünk azzal, melyik operációs rendszeren milyen határolójelet használunk.
A helytelenül beállított vagy értelmezett határolójelek adatvesztéshez, vagy a programok hibás működéséhez vezethetnek. Ezért adatfeldolgozás során mindig ellenőrizzük a beállításokat, és szükség esetén konvertáljuk a fájlokat a megfelelő formátumra. Például, egy Linux alatt létrehozott, pontosvesszővel tagolt CSV fájl hibásan jelenhet meg Windows alatt, ha a listaelválasztó vesszőre van állítva.
A határolójelek nemzetközi vonatkozásai: karakterkódolások és a határolójelek ábrázolása
A határolójelek nemzetközi vonatkozásai szorosan összefüggnek a karakterkódolásokkal. Egy adott karakterkódolás, mint például az UTF-8, meghatározza, hogy a különböző határolójeleket milyen bájtsorozatok reprezentálják. Ez kritikus fontosságú a nemzetközi adatcsere során, ahol a különböző rendszerek eltérő kódolásokat használhatnak.
Például, a CSV fájlok gyakran használnak vesszőt (,) vagy pontosvesszőt (;) határolójelként. Azonban, ha egy rendszer ISO-8859-1 kódolást használ, míg a másik UTF-8-at, akkor a határolójel helyes értelmezése problémákba ütközhet, különösen ha a szövegben más, nem ASCII karakterek is előfordulnak.
A határolójelek helyes ábrázolása és értelmezése elengedhetetlen az adatok integritásának megőrzéséhez és a különböző rendszerek közötti zökkenőmentes kommunikációhoz.
A különböző operációs rendszerek is eltérő módon kezelhetik a szövegfájlokban használt sorvége jeleket (például CRLF Windows alatt, LF Unix alatt), ami szintén problémákat okozhat az adatok feldolgozása során. Ezért fontos, hogy a szoftverek képesek legyenek a karakterkódolások automatikus felismerésére és a különböző sorvége jelek helyes kezelésére.
A programozási nyelvek és adatbázisok általában biztosítanak eszközöket a karakterkódolások kezelésére, de a fejlesztőknek tisztában kell lenniük a lehetséges problémákkal és a megfelelő megoldásokkal.
Határolójelek a JSON (JavaScript Object Notation) formátumban
A JSON (JavaScript Object Notation) egy széles körben használt, könnyűsúlyú adatformátum, mely az adatcserére specializálódott. A JSON határolójelek nélkülözhetetlenek az adatok strukturált tárolásához és értelmezéséhez. Ezek a jelek teszik lehetővé a JSON-fájlokban található adatok pontos felosztását és hierarchikus elrendezését.
A JSON-ban a legfontosabb határolójelek a következők:
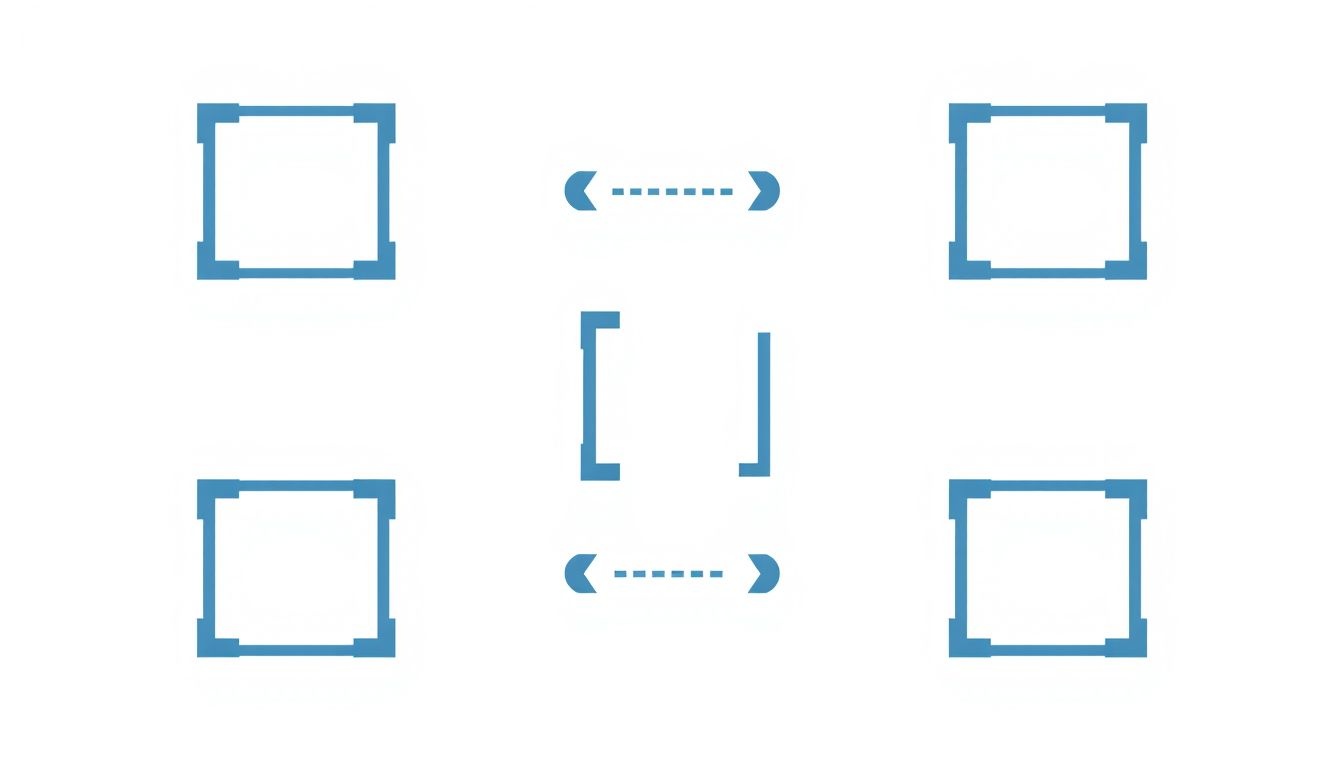
- { }: Objektumok határolására szolgál. Az objektum kulcs-érték párok halmaza.
- [ ]: Tömbök határolására szolgál. A tömb elemek rendezett listája.
- :: A kulcs és érték között használatos egy objektumon belül.
- ,: Az elemek elválasztására szolgál objektumokon belül (kulcs-érték párok között) és tömbökben (elemek között).
- ” „: A kulcsok és szöveges értékek (stringek) határolására szolgál.
Például, egy JSON objektum, amely egy személy adatait tárolja, így nézhet ki:
{
"nev": "Kovács János",
"eletkor": 30,
"varos": "Budapest",
"hobbi": ["olvasás", "futás", "utazás"]
}
Ebben a példában a { } jelöli az objektumot, a "nev", "eletkor", "varos" és "hobbi" a kulcsok, a : választja el a kulcsokat az értékektől, a , választja el a kulcs-érték párokat, és a [ ] határolja a hobbi tömböt.
A határolójelek helyes használata kulcsfontosságú a JSON-fájlok érvényességéhez és az adatok pontos feldolgozásához.
A hiányzó, vagy hibásan elhelyezett határolójelek érvénytelen JSON-t eredményeznek, ami problémákat okozhat az adatok beolvasásában és feldolgozásában. A JSON parserek szigorúan ellenőrzik ezeket a jeleket, és hibát jeleznek, ha valami nem megfelelő.
A JSON formátum egyszerűsége és egyértelműsége nagymértékben köszönhető a jól definiált és következetesen használt határolójeleknek.
Határolójelek az XML (Extensible Markup Language) formátumban
Az XML (Extensible Markup Language) formátumban a határolójelek kulcsfontosságú szerepet töltenek be az adatok strukturálásában és értelmezésében. Ezek a jelek határozzák meg az elemek kezdetét és végét, attribútumokat, valamint a szöveges tartalmat.
A leggyakoribb határolójelek az XML-ben a nyitó (<) és záró (>) kapcsos zárójelek. Ezek a jelek jelölik az elemeket, például a <nev> és </nev> tagek egy „nev” nevű elemet határolnak közre. Az elemek egymásba ágyazhatók, így hierarchikus struktúrát hozva létre.
Az XML határolójelek nélkülözhetetlenek az adatok helyes értelmezéséhez és feldolgozásához.
Az XML attribútumok értékét általában idézőjelek (” vagy ‘) közé kell tenni. Például: <termek szam=”10″>.
Speciális esetekben, például a CDATA szekciókban, a <![CDATA[ és ]]> határolójelek használatosak. Ezek lehetővé teszik, hogy a szövegben szereplő speciális karakterek, mint a < és >, ne legyenek értelmezve XML tagekként.
Az XML szabvány szigorúan meghatározza a határolójelek használatát. A helytelenül használt vagy hiányzó határolójelek érvénytelen XML dokumentumhoz vezethetnek, ami megakadályozza az adatok helyes feldolgozását. Ezért a szabványok következetes betartása elengedhetetlen.
Határolójelek a naplófájlokban és azok elemzése
A naplófájlok elemzése során a határolójelek kritikus szerepet játszanak az adatok strukturálásában és feldolgozásában. Ezek a speciális karakterek, mint például a vessző (,), pontosvessző (;), tabulátor (\t) vagy szóköz, elkülönítik az egyes adatmezőket a naplóbejegyzéseken belül.
A határolójelek használata lehetővé teszi a naplófájlok automatikus feldolgozását és elemzését különböző szoftverekkel és szkriptekkel. Például, egy vesszővel tagolt (CSV) naplófájl könnyen importálható táblázatkezelő programokba, ahol az adatok rendezhetők, szűrhetők és vizualizálhatók.
A határolójelek konzisztens használata elengedhetetlen a naplófájlok helyes értelmezéséhez.
Ha a határolójelek nem megfelelően vannak definiálva vagy következetlenül vannak használva, az adatvesztéshez vagy hibás eredményekhez vezethet. Ezért fontos, hogy a naplófájlok formátuma pontosan dokumentált legyen, és az elemző eszközök megfelelően konfigurálva legyenek a megfelelő határolójelek felismerésére.
Például, egy web szerver naplófájl tartalmazhat időbélyeget, IP címet, kéréstípusát és válaszkódot, mindegyiket egy-egy szóközzel elválasztva. Ezen adatok elemzéséhez egy szkript használhatja a szóközt, mint határolójelet, hogy különálló mezőkként kezelje az információkat. A helyes határolójel kiválasztása a naplófájl formátumától függ.
A határolójelek automatikus detektálása és kezelése
A határolójelek nélkülözhetetlenek az adatfeldolgozásban, lehetővé téve az adatok strukturált tárolását és feldolgozását. Gyakran előfordul, hogy az adatforrás nem tartalmaz explicit információt a használt határolójelről. Ilyenkor jön képbe a határolójelek automatikus detektálása.
Az automatikus detektálás során algoritmusok elemzik az adatállományt, hogy azonosítsák a legvalószínűbb határolójelet. Ez a folyamat statisztikai elemzésen alapulhat, például a leggyakrabban előforduló karakter keresésén, amely nem része az adatoknak.
A detektálás pontossága kulcsfontosságú, hiszen egy hibásan azonosított határolójel helytelen adatokhoz vezethet. A komplexebb algoritmusok figyelembe veszik az adatok típusát és a lehetséges határolójelek kontextusát is.
A sikeres automatikus detektálás alapja a megfelelő algoritmus kiválasztása és az adatok alapos előfeldolgozása.
A határolójelek kezelése magában foglalja a detektálást, a validálást és az adatok megfelelő formátumba alakítását. A validálás során ellenőrizzük, hogy a detektált határolójel valóban szétválasztja-e az adatokat a várt módon. Ha a validálás sikertelen, a rendszer alternatív határolójeleket próbálhat ki, vagy manuális beavatkozást igényelhet.
A modern adatfeldolgozó rendszerek gyakran tartalmaznak beépített funkciókat a határolójelek automatikus detektálására és kezelésére. Ezek a funkciók jelentősen leegyszerűsítik az adatok importálását és feldolgozását, különösen nagy mennyiségű, ismeretlen formátumú adat esetén.